openvino
 openvino copied to clipboard
openvino copied to clipboard
[Bug] dynamic input and output
System information (version)
- OpenVINO=> :2022.1
- Operating System / Platform => :win10
- Problem classification => :dynamic input
I have a onnx model, if I transform it with static shape, it can inference successful.
But when I transform onnx with dynamic shape, ant transform it to ir model. And use ov runtime reshape the model shape with static shape. and get the model output shape. the output still is dynamic shape, This leads to inference crash. is it normal? Or is there anything else I need to do?
I did the following experiment(the model has 5 output): First, the bachsize dim is dynamic, And use ov runtime reshape the model shape with static shape. All the model output's batchsize dim are dynamic. Second, the bachsize dim is static, the other dim is dynamic. And use ov runtime reshape the model shape with static shape. All the model output's batchsize dim are still dynamic. Third, the w,h is dynamic. And use ov runtime reshape the model shape with static shape. Part of the output's W,H can be automatically computed to obtain the correct W,H. But the partial output WH is still dynamic.
Is the above phenomenon normal? Is there a demo provided with dynamic input and output?
@wang7393 may I know what dynamic shape values are you trying to feed to your model? I can see most of them are set to unknown (?) which I believe you tried to make them dynamic.

You need to feed the shape using parameter -shape[N,C,H,W] when you infer the dynamic model with OV For example: Conversion command: mo -m model.onnx --input_shape [?,3,100,12] Inferencing command: benchmark_app -m dynamicmodel.xml -shape [10,3,100,12] OR benchmark_app -m dynamicmodel.xml -shape [5,3,100,12] etc
@Iffa-Meah src-r4i:{ 1, 3, 270, 480 }, { 1, 16, 68, 120 }, { 1, 20, 34, 60 }, { 1, 40, 17, 30 }, { 1, 64, 9, 15 } downsample_ratio: 0.5 seg-r4o: {1,1,135,240}, { 1, 16, 68, 120 }, { 1, 20, 34, 60 }, { 1, 40, 17, 30 }, { 1, 64, 9, 15 } benchmark_app -shape, multi-input? how to set it ?
@wang7393 from the inferencing result I attached above, I can see that you statically set some values (I believe that is colour channel if following the NCHW order) but they are inconsistent. For C, usually, 1 for grayscale image and 3 for colour image (RGB) are used.
This is one of the reason OpenVINO throws the error "Argument shapes are inconsistent". They need to have the same rank and equal dimensions except on concat axis.
If you are trying to reduce the number of parameters in your network, it is recommended to implement pooling layer in your network itself instead of feeding those values during inferencing.
@Iffa-Meah sorry, I do not understand it. My model has a total of six inputs (Five of which: NCHW, and another: one dims), one is the color image input (C :3), and the other four are non-image inputs, where C is neither 1 nor 3. So what you mean: Openvino dynamic input or output channels must be equal and must be 1 or 3?
we'll get back to you with possible workaround from perspective of OpenVINO
@wang7393 with a model visualizer I can see the OpenVINO IR model with dynamic shapes for input and output with values as follows:
inputs: src: [-1,3,-1,-1] r1i-r4i: [-1,-1,-1,-1] downsample_ratio: [1] outputs: seg: [-1,1,-1,-1] r1o: [-1,16,-1,-1] r2o: [-1,20,-1,-1] r3o: [-1,40,-1,-1] r4o: [-1,64,-1,-1]
For your reference, these are the Model Optimizer command I used to convert the ONNX model to IR.
dynamic shapes: $ mo --input_model epoch-1.onnx --use_new_frontend --input src,r1i,r2i,r3i,r4i,downsample_ratio --output seg,r1o,r2o,r3o,r4o
static shapes: $ mo --input_model epoch-1.onnx --use_new_frontend --input src,r1i,r2i,r3i,r4i,downsample_ratio --output seg,r1o,r2o,r3o,r4o --input_shape [1,3,270,480],[1,16,68,120],[1,20,34,60],[1,40,17,30],[1,64,9,15],[1]
I've taken a look at such shared epoch-1.onnx model and I am able to inference on OpenVINO without issue using the dynamic model with dynamic shapes.
