pandas-stubs
 pandas-stubs copied to clipboard
pandas-stubs copied to clipboard
BUG: df.groupby(col, as_index=False).value_counts() returns a DataFrame but is annotated as Series
Describe the bug
Using
df = pd.DataFrame({"a": [1, 2, 3], "b": 1})
x: pd.DataFrame = df.groupby("a", as_index=False).value_counts()
raises an error, because mypy thinks the return is a Series
Incompatible types in assignment (expression has type "Series[int]", variable has type "DataFrame") [assignment]
To Reproduce
- Provide a minimal runnable
pandasexample that is not properly checked by the stubs. - Indicate which type checker you are using (
mypyorpyright). - Show the error message received from that type checker while checking your example.
df = pd.DataFrame({"a": [1, 2, 3], "b": 1})
x: pd.DataFrame = df.groupby("a", as_index=False).value_counts()
In theory this should be ok, but not sure if this as_index=False can be typed?
Please complete the following information:
- OS: ubuntu
- OS Version 22.04
- python version 3.10
- version of type checker mypy 0.971
- version of installed
pandas-stubsnewest 20220815
Additional context Add any other context about the problem here.
Similar issue with df.groupby('a",as_index=False).size(), which returns a DataFrame, but we type it as Series
Two options here, one easy and one hard:
- Easy way - just have
value_counts()typed asFrameOrSeriesUnionas the result. - Hard way (and may not be possible) - make
DataFrameGroupByandSeriesGroupByGeneric with a typing parameter that indices whetherSeriesorDataFrameshould be returned, based on the value ofis_indexinDataFrame.groupby()andSeries.groupby(). Requires overloads there, and careful typing.
Regarding (2), I recently did something like this to handle the case of Series.str.split() where the parameter expand changes the nature of the result.
I think as_index is kind of special and changes the return type of many functions, so there is also a third option of breaking SeriesGroupBy and DataFrameGroupBy into 2 different classes depending on as_index and overloading the various functions which return them.
there is also a third option of breaking
SeriesGroupByandDataFrameGroupByinto 2 different classes depending onas_indexand overloading the various functions which return them.
This is similar to my (2), but instead of using 4 total classes, we'd have 2 classes, each generic, and then the "parameter" to the generic class would indicate the return type to use based on as_index. Need to explore both approaches.
I'm facing a case that type of df.groupby("col1")["col2"].value_counts() (with default of as_index=True) is DataFrame.
Tracing to the type definitions this call is using SeriesGroupBy.value_counts().
I also checked in REPL that the return is definitely Series (with MultiIndex).
