mmpose
 mmpose copied to clipboard
mmpose copied to clipboard
finetune with custom data
Hi,I follow the tutorial 1 and 2,added one keypoint to the coco dataset,that is, there are now 18 keypoints in coco format. Then I modify the config as follows:
log_level = 'INFO'
load_from = 'https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_256x192-ec54d7f3_20200709.pth'
optimizer = dict(
type='Adam',
lr=1e-4,
)
optimizer_config = dict(grad_clip=None)
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=0.001,
step=[10,15])
total_epochs = 20
channel_cfg = dict(
num_output_channels=18,
dataset_joints=18,
dataset_channel=[
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16],
],
inference_channel=[
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
])
model = dict(
type='TopDown',
pretrained=None,
backbone=dict(type='ResNeSt', depth=50),
keypoint_head=dict(
type='TopDownSimpleHead',
in_channels=512,
out_channels=18,
loss_keypoint=dict(type='JointsMSELoss', use_target_weight=False)),
train_cfg=dict(),
test_cfg=dict(
flip_test=True,
post_process='unbiased',
shift_heatmap=True,
modulate_kernel=11))
data_cfg = dict(
image_size=[192, 256],
heatmap_size=[48, 64],
num_output_channels=channel_cfg['num_output_channels'],
num_joints=channel_cfg['dataset_joints'],
dataset_channel=channel_cfg['dataset_channel'],
inference_channel=channel_cfg['inference_channel'],
soft_nms=False,
nms_thr=1.0,
oks_thr=0.9,
vis_thr=0.2,
use_gt_bbox=False,
det_bbox_thr=0.0,
bbox_file='data/coco/person_detection_results/'
'COCO_val2017_detections_AP_H_56_person.json',
)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='TopDownRandomFlip', flip_prob=0.5),
dict(
type='TopDownHalfBodyTransform',
num_joints_half_body=8,
prob_half_body=0.3),
dict(
type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
dict(type='TopDownAffine'),
dict(type='ToTensor'),
dict(
type='NormalizeTensor',
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
dict(type='TopDownGenerateTarget', sigma=2),
dict(
type='Collect',
keys=['img', 'target', 'target_weight'],
meta_keys=[
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
'rotation', 'bbox_score', 'flip_pairs'
]),
]
val_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='TopDownAffine'),
dict(type='ToTensor'),
dict(
type='NormalizeTensor',
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
dict(
type='Collect',
keys=['img'],
meta_keys=[
'image_file', 'center', 'scale', 'rotation', 'bbox_score',
'flip_pairs'
]),
]
test_pipeline = val_pipeline
data_root = 'data/coco'
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type='TopDownCocoDataset',
ann_file=f'/data/new_person_keypoints_train2017.json',
img_prefix=f'{data_root}/train2017/',
data_cfg=data_cfg,
pipeline=train_pipeline
),
val=dict(
type='TopDownCocoDataset',
ann_file=f'/data/new_person_keypoints_val2017.json',
img_prefix=f'{data_root}/val2017/',
data_cfg=data_cfg,
pipeline=val_pipeline
),
test=dict(
type='TopDownCocoDataset',
ann_file=f'/data/new_person_keypoints_val2017.json',
img_prefix=f'{data_root}/val2017/',
data_cfg=data_cfg,
pipeline=val_pipeline
),
)
report:
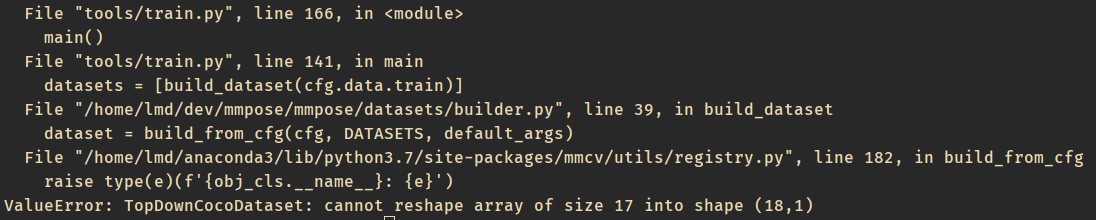
Since your customized dataset has 18 dataset, you have to modify https://github.com/open-mmlab/mmpose/blob/master/mmpose/datasets/datasets/top_down/topdown_coco_dataset.py
Especially, line79 to line98.
it fixed,thanks for your help! by the way,where can i set a separate learning rate or freeze for each layer?