openvino results w/random data (showing seg/r1o outputs, dynamic shapes model):
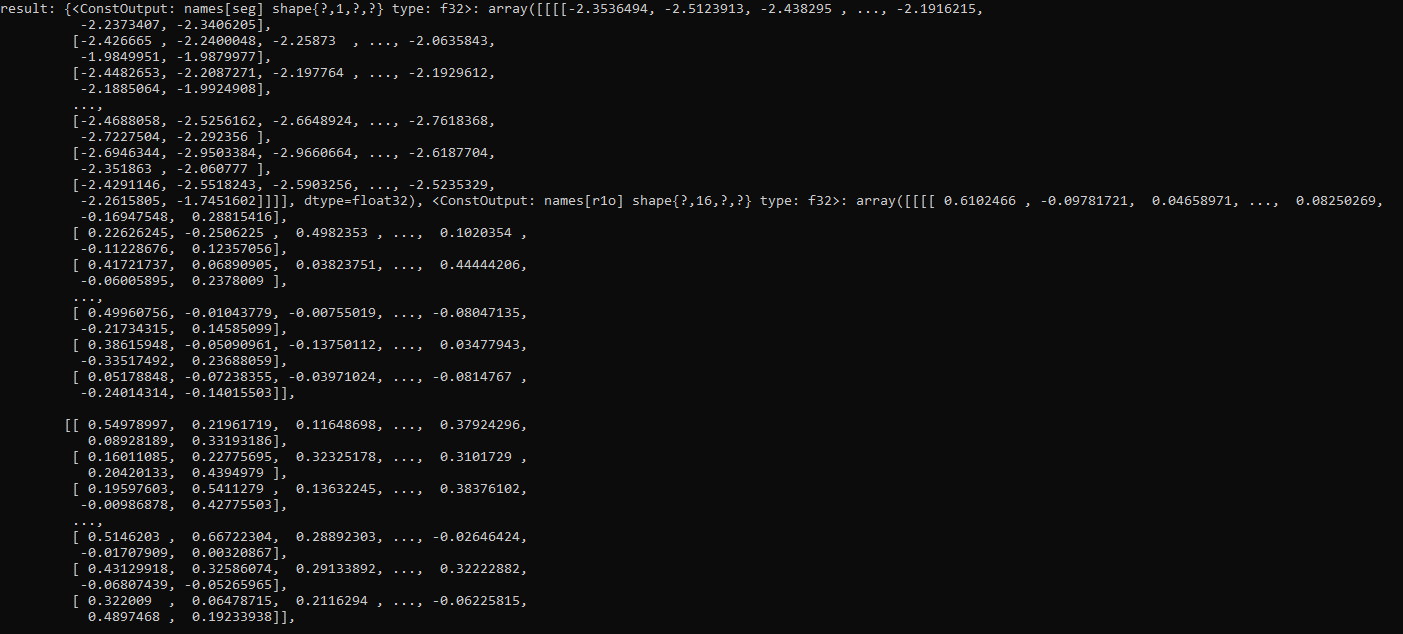
For your reference, I believe output shapes will remain dynamic if that is how you converted the model. The compiled_model.output("output_layer_name").partial_shape call will report dynamic shape, if you want to get the shape of the output data you can try getting the actual data shape (after inference) of the output (ie. with request.get_tensor("seg").data.shape as shown in 2nd line item of screenshot [A] below). If you try to get_shape on a dynamic output you may get ValueError: ValueError: get_shape was called on a descriptor::Tensor with dynamic shape (see screenshot [A] below).
