opengrok
 opengrok copied to clipboard
opengrok copied to clipboard
Negative numbers shown for #Lines and LOC if directory contains file what was excluded
Negative numbers shown for #Lines and LOC if directory contains file what was excluded.
Opengrok 1.7.34 & 1.7.31
Hi I have just noticed same issue with OG 1.7.35. In the directory where negative number appears for the first time (I mean at deepest level), files that are skipped are .gz files.
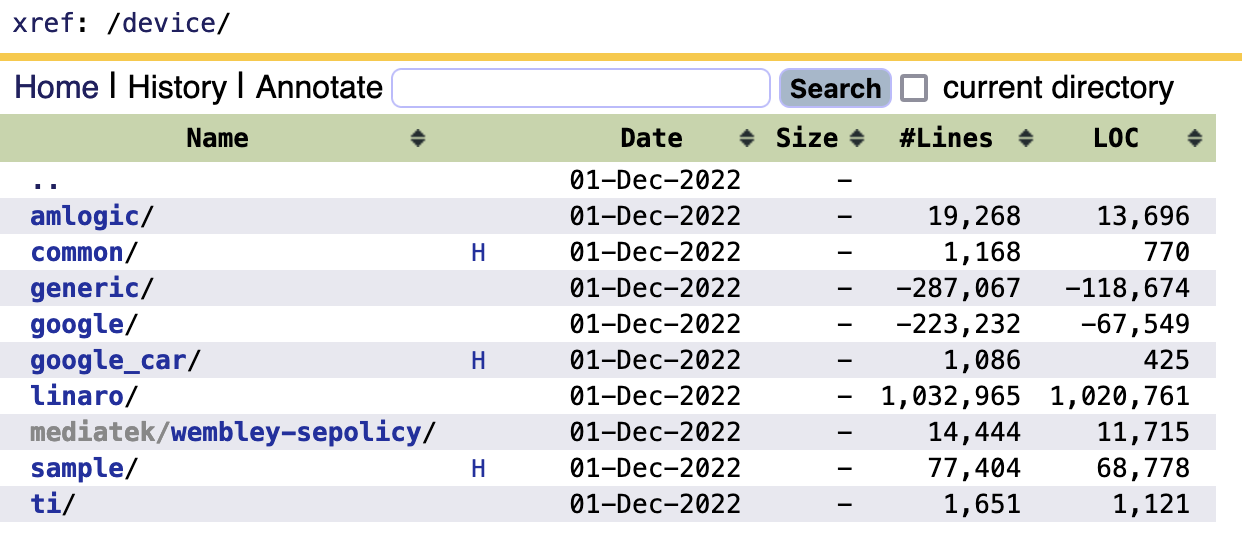
Just an FYI,
The negative value is caused by the deleted documents that are still in the Lucene index (multi segments mode). When removing stale files, OG only checks the UID (however, the document might be empty as it was deleted during the previous update of the index). As a result, the size of the parent directory subtracts the size of the modified file over an over again, eventually becomes negative. see https://github.com/oracle/opengrok/blob/d23c7bd6df3698a7c251025721eb4e11932e1cae/opengrok-indexer/src/main/java/org/opengrok/indexer/index/IndexDatabase.java#L1619
"--reduceSegmentCount" can trigger a "forceMerge" to clean up the empty documents and stale indexes from Lucene database. It seems this option is mandatory (at least for me).
Hope the above information helps.
Hi
I don't know Lucene.
Do you think that the issue related to empty/useless documents not being cleaned could explain too that searches sometimes report several times the exact same line in a file when the indexing option --reduceSegmentCout is not used?
Do you think that the issue related to empty/useless documents not being cleaned could explain too that searches sometimes report several times the exact same line in a file when the indexing option --reduceSegmentCout is not used?
Such behavior would not surprise me, however I cannot replicate this with a repository exhibiting the negative LOC counts that has index with multiple segments and pending deleted documents. How do the search results look exactly ? And what are the queries triggering such results ? Does this also happen when you search via the search API ?