You can refer to def _freeze_stages() and frozen_stages,
reminding to set find_unused_parameters = True in config files for distributed training or testing.

Since your customized dataset has 18 dataset, you have to modify https://github.com/open-mmlab/mmpose/blob/master/mmpose/datasets/datasets/top_down/topdown_coco_dataset.py
Especially, line79 to line98.
Hi, How can I use mmpose my own dataset? I have three keypoints/interest points (2 end points and a center point). Is there any script to convert my dataset into the coco format? and then how should I load my data? Any help in this regard will be highly appreciated. Thanks
@rubeea You can refer to tools/dataset/parse_macaquepose_dataset.py to prepare your dataset.
@jin-s13 Thanks for the reference. I saw other parse dataset scripts as well and I believe this script is more suitable for parsing any custom dataset: https://github.com/open-mmlab/mmpose/blob/master/tools/dataset/parse_deepposekit_dataset.py Can you kindly specify the source of images and annotations that this script s parsing so that I can download it. Also how are the skeleton values calculated in this script? Thanks
And the homepage of deeppose-kit (https://github.com/jgraving/DeepPoseKit-Data)
I have another problem, when I modify the cfg and the dataset file as this issue, used 14 keypoints. it occures the problem "size mismatch for keypoint_head.final_layer.bias: copying a param with shape torch.Size([17]) from checkpoint, the shape in current model is torch.Size([14])", theres is no error in running ,but the AP is all 0 or -1.
TorchVision: 0.9.0+cu101
OpenCV: 4.5.1
MMCV: 1.3.0
MMCV Compiler: GCC 7.3
MMCV CUDA Compiler: 10.1
MMPose: 0.10.0+e1cd7f5
------------------------------------------------------------
2021-04-27 10:38:21,223 - mmpose - INFO - Distributed training: False
2021-04-27 10:38:22,537 - mmpose - INFO - Config:
log_level = 'INFO'
load_from = 'https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_256x192-ec54d7f3_20200709.pth'
resume_from = None
dist_params = dict(backend='nccl')
workflow = [('train', 1)]
checkpoint_config = dict(interval=10)
evaluation = dict(interval=10, metric='mAP', key_indicator='AP')
optimizer = dict(type='Adam', lr=0.0001)
optimizer_config = dict(grad_clip=None)
lr_config = dict(policy='step', warmup=None, step=[17, 20])
total_epochs = 25
log_config = dict(interval=50, hooks=[dict(type='TextLoggerHook')])
channel_cfg = dict(
num_output_channels=14,
dataset_joints=14,
dataset_channel=[[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]],
inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])
model = dict(
type='TopDown',
pretrained=None,
backbone=dict(type='ResNet', depth=50),
keypoint_head=dict(
type='TopDownSimpleHead',
in_channels=2048,
out_channels=14,
loss_keypoint=dict(type='JointsMSELoss', use_target_weight=False)),
train_cfg=dict(),
test_cfg=dict(
flip_test=True,
post_process='unbiased',
shift_heatmap=True,
modulate_kernel=11))
data_cfg = dict(
image_size=[288, 384],
heatmap_size=[72, 96],
num_output_channels=14,
num_joints=14,
dataset_channel=[[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]],
inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
soft_nms=False,
nms_thr=1.0,
oks_thr=0.9,
vis_thr=0.2,
use_gt_bbox=True,
det_bbox_thr=0.0,
bbox_file=
'data/coco/person_detection_results/COCO_val2017_detections_AP_H_56_person.json'
)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='TopDownRandomFlip', flip_prob=0.5),
dict(
type='TopDownHalfBodyTransform',
num_joints_half_body=8,
prob_half_body=0.3),
dict(
type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
dict(type='TopDownAffine'),
dict(type='ToTensor'),
dict(
type='NormalizeTensor',
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
dict(type='TopDownGenerateTarget', sigma=3),
dict(
type='Collect',