[A]

I am trying to understand how is it in your case that inference is crashing due to dynamic shapes. Is your issue about item no. 3 below, where converting the model to IR using static shapes doesn't translate some outputs with static shapes? How are you converting the ONNX model to IR? How are you running inference (code snippet or sample reproducer)? What input shapes are you passing to the reshape method and are you calling core.compile_model afterwards? Or are you feeding the input data directly to the model?
-
openvino inputs/outputs names and shapes (dynamic):
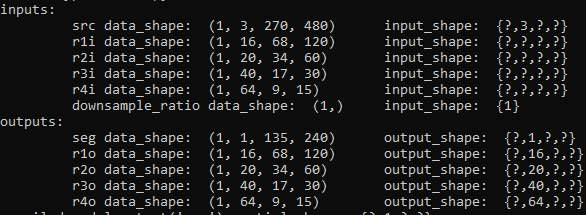
-
openvino inputs/outputs names and shapes (dynamic w/reshape):
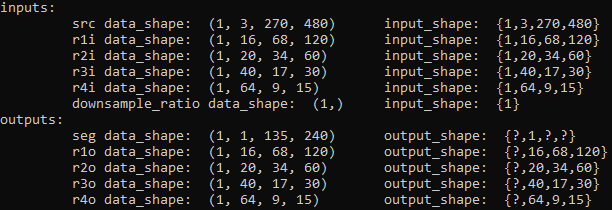
-
openvino inputs/outputs names and shapes (static):
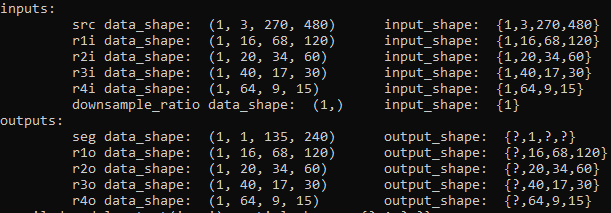
Note: in screenshots above data_shape means shape of data fed into the model and data produced by the model, and input_shape/output_shape means shape of the models' inputs/outputs.
@avitial Thank you for your reply.
I transform the IR model the same way you do.
My code flow:
First: read model and reshape
m_model = core.read_model(model, weights);
map<string, ov::PartialShape> nameToPartShape;
ov::Shape srcShape = { 1, 3, 270, 480 };
ov::PartialShape srcPartShape(srcShape);
nameToPartShape["src"] = srcPartShape;
ov::Shape r4Shape = { 1, 64, 9, 15 };
ov::PartialShape r4iPartShape(r4Shape);
nameToPartShape["r4i"] = r4iPartShape;
m_model->reshape(nameToPartShape);
Second: compile
compile with GPU: compiled_model = core.compile_model(m_model, "GPU"); the fllowing error:
get_shape was called on a descriptor::Tensor with dynamic shape
complie with CPU: compiled_model = core.compile_model(m_model, "CPU"); success
Third: create_infer_request 'm_inferRequest = compiled_model.create_infer_request();'
Fourth: feed input like this
ov::Tensor inputTensor = m_inferRequest.get_tensor("src");
float* blobData = inputTensor.data<float>();
...
ov::Tensor inputTensor = m_inferRequest.get_tensor("downsample_ratio");
float* blobData = inputTensor.data<float>();
blobData[0] = 0.5f;
Five: inference crashed with floowing error
try { m_inferRequest.infer(); } catch (const std::exception& e) { PLOGE << "Infer failed: " << e.what(); return false; }
error: "Infer failed: Check 'false' failed at C:\j\workspace\private-ci\ie\build-windows-vs2019@3\b\repos\openvino\src\plugins\intel_cpu\src\nodes\eltwise.cpp:1853: Can't compute static output shape for Eltwise node with name: 728. Input shapes = ( 0 port = {1, 64, 9, 15}, 1 port = {1, 64, 13, 23}, ). Output shape = ( {1,64,?,?} )"
So, can you compile dynamic input successful with GPU? and how can you inference successful? can you share the sample code?
