openspeech
 openspeech copied to clipboard
openspeech copied to clipboard
Expected period of time hanging(or pre-processing) in the beginning of the training
❓ Questions & Help
When I start training the code, it is hanging in the beginning as below. How long do you expect to wait for the training to start? For my case, it is more than at least ~5 hrs. My very first run went through and it failed in the middle of the training because of CUDA issues.
[2021-09-16 01:46:18,272][openspeech.utils][INFO] - Operating System : Linux 5.11.0-27-generic
[2021-09-16 01:46:18,272][openspeech.utils][INFO] - Processor : x86_64
[2021-09-16 01:46:18,273][openspeech.utils][INFO] - device : NVIDIA GeForce RTX 2080 Ti
[2021-09-16 01:46:18,273][openspeech.utils][INFO] - CUDA is available : True
[2021-09-16 01:46:18,273][openspeech.utils][INFO] - CUDA version : 11.0
[2021-09-16 01:46:18,273][openspeech.utils][INFO] - PyTorch version : 1.7.0
GPU available: True, used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
/opt/conda/lib/python3.8/site-packages/pytorch_lightning/core/datamodule.py:423: LightningDeprecationWarning: DataModule.setup has already been called, so it will not be called again. In v1.6 this behavior will change to always call DataModule.setup.
rank_zero_deprecation(
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
wandb: (1) Create a W&B account
wandb: (2) Use an existing W&B account
wandb: (3) Don't visualize my results
wandb: Enter your choice: 3
wandb: You chose 'Don't visualize my results'
wandb: WARNING `resume` will be ignored since W&B syncing is set to `offline`. Starting a new run with run id tpyh7nfj.
CondaEnvException: Unable to determine environment
Please re-run this command with one of the following options:
* Provide an environment name via --name or -n
* Re-run this command inside an activated conda environment.
wandb: W&B syncing is set to `offline` in this directory. Run `wandb online` or set WANDB_MODE=online to enable cloud syncing.
| Name | Type | Params
-------------------------------------------------------
0 | criterion | JointCTCCrossEntropyLoss | 0
1 | encoder | LSTMEncoder | 36.6 M
2 | decoder | LSTMAttentionDecoder | 53.4 M
-------------------------------------------------------
90.0 M Trainable params
0 Non-trainable params
90.0 M Total params
359.991 Total estimated model params size (MB)
Global seed set to 1
Details
Env: Ubuntu 18.04 GPU: 2080TI 12GB
Five hours is a little strange. If there's no progress bar, it seems to be blocked somewhere.
@jun-danieloh
CondaEnvException: Unable to determine environment
I think you should first check you cuda version and cudatoolkit version.
@yinruiqing @sooftware I am using Docker Env. Should I use Conda always? I moved to AZURE server where I have plenty of memory and larger GPU but my model is still hanging at the same stage...
I think there's a deadlock. There seems to be an environmental problem.
I've never seen an error like this before, so I'm embarrassed.
@yinruiqing @sooftware
[2021-09-29 06:48:48,012][openspeech.utils][INFO] - Processor : x86_64
[2021-09-29 06:48:48,013][openspeech.utils][INFO] - device : Tesla V100-PCIE-16GB
[2021-09-29 06:48:48,013][openspeech.utils][INFO] - CUDA is available : True
[2021-09-29 06:48:48,013][openspeech.utils][INFO] - CUDA version : 11.0
[2021-09-29 06:48:48,013][openspeech.utils][INFO] - PyTorch version : 1.7.0
GPU available: True, used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
/opt/conda/lib/python3.8/site-packages/pytorch_lightning/core/datamodule.py:423: LightningDeprecationWarning: DataModule.setup has already been called, so it will not be called again. In v1.6 this behavior will change to always call DataModule.setup.
rank_zero_deprecation(
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
wandb: (1) Create a W&B account
wandb: (2) Use an existing W&B account
wandb: (3) Don't visualize my results
wandb: Enter your choice: 3
wandb: You chose 'Don't visualize my results'
wandb: WARNING `resume` will be ignored since W&B syncing is set to `offline`. Starting a new run with run id 2513tpfc.
CondaEnvException: Unable to determine environment
Please re-run this command with one of the following options:
* Provide an environment name via --name or -n
* Re-run this command inside an activated conda environment.
wandb: W&B syncing is set to `offline` in this directory. Run `wandb online` or set WANDB_MODE=online to enable cloud syncing.