I am also unable to replicate this issue (otherwise I would have created a ticket). It happens totally randomly, very likely depending on what new commits are changing in the code and what the user is searching into this part of the code.
At the moment, I am focusing on whether the usage of --reduceSegmentCout solves the issue. On one of our instance (running 1.7.35), issue occured while the option was not set. User reported it to me. It happened when searching a repository heavily used and searched. So, I deleted the index. Then I updated my indexing flow adding the option. And I am now waiting the user faces the issue again. This was done on Jan 3rd. Indexing is run nightly. At least one search into the repo is done daily. Still no occurence.
It is happening whatever the search type (UI and API) despite most users search with UI. Workaround is to delete the index of the project. Once regenerated, the issue is no more occuring at least for some time.
Example of issue:
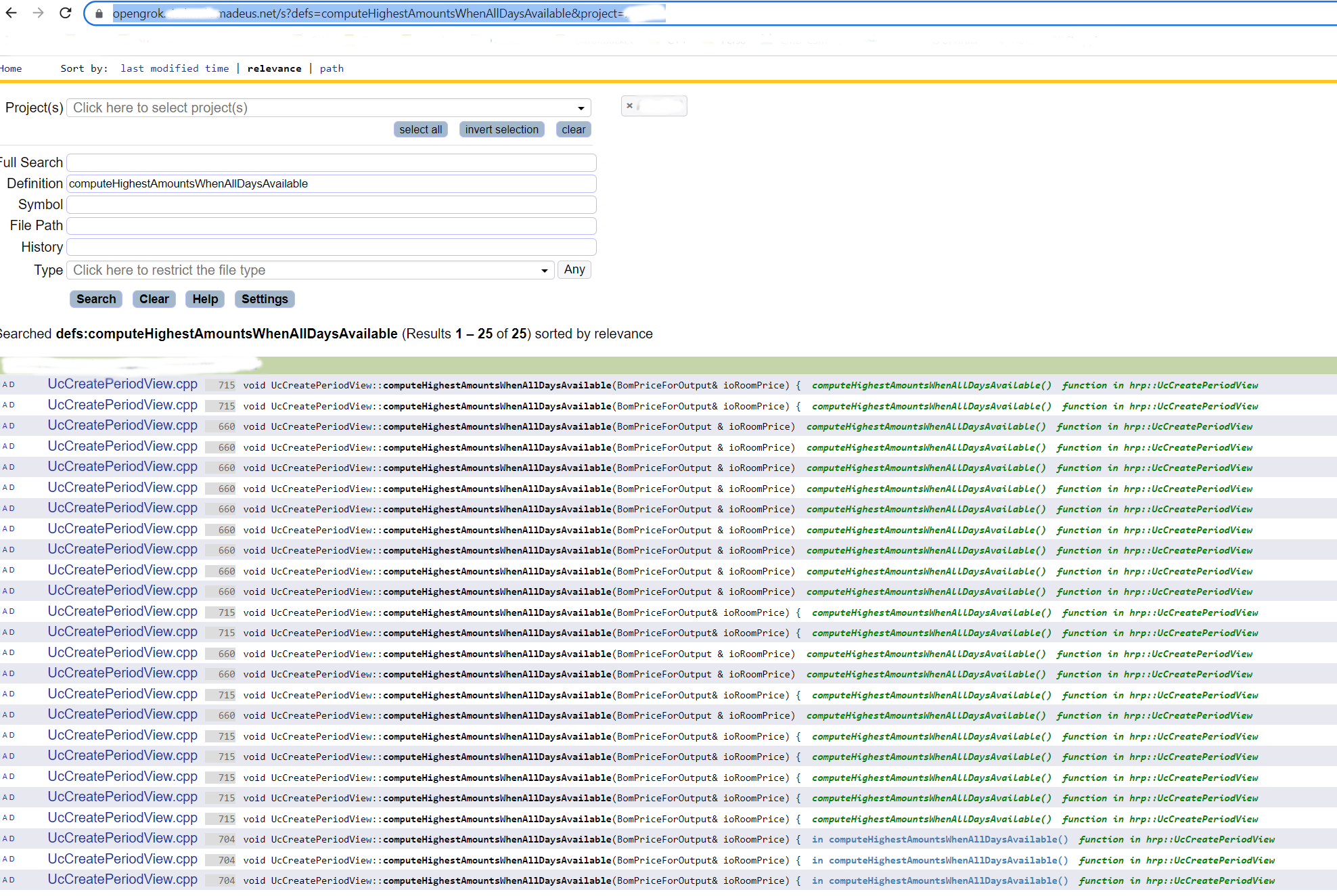
I have just talked to my user. He has confirmed that no occurence has happened since indexing flow is optimizing the indexes. OpenGrok is a tool him and his colleagues are using a lot, searching code very often.