keys=['img', 'target', 'target_weight'],
meta_keys=[
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
'rotation', 'bbox_score', 'flip_pairs'
])
]
val_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='TopDownAffine'),
dict(type='ToTensor'),
dict(
type='NormalizeTensor',
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
dict(
type='Collect',
keys=['img'],
meta_keys=[
'image_file', 'center', 'scale', 'rotation', 'bbox_score',
'flip_pairs'
])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='TopDownAffine'),
dict(type='ToTensor'),
dict(
type='NormalizeTensor',
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
dict(
type='Collect',
keys=['img'],
meta_keys=[
'image_file', 'center', 'scale', 'rotation', 'bbox_score',
'flip_pairs'
])
]
data_root = 'data/coco'
data = dict(
samples_per_gpu=8,
workers_per_gpu=2,
train=dict(
type='TopDownCocoDataset',
ann_file='data/coco/annotations/person_keypoints_train2017.json',
img_prefix='data/coco/train2017/',
data_cfg=dict(
image_size=[288, 384],
heatmap_size=[72, 96],
num_output_channels=14,
num_joints=14,
dataset_channel=[[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]],
inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
soft_nms=False,
nms_thr=1.0,
oks_thr=0.9,
vis_thr=0.2,
use_gt_bbox=True,
det_bbox_thr=0.0,
bbox_file=
'data/coco/person_detection_results/COCO_val2017_detections_AP_H_56_person.json'
),
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='TopDownRandomFlip', flip_prob=0.5),
dict(
type='TopDownHalfBodyTransform',
num_joints_half_body=8,
prob_half_body=0.3),
dict(
type='TopDownGetRandomScaleRotation',
rot_factor=40,
scale_factor=0.5),
dict(type='TopDownAffine'),
dict(type='ToTensor'),
dict(
type='NormalizeTensor',
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
dict(type='TopDownGenerateTarget', sigma=3),
dict(
type='Collect',
keys=['img', 'target', 'target_weight'],
meta_keys=[
'image_file', 'joints_3d', 'joints_3d_visible', 'center',
'scale', 'rotation', 'bbox_score', 'flip_pairs'
])
]),
val=dict(
type='TopDownCocoDataset',
ann_file='data/coco/annotations/person_keypoints_val2017.json',
img_prefix='data/coco/val2017/',
data_cfg=dict(
image_size=[288, 384],
heatmap_size=[72, 96],
num_output_channels=14,
num_joints=14,
dataset_channel=[[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]],
inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
soft_nms=False,
nms_thr=1.0,
oks_thr=0.9,
vis_thr=0.2,
use_gt_bbox=True,
det_bbox_thr=0.0,
bbox_file=
'data/coco/person_detection_results/COCO_val2017_detections_AP_H_56_person.json'
),
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='TopDownAffine'),
dict(type='ToTensor'),
dict(
type='NormalizeTensor',
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
dict(
type='Collect',
keys=['img'],
meta_keys=[
'image_file', 'center', 'scale', 'rotation', 'bbox_score',
'flip_pairs'
])
]),
test=dict(
type='TopDownCocoDataset',
ann_file='data/coco/annotations/person_keypoints_val2017.json',
img_prefix='data/coco/val2017/',
data_cfg=dict(
image_size=[288, 384],
heatmap_size=[72, 96],
num_output_channels=14,
num_joints=14,
dataset_channel=[[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]],
inference_channel=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
soft_nms=False,
nms_thr=1.0,
oks_thr=0.9,
vis_thr=0.2,
use_gt_bbox=True,
det_bbox_thr=0.0,
bbox_file=
'data/coco/person_detection_results/COCO_val2017_detections_AP_H_56_person.json'
),
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='TopDownAffine'),
dict(type='ToTensor'),
dict(
type='NormalizeTensor',
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
dict(
type='Collect',
keys=['img'],
meta_keys=[
'image_file', 'center', 'scale', 'rotation', 'bbox_score',
'flip_pairs'
])
]))
work_dir = './work_dirs/hrnet_w48_mycoco_384x288'
gpu_ids = range(0, 1)
loading annotations into memory...