It seems to me that the definition look up is assuming as_index=False. Or is it something I do that confused it?
I'm facing a case that type of
df.groupby("col1")["col2"].value_counts()(with default ofas_index=True) isDataFrame. Tracing to the type definitions this call is usingSeriesGroupBy.value_counts(). I also checked in REPL that the return is definitelySeries(withMultiIndex).It seems to me that the definition look up is assuming
as_index=False. Or is it something I do that confused it?
Can you provide a complete example?
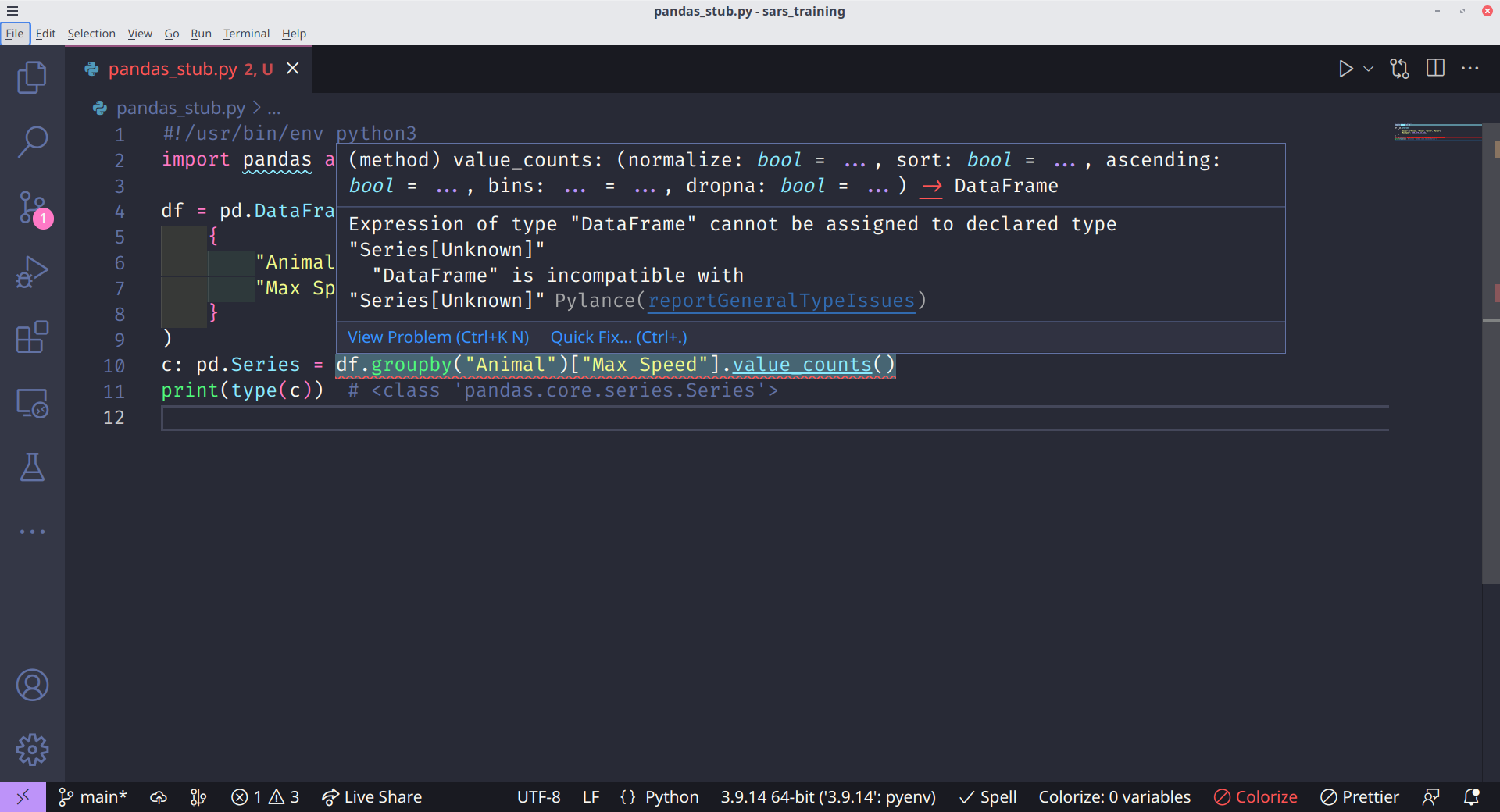
#!/usr/bin/env python3
import pandas as pd
df = pd.DataFrame(
{
"Animal": ["Falcon", "Falcon", "Parrot", "Parrot"],
"Max Speed": [380, 370, 24, 26],
}
)
c: pd.Series = df.groupby("Animal")["Max Speed"].value_counts()
print(type(c)) # <class 'pandas.core.series.Series'>
print(c.index)
print(c)
I concur with @amotzop's suggested solution.
'm facing a case that type of
df.groupby("col1")["col2"].value_counts()(with default ofas_index=True) isDataFrame. Tracing to the type definitions this call is usingSeriesGroupBy.value_counts(). I also checked in REPL that the return is definitelySeries(withMultiIndex).
This is a separate issue from the as_index=False issue, so created #442
Thanks, this issues was the closest I got from Googling so I chime in here. :stuck_out_tongue_closed_eyes:
@Dr-Irv looks like no work has been pushed on this and I'm quite keen on taking it.
I have encountered this issue from both the DataFrameGroupBy side as described above and the SeriesGroupBy as in 553.
I checked what you did on Series.str.split as you mention above, seems like the most elegant way to tackle this.
I will try to send a PR in the coming week.
@Dr-Irv looks like no work has been pushed on this and I'm quite keen on taking it.
I have encountered this issue from both the DataFrameGroupBy side as described above and the SeriesGroupBy as in 553.
I checked what you did on Series.str.split as you mention above, seems like the most elegant way to tackle this.
I will try to send a PR in the coming week.
Great!
Just note that since I suggested the solution, the groupby definitions in series.pyi and frame.pyi have been split into 8 overloads each, dependent on the type of the by argument. So you'd end up with 16 overloads now, corresponding to the various combinations of the by and as_index arguments, and both DataFrameGroupBy and SeriesGroupBy would each add a new argument to the Generic declaration that would correspond to the return type needed for value_counts() (and size(), and maybe other methods as well).
It becomes a bit similar to what is in pandas-stubs/core/indexes/accessors.pyi, which is used by Series.dt, Timestamp, DatetimeIndex and other places to have a consistent way of defining various time-related methods.