The issue has started to occur once I have upgraded OG from 1.7.19 to 1.7.35.
What does the repository history of the UcCreatePeriodView.cpp file look like ? Lots of updates, I guess ?
Yes. More than 47k commits. The commit tree for the branch is indeed quite complex. The file itself has lots of commits.
git log --oneline UcCreatePeriodView.cpp | wc -l
141
Looking at OG history page for the file, I discover that 243 commits are reported on 10 pages, with again dups.
So, my workaround to remove dups should target project index but also project historycache pages :-(
I've been investigating this for bunch of days. There are 3 issues:
- index traversal using the document uid (
QueryBuilder.U) visits deleted documents in multi-segment index. This is causing the negative LOC counts by callingfileRemove()for the same path repeatedly. There are ways how to identify which documents are deleted (using Lucene'sMultiBits.getLiveDocs(indexReader)) and avoid those during the traversal. - corrupted history cache. I believe this sort of shares the cause with the above issue, i.e. has to do with how the traversal is done, perhaps a side effect of how the
IndexDownArgsis accumulated. Maybe change theIndexDownArgs.worksfrom list to set ? - repeated paths in search results. By far, this is the most tricky one I think, also because I cannot reproduce it yet. Using similar technique as for the index traversal would not work because of search result pagination - even if the deleted documents were detected before the search (caching them for given
IndexSearcherinstance perhaps), it would collide with the slider construction (usingsearchHelper.getTotalHits()so the total hit count reporting would be wrong unless the whole set of results is traversed which is would probably hurt performance badly) and could actually still produce deleted documents in the search results (filtering out deleted documents vs. page breaks). Someone on SO said that "IndexSearcher.search should not return deleted documents" and hinted that this is caused by how documentFields are setup. My wild guess is that this could be caused by theQueryBuilder.PATHfield is being setup. It isTextFieldwithsetTokenized(true),setIndexOptions(IndexOptions.DOCS_AND_FREQS_AND_POSITIONS),setStored(true). I wonder whether changing the index options to justDOCSwould change anything but again with no reproduction scenario this is just an uneducated guess.
Of course, there is still the possibility of reverting the #3983 change and make the segment reduction to 1 implicit once again.
Thanks @vladak for the analysis and status. Good to read issue #1 could be fixed, and eventually #2 too. For #3, maybe you could invert the default coming from #3983, ensuring by default Lucene index is optimized and letting an option to not optimize it.
I'd say it is all or nothing. Either multi segment indexes work in all aspects of the indexer and webapp, or single segment will have to be forced.
It seems I managed to reproduce the case number 3. Previously, the approach I took was a carefully staged small sequence of changes (eventually destined to be a test case) over small set of files combined with:
iwc.setMergePolicy(NoMergePolicy.INSTANCE);
iwc.setMergeScheduler(NoMergeScheduler.INSTANCE);
done in IndexDatabase#update() however that did not always lead to an index with deleted documents (which by itself is interesting; I also used iwc.setInfoStream(System.out); however I am not used to reading Lucene debug messages so cannot really tell what is and what is not going on).