@wang7393 on my previous test I had inference working with CPU, but the same code for GPU throws Runtime error as you described.
compiled_model = core.compile_model(model, device)
...
RuntimeError: get_shape was called on a descriptor::Tensor with dynamic shape
It seems this is the expected behavior for GPU plugin as based on documentation , GPU plugin supports dynamic shapes for batch dimension only with fixed upper bound. Any other dynamic dimensions are unsupported. Now I am not entirely sure why when converting to IR with input static shapes, the resulting model still has dynamic outputs (seg: [-1,1,-1,-1], r1o[-1,16,68,120], r2o[-1,20,32,60], r3o[-1,40,17,30], r4o[-1,64,9,15]). Are you utilizing or do you plan to use GPU plugin in your case?
This is the Python code snippet I had used to test, you can use it as reference and implement the same on C++ and see if that works for you.
import numpy as np
from openvino.runtime import Core
device = "CPU"
core = Core()
model = core.read_model("epoch-1.xml")
#model.reshape({"src": (1, 3, 270, 480), "r1i": (1, 16, 68, 120), "r2i": (1, 20, 34, 60), "r3i": (1, 40, 17, 30),
# "r4i": (1, 64, 9, 15)})
compiled_model = core.compile_model(model, device)
infer_request = compiled_model.create_infer_request()
request = compiled_model.create_infer_request()
src = np.random.random((1, 3, 270, 480)).astype(np.float32) # generate random data for input
...
...
downsample_ratio = np.array([0.5]).astype(np.float32) # generate data for input
res = request.infer(inputs={"src": src, "r1i": r1i, "r2i": r2i, "r3i": r3i, "r4i": r4i,
"downsample_ratio": downsample_ratio})
print("result: ", res)
@avitial
we will use dynamic input with intel-GPU. Why does Intel-GPU only support batch dimension?
In addition, I ran the following python code, which still gets the same error as c++:
import numpy as np
from openvino.runtime import Core
device = "CPU"
core = Core()
model = core.read_model("epoch-1.xml")
model.reshape({"src": (1, 3, 270, 480), "r1i": (1, 16, 68, 120), "r2i": (1, 20, 34, 60), "r3i": (1, 40, 17, 30), "r4i": (1, 64, 9, 15)})
compiled_model = core.compile_model(model, device)
infer_request = compiled_model.create_infer_request()
request = compiled_model.create_infer_request()
src = np.random.random((1, 3, 270, 480)).astype(np.float32) # generate random data for input
r1i = np.random.random((1, 16, 68, 120)).astype(np.float32) # generate random data for input
r2i = np.random.random((1, 20, 34, 60)).astype(np.float32) # generate random data for input
r3i = np.random.random((1, 40, 17, 30)).astype(np.float32) # generate random data for input
r4i = np.random.random((1, 64, 9, 15)).astype(np.float32) # generate random data for input
downsample_ratio = np.array([0.5]).astype(np.float32) # generate data for input
res = request.infer(inputs={"src": src, "r1i": r1i, "r2i": r2i, "r3i": r3i, "r4i": r4i, "downsample_ratio": downsample_ratio})
print("result: ", res)
the error is :
Traceback (most recent call last):
File ".\rvm.py", line 21, in
we will use dynamic input with intel-GPU. Why does Intel-GPU only support batch dimension?
Work for support of dynamic shapes on Intel GPU plugin is in progress. CC @vladimir-paramuzov
@avitial Sorry, I have solved the problem of dynamic input under CPU, mainly because my model has problems. But there are serious performance issues with dynamic inputs.
The model with static shape's inference time is about 25ms. But the same model with dynamic input(h and w dim)'s inference is about 50ms.
Why is it so slow? Normal? I've tested Tensorrt's dynamic input, and the inference time is no different from the static input.