Done (t=0.00s)
creating index...
index created!
=> num_images: 49
=> load 49 samples
loading annotations into memory...
Done (t=0.00s)
creating index...
index created!
=> num_images: 6
=> load 6 samples
2021-04-27 10:38:26,097 - mmpose - INFO - load checkpoint from https://download.openmmlab.com/mmpose/top_down/resnet/res50_coco_256x192-ec54d7f3_20200709.pth
2021-04-27 10:38:26,097 - mmpose - INFO - Use load_from_http loader
2021-04-27 10:38:26,156 - mmpose - WARNING - The model and loaded state dict do not match exactly
size mismatch for keypoint_head.final_layer.weight: copying a param with shape torch.Size([17, 256, 1, 1]) from checkpoint, the shape in current model is torch.Size([14, 256, 1, 1]).
size mismatch for keypoint_head.final_layer.bias: copying a param with shape torch.Size([17]) from checkpoint, the shape in current model is torch.Size([14]).
2021-04-27 10:38:26,157 - mmpose - INFO - Start running, host: gm@gm, work_dir: /home/gm/DataDisk/DL/mmpose/work_dirs/hrnet_w48_mycoco_384x288
2021-04-27 10:38:26,157 - mmpose - INFO - workflow: [('train', 1)], max: 25 epochs
2021-04-27 10:38:57,615 - mmpose - INFO - Saving checkpoint at 10 epochs
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 6/6, 16.6 task/s, elapsed: 0s, ETA: 0sLoading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *keypoints*
DONE (t=0.00s).
Accumulating evaluation results...
DONE (t=0.00s).
Average Precision (AP) @[ IoU=0.50:0.95 | type= all | maxDets= 20 ] = 0.000
Average Precision (AP) @[ IoU=0.50 | type= all | maxDets= 20 ] = 0.000
Average Precision (AP) @[ IoU=0.75 | type= all | maxDets= 20 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | type=medium | maxDets= 20 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | type= large | maxDets= 20 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | type= all | maxDets= 20 ] = 0.000
Average Recall (AR) @[ IoU=0.50 | type= all | maxDets= 20 ] = 0.000
Average Recall (AR) @[ IoU=0.75 | type= all | maxDets= 20 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | type=medium | maxDets= 20 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | type= large | maxDets= 20 ] = -1.000
2021-04-27 10:39:01,447 - mmpose - INFO - Epoch(val) [10][6] AP: 0.0000, AP .5: 0.0000, AP .75: 0.0000, AP (M): -1.0000, AP (L): -1.0000, AR: 0.0000, AR .5: 0.0000, AR .75: 0.0000, AR (M): -1.0000, AR (L): -1.0000
2021-04-27 10:39:33,114 - mmpose - INFO - Saving checkpoint at 20 epochs
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 6/6, 29.1 task/s, elapsed: 0s, ETA: 0sLoading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *keypoints*
DONE (t=0.00s).
Accumulating evaluation results...
DONE (t=0.00s).