I never activated Conda and don't understand why logs are complaining about it. Is it related to wandb? I made choice 3 while training. Do I miss anything here?
@jun-danieloh @sooftware It doesn't seem like a wandb problem, but how about changing the logger to tensorboard and trying it? [link]
I don't think this problem is caused by logging. It's hard because it's like an environmental problem.
openspeech/openspeech/data/sampler.py, line 88, sample_rate=16000. Always does resample when audio file is not 16k, it takes quite some time.
This is a bottleneck. [link].
When I used RandomSampler, it was immediately executed. [link]
sampler: str = field(
default="else", metadata={"help": "smart: batching with similar sequence length."
"else: random batch"}
)
Also getting this issue, for reference I'm using Ubuntu 20.04.2 and a 2080Ti also. Is there a fix?
@tand22 Would you like to try changing the sampler from smart to else? In the current code, the default is smart, so you will have to modify it.
Seems to have done something, however now getting this. How can I lower the memory usage?
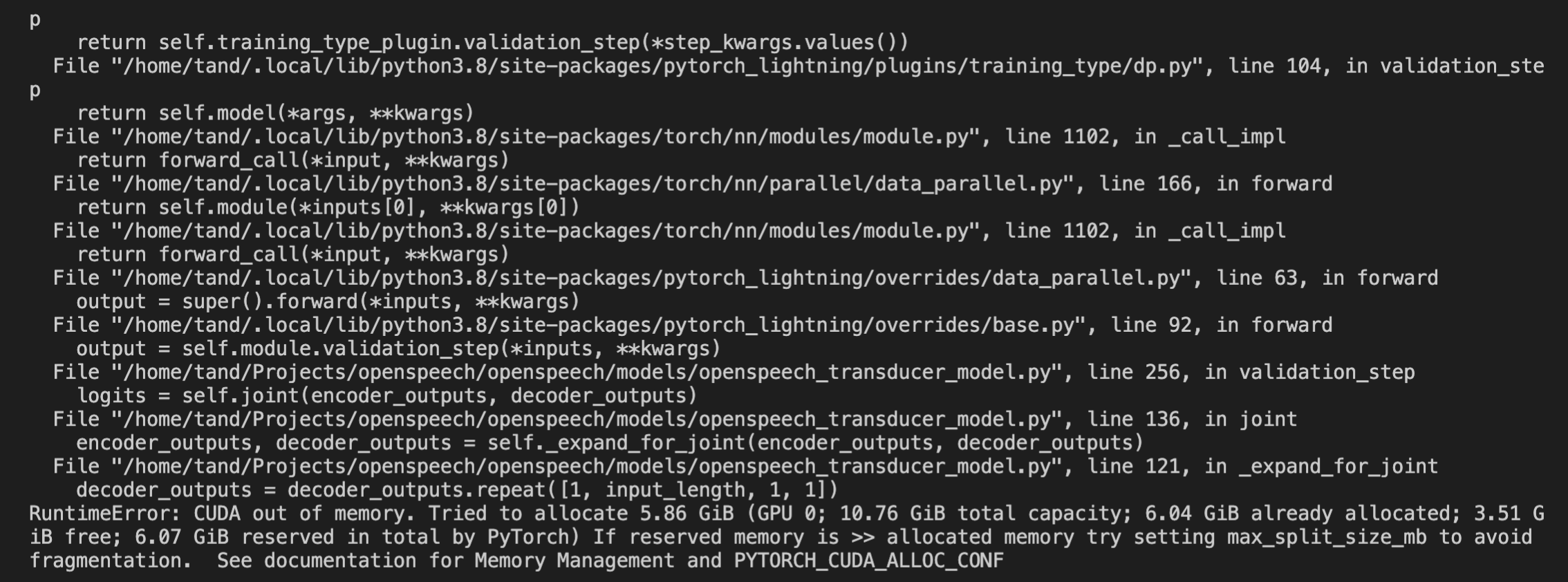
Even with a batch size of 1 I'm running out of memory.. might be a memory leak.
I also had the issue with smart sampler when training on LibriSpeech 960h. I am using random sampler but I want to know if this issue is still ongoing.