@wang7393 inference time is no different in my test, for IR models I see around ~19.60 ms for static model, ~19.48 ms with dynamic model and ~20.16 ms with dynamic model and reshape. All tests are using same input shapes filled with random data, for 100 inference iterations and sync API (on i7-8809G @ 3.10GHz). How are you calculating the inference time? What inference time are you expecting to get and compares to original framework? What type of CPU are you using? Inference times may vary depending on the hardware used so it may be expected in your case, although I'd expect to see similar times with static vs dynamic as seen in my tests.
_start = time.time()
res = infer_request.infer(inputs={"src": src, "r1i": r1i, "r2i": r2i, "r3i": r3i, "r4i": r4i,
"downsample_ratio": downsample_ratio})
_end = time.time()
@avitial I measure time the same way you do. Test 1: conver onnx static model to ir static model, the inference tima is about 20ms. Test 2: convert onnx dynamic model to ir static model, the inference time is about 40ms. (mo --input_model epoch-0-dynamic.onnx --input_shape xxx) Test 3: convert onnx dynamic model to ir dynamic model, the inference tima is about 40ms.
the onnx model as fllows: epoch-0-dynamic.zip epoch-0-static.zip
the dynamic shape param:
src = np.random.random((1, 3, 504, 896)).astype(np.float32) # generate random data for input
r1i = np.random.random((1, 16, 95, 168)).astype(np.float32) # generate random data for input
r2i = np.random.random((1, 20, 48, 84)).astype(np.float32) # generate random data for input
r3i = np.random.random((1, 40, 24, 42)).astype(np.float32) # generate random data for input
r4i = np.random.random((1, 64, 12, 21)).astype(np.float32) # generate random data for input
downsample_ratio = np.array([0.375]).astype(np.float32) # generate data for input
so, Why is there such a difference between test1 and test2?
@wang7393 I am seeing similar results as you based on the provided models. The epoch-0-dynamic model with dynamic vs static shapes (Model Optimizer conversion) has very similar inference times (see below). However, the epoch-0-static seems to have better inference times but its unclear what may cause this difference. I see the epoch-0-static model doesn't have the downsample_ratio input. Have you performed the same three tests in the original framework with exported ONNX and are the results the same?
epoch-0-dynamic.zip: 37.50 ms inputs: src data_shape: (1, 3, 504, 896) input_shape: {1,3,?,?} r1i data_shape: (1, 16, 95, 168) input_shape: {1,16,?,?} r2i data_shape: (1, 20, 48, 84) input_shape: {1,20,?,?} r3i data_shape: (1, 40, 24, 42) input_shape: {1,40,?,?} r4i data_shape: (1, 64, 12, 21) input_shape: {1,64,?,?} downsample_ratio data_shape: (1,) input_shape: {1} outputs: seg data_shape: (1, 1, 189, 336) output_shape: {?,1,?,?} r1o data_shape: (1, 16, 95, 168) output_shape: {?,16,?,?} r2o data_shape: (1, 20, 48, 84) output_shape: {?,20,?,?} r3o data_shape: (1, 40, 24, 42) output_shape: {?,40,?,?} r4o data_shape: (1, 64, 12, 21) output_shape: {?,64,?,?}
epoch-0-dynamic.zip with static shape: 37.15 ms inputs: src data_shape: (1, 3, 504, 896) input_shape: {1,3,504,896} r1i data_shape: (1, 16, 95, 168) input_shape: {1,16,95,168} r2i data_shape: (1, 20, 48, 84) input_shape: {1,20,48,84} r3i data_shape: (1, 40, 24, 42) input_shape: {1,40,24,42} r4i data_shape: (1, 64, 12, 21) input_shape: {1,64,12,21} downsample_ratio data_shape: (1,) input_shape: {1} outputs: seg data_shape: (1, 1, 189, 336) output_shape: {?,1,?,?} r1o data_shape: (1, 16, 95, 168) output_shape: {?,16,95,168} r2o data_shape: (1, 20, 48, 84) output_shape: {?,20,48,84} r3o data_shape: (1, 40, 24, 42) output_shape: {?,40,24,42} r4o data_shape: (1, 64, 12, 21) output_shape: {?,64,12,21}