Average Precision (AP) @[ IoU=0.50:0.95 | type= all | maxDets= 20 ] = 0.000
Average Precision (AP) @[ IoU=0.50 | type= all | maxDets= 20 ] = 0.000
Average Precision (AP) @[ IoU=0.75 | type= all | maxDets= 20 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | type=medium | maxDets= 20 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | type= large | maxDets= 20 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | type= all | maxDets= 20 ] = 0.000
Average Recall (AR) @[ IoU=0.50 | type= all | maxDets= 20 ] = 0.000
Average Recall (AR) @[ IoU=0.75 | type= all | maxDets= 20 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | type=medium | maxDets= 20 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | type= large | maxDets= 20 ] = -1.000
2021-04-27 10:39:36,849 - mmpose - INFO - Epoch(val) [20][6] AP: 0.0000, AP .5: 0.0000, AP .75: 0.0000, AP (M): -1.0000, AP (L): -1.0000, AR: 0.0000, AR .5: 0.0000, AR .75: 0.0000, AR (M): -1.0000, AR (L): -1.0000
2021-04-27 10:39:52,642 - mmpose - INFO - Saving checkpoint at 25 epochs
did you modify topdown_coco_dataset.py?
yes, the changed lines are followed:
self.ann_info['flip_pairs'] = [[0, 1], [2, 3], [4, 5], [6, 7], [8, 9], [10, 11],
[12, 13]]
self.ann_info['upper_body_ids'] = (0, 1, 2, 3, 4, 5, 6, 7)
self.ann_info['lower_body_ids'] = (8, 9, 10, 11, 12, 13)
self.ann_info['use_different_joint_weights'] = False
self.ann_info['joint_weights'] = np.array(
[
1., 1., 1., 1., 1.2, 1.2, 1.5, 1.5, 1., 1., 1.2,
1.2, 1.5, 1.5
],
dtype=np.float32).reshape((self.ann_info['num_joints'], 1))
# 'https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/'
# 'pycocotools/cocoeval.py#L523'
self.sigmas = np.array([
.26, .25, .79, .79, .72, .72, .62, .62, 1.07, 1.07,
.87, .87, .89, .89
]) / 10.0
And the homepage of deeppose-kit (https://github.com/jgraving/DeepPoseKit-Data)
@jin-s13 thanks for the link. As a test experiment, I have reannotated the deep pose kit fly dataset with 3 keypoints only instead of 32 keypoints. I have modified the "animal_fly_dataset.py" file as well as the train.py file. I want to use HRNet for training and I have modified the "hrnet_w32_animalpose_256x256.py" config file according to the new keypoints (3 keypoints) for the fly dataset. My config file is as follows:
Config:
log_level = 'INFO'
load_from = None
resume_from = None
dist_params = dict(backend='nccl')
workflow = [('train', 1)]
checkpoint_config = dict(interval=10)
evaluation = dict(interval=10, metric='mAP', key_indicator='AP')
optimizer = dict(type='Adam', lr=0.0005)
optimizer_config = dict(grad_clip=None)
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=0.001,
step=[170, 200])
total_epochs = 210
log_config = dict(
interval=1,
hooks=[dict(type='TextLoggerHook'),
dict(type='TensorboardLoggerHook')])
channel_cfg = dict(
num_output_channels=3,
dataset_joints=3,
dataset_channel=[[0, 1, 2]],
inference_channel=[0, 1, 2])
model = dict(
type='TopDown',
backbone=dict(
type='HRNet',
in_channels=3,
extra=dict(
stage1=dict(
num_modules=1,
num_branches=1,
block='BOTTLENECK',
num_blocks=(4, ),
num_channels=(64, )),
stage2=dict(
num_modules=1,
num_branches=2,
block='BASIC',
num_blocks=(4, 4),
num_channels=(32, 64)),
stage3=dict(
num_modules=4,
num_branches=3,
block='BASIC',
num_blocks=(4, 4, 4),
num_channels=(32, 64, 128)),
stage4=dict(
num_modules=3,
num_branches=4,
block='BASIC',
num_blocks=(4, 4, 4, 4),
num_channels=(32, 64, 128, 256)))),