Then I took more brute force approach: using the OpenGrok Git repository, I checked out a historical changeset and then started checking out the repository one changeset at a time and running the indexer (unchanged 1.7.24, so no extra IndexWriter changes) until it reached the HEAD. Eventually it arrived to a point when the following code (which is a subset of what is normally used when performing search via the UI):
// Try search
IndexSearcher searcher = new IndexSearcher(indexReader);
Query query = new CustomQueryParser("defs").parse("xrefFile");
TopFieldDocs fdocs = searcher.search(query, 2048, Sort.RELEVANCE);
long totalHits = fdocs.totalHits.value;
ScoreDoc[] hits = fdocs.scoreDocs;
for (int i = 0; i < totalHits; i++) {
int docId = hits[i].doc;
Document doc = searcher.doc(docId);
String rpath = doc.get(QueryBuilder.PATH);
if (rpath == null) {
continue;
}
System.out.println("path: " + rpath);
}
actually reported hundreds of documents with the same path (.../IndexDatabase.java in this case) in the results.
In the back of my mind I still reserve some probability that this might not be fixable with how the index fields are setup - the "u" field being the central point while its values not being unique in terms (sic!) of the paths embedded therein, at least in the multi-segment index, that is.
Looking into the search results, all the returned documents are actually live, i.e. not deleted. In the index there was just one deleted document with the IndexDatabase.java path and it was not part of the search results. So, after all it seems true that "IndexSearcher.search should not return deleted documents" and therefore we do not have to worry about the case number 3 above as the existence of these documents in the index is likely related to the way the uid traversal got broken (or it might be a pre-existing bug - this reproduction scenario is based on Git repository so the quite recently added history based reindex is used). Anyhow, by fixing the traversal, there should be at most one live document for each path in the index.
Once you have a fix, I can test a tar.gz quickly. I have a project that very often faces the issue of dups.
I wondered how the multiple live documents matching single path come into existence. By using NoMerge index writer settings and carefully stepping through certain changesets in OpenGrok Git repository history for a sequence of indexer runs, I was able to replicate the situation. Here's what happens:
At certain point, a file (in my case I used IndexDatabase.java) is updated and the result is deleted document and new document. Due to the segment merge settings, the deleted document stays in the index. Given this is Git repository, history based reindex is used and therefore IndexDatabase#processFileIncremental() is called. When traversing the index, unlike its sibling processFile() (used for directory traversal method of indexing), this method does not use full uid comparison and stops the uid traversal when it encounters path ordered equal or higher than the current term: https://github.com/oracle/opengrok/blob/56c26420273d8804b01b4c4de87d0e0fb27a8fcf/opengrok-indexer/src/main/java/org/opengrok/indexer/index/IndexDatabase.java#L1529-L1533
Given the deleted document is the first one visited while during the traversal (due to the uid ordering), the code enters this block: https://github.com/oracle/opengrok/blob/56c26420273d8804b01b4c4de87d0e0fb27a8fcf/opengrok-indexer/src/main/java/org/opengrok/indexer/index/IndexDatabase.java#L1556-L1569
Specifically, it will try to delete the document matching the uidIter in removeFileDocUid(), however that document is already deleted. Then it adds the path to the work args which eventually creates new document and adds it to the index. This is repeated whenever the file in question is updated, leading to the multiple live documents matching the same path.
So, history based reindex leads to the negative LOCs however also causes these extra documents to be added.
Hi @vladak,
Would you have any ETA for the fix of this issue?
I spent a week writing the tests for my changes and they are almost done but then had to stop working for a bit. Once I return back to work, it will be a matter of days before I submit a PR.
Super, thanks for the fast update! Hope you will come back to work quickly ;-)
Many thanks @vladak for the fix! As soon as the new release is done, I will install it on my UAT envs and will report feedback.