epoch-0-static: 19.71 ms inputs: src data_shape: (1, 3, 504, 896) input_shape: {1,3,504,896} r1i data_shape: (1, 16, 95, 168) input_shape: {1,16,95,168} r2i data_shape: (1, 20, 48, 84) input_shape: {1,20,48,84} r3i data_shape: (1, 40, 24, 42) input_shape: {1,40,24,42} r4i data_shape: (1, 64, 12, 21) input_shape: {1,64,12,21} outputs: seg data_shape: (1, 1, 189, 336) output_shape: {1,1,189,336} r1o data_shape: (1, 16, 95, 168) output_shape: {1,16,95,168} r2o data_shape: (1, 20, 48, 84) output_shape: {1,20,48,84} r3o data_shape: (1, 40, 24, 42) output_shape: {1,40,24,42} r4o data_shape: (1, 64, 12, 21) output_shape: {1,64,12,21}
@avitial I have tested the two models with onnxruntime. The inference time of both models is 25-30ms. The inference script is as follows: inference.zip
Therefore, the inference time of dynamic input model under OpenVino is abnormal. Could you check the cause?
@wang7393 I see the shared ONNX files were produced with PyTorch v1.11.0, I was wondering if it would be possible to export using torch 1.8.1 (as listed in OMZ requirements-pytorch.in) and see if the issue is still observed (want to rule out torch version affecting the inference times).
In the meantime I've submitted this as a possible bug for the development team to take a look, will share some updates as soon as they are available.
Ref. 90215 (96660)
@wang7393 did you get a chance to try my previous suggestion? Kindly let me know the outcome of that.
@avitial I wiil try it.
"In the meantime I've submitted this as a possible bug for the development team to take a look, will share some updates as soon as they are available."
Is there a conclusion for this?
Hi @avitial, I meet the same error when I use GPU/VPU plugin which works well in CPU:
File "C:\Users\ruonanw1\Miniconda3\envs\ruonan_nano\lib\site-packages\openvino\runtime\ie_api.py", line 387, in compile_model
super().compile_model(model, device_name, {} if config is None else config),
RuntimeError: get_shape was called on a descriptor::Tensor with dynamic shape
@ilya-lavrenov, I wonder the progress for support of dynamic shapes on Intel GPU plugin?
@wang7393 no update yet, in addition to the performance issue you reported I had faced a bad_alloc error with benchmark_app and your model. The development team has been looking into these issues.
The bad_alloc was caused due to too large output memory allocation failure.
The current gaps for dynamic vs static will be addressed separately, so far I don't have updates or ETA from dev team on this. Will share more details as they become available.
@wang7393 please have a chance to test the pre-release for the upcoming 2023.0 as I can see improvements there while running your model (epoch-0.onnx) on the same hardware.
You can install pre-release with pip install openvino-dev==2023.0.0.dev20230427. For information on this pre-release kindly refer to the following resources:
- https://docs.openvino.ai/nightly/prerelease_information.html
- https://github.com/openvinotoolkit/openvino/releases/tag/2023.0.0.dev20230427
- https://pypi.org/project/openvino-dev/2023.0.0.dev20230427/
| ONNX-RT | OV-2022.1 | OV-2023.0 pre-release |
|---|---|---|
| Images to process: 100 Total inference time: 3.36 s Avg. inference time: 33.59 ms |
using static model images to process: 100 total inference time: 2.29 s avg. inference time: 22.89 ms |
using static model images to process: 100 total inference time: 1.28 s avg. inference time: 12.85 ms |
| using dynamic model images to process: 100 total inference time: 2.12 s avg. inference time: 21.23 ms |
using dynamic model images to process: 100 total inference time: 1.37 s avg. inference time: 13.66 ms |
Closing this issue, I hope previous responses were sufficient to help you proceed. Feel free to reopen and ask additional questions related to this topic.