keypoint_head=dict(
type='TopDownSimpleHead',
in_channels=3,
out_channels=3,
num_deconv_layers=0,
extra=dict(final_conv_kernel=1),
loss_keypoint=dict(type='JointsMSELoss', use_target_weight=True)),
train_cfg=dict(),
test_cfg=dict(
flip_test=True,
post_process='default',
shift_heatmap=True,
modulate_kernel=11))
data_cfg = dict(
image_size=[256, 256],
heatmap_size=[64, 64],
num_output_channels=3,
num_joints=3,
dataset_channel=[[0, 1, 2]],
inference_channel=[0, 1, 2],
soft_nms=False,
nms_thr=1.0,
oks_thr=0.9,
vis_thr=0.2,
use_gt_bbox=True,
det_bbox_thr=0.0,
bbox_file='')
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='TopDownRandomFlip', flip_prob=0.5),
dict(
type='TopDownHalfBodyTransform',
num_joints_half_body=8,
prob_half_body=0.3),
dict(
type='TopDownGetRandomScaleRotation', rot_factor=40, scale_factor=0.5),
dict(type='TopDownAffine'),
dict(type='ToTensor'),
dict(
type='NormalizeTensor',
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
dict(type='TopDownGenerateTarget', sigma=2),
dict(
type='Collect',
keys=['img', 'target', 'target_weight'],
meta_keys=[
'image_file', 'joints_3d', 'joints_3d_visible', 'center', 'scale',
'rotation', 'bbox_score', 'flip_pairs'
])
]
val_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='TopDownAffine'),
dict(type='ToTensor'),
dict(
type='NormalizeTensor',
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
dict(
type='Collect',
keys=['img'],
meta_keys=[
'image_file', 'center', 'scale', 'rotation', 'bbox_score',
'flip_pairs'
])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='TopDownAffine'),
dict(type='ToTensor'),
dict(
type='NormalizeTensor',
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
dict(
type='Collect',
keys=['img'],
meta_keys=[
'image_file', 'center', 'scale', 'rotation', 'bbox_score',
'flip_pairs'
])
]
data_root = '/content/pl_mmpose/data/DeepPoseKit-Data/datasets/fly'
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
val_dataloader=dict(samples_per_gpu=2),
test_dataloader=dict(samples_per_gpu=2),
train=dict(
type='AnimalFlyDataset',
ann_file=
'/content/pl_mmpose/data/DeepPoseKit-Data/datasets/fly/annotations/fly_train.json',
img_prefix=
'/content/pl_mmpose/data/DeepPoseKit-Data/datasets/fly/images',
data_cfg=dict(
image_size=[256, 256],
heatmap_size=[64, 64],
num_output_channels=3,
num_joints=3,
dataset_channel=[[0, 1, 2]],
inference_channel=[0, 1, 2],
soft_nms=False,
nms_thr=1.0,
oks_thr=0.9,
vis_thr=0.2,
use_gt_bbox=True,
det_bbox_thr=0.0,
bbox_file=''),
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='TopDownRandomFlip', flip_prob=0.5),
dict(
type='TopDownHalfBodyTransform',
num_joints_half_body=8,
prob_half_body=0.3),
dict(
type='TopDownGetRandomScaleRotation',
rot_factor=40,
scale_factor=0.5),
dict(type='TopDownAffine'),
dict(type='ToTensor'),
dict(
type='NormalizeTensor',
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
dict(type='TopDownGenerateTarget', sigma=2),
dict(
type='Collect',
keys=['img', 'target', 'target_weight'],
meta_keys=[
'image_file', 'joints_3d', 'joints_3d_visible', 'center',
'scale', 'rotation', 'bbox_score', 'flip_pairs'
])
]),
val=dict(
type='AnimalFlyDataset',
ann_file=
'/content/pl_mmpose/data/DeepPoseKit-Data/datasets/fly/annotations/fly_test.json',
img_prefix=
'/content/pl_mmpose/data/DeepPoseKit-Data/datasets/fly/images',
data_cfg=dict(
image_size=[256, 256],
heatmap_size=[64, 64],
num_output_channels=3,
num_joints=3,
dataset_channel=[[0, 1, 2]],
inference_channel=[0, 1, 2],
soft_nms=False,
nms_thr=1.0,
oks_thr=0.9,
vis_thr=0.2,
use_gt_bbox=True,
det_bbox_thr=0.0,
bbox_file=''),
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='TopDownAffine'),
dict(type='ToTensor'),
dict(
type='NormalizeTensor',
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
dict(
type='Collect',
keys=['img'],
meta_keys=[
'image_file', 'center', 'scale', 'rotation', 'bbox_score',
'flip_pairs'
])
]),
test=dict(
type='AnimalFlyDataset',
ann_file=
'/content/pl_mmpose/data/DeepPoseKit-Data/datasets/fly/annotations/fly_test.json',
img_prefix=
'/content/pl_mmpose/data/DeepPoseKit-Data/datasets/fly/images',
data_cfg=dict(
image_size=[256, 256],
heatmap_size=[64, 64],
num_output_channels=3,
num_joints=3,
dataset_channel=[[0, 1, 2]],
inference_channel=[0, 1, 2],
soft_nms=False,
nms_thr=1.0,
oks_thr=0.9,
vis_thr=0.2,
use_gt_bbox=True,
det_bbox_thr=0.0,
bbox_file=''),
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='TopDownAffine'),
dict(type='ToTensor'),
dict(
type='NormalizeTensor',
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
dict(
type='Collect',
keys=['img'],
meta_keys=[
'image_file', 'center', 'scale', 'rotation', 'bbox_score',
'flip_pairs'
])
]))
work_dir = '/content/pl_mmpose//work_dirs/tutorial'
seed = 0
gpu_ids = range(0, 1)
However, when I attempt to train my HRNet, I get the following error:
Given groups=1, weight of size [3, 3, 1, 1], expected input[2, 32, 64, 64] to have 3 channels, but got 32 channels instead
Kindly, help me in resolving the error. I am also attaching my animal_fly_data animal_fly_dataset.txt hrnet_w32_animalpose_256x256.txt train.txt
set.py, train.py and HRNet config files for your reference. Kindly help.
Regards, Rabeea
The in_channels of the keypoint_head is not correct.
keypoint_head=dict(
type='TopDownSimpleHead',
in_channels=3, # this is not correct.
out_channels=3,
num_deconv_layers=0,
extra=dict(final_conv_kernel=1),
The in_channels of the keypoint_head is not correct.
keypoint_head=dict( type='TopDownSimpleHead', in_channels=3, # this is not correct. out_channels=3, num_deconv_layers=0, extra=dict(final_conv_kernel=1),
@jin-s13 Resolved successfully. Thank you so much for the help :)
@rubeea You can refer to
tools/dataset/parse_macaquepose_dataset.pyto prepare your dataset.
@jin-s13 I just realized that deepposekit only supports single object keypoint annotations and does not facilitate maultiple objects in the same image. Hence, I intend to use the sample script that you recommended "tools/dataset/parse_macaquepose_dataset.py". This script loads annotations from a .csv file called "annotations.csv". Can you kindly provide the link to this file or inform me about the software using which these keypoint annotations were created so that I can create similar ones for my own dataset. Looking forward to your reply. Thanks a lot.
@rubeea Please check the official homepage.
@jin-s13 thanks I have downloaded the dataset and the annotations.csv file. According to the .csv, MacaquePose supports multiple objects annotations per image. However, the authors have not mentioned the annotation protocol or released the annotation script code for annotating multiple objects with keypoints within the images. Can you kindly help in this regard? Looking forward to your reply.
P.s: I am attaching the macaque annotations.csv file here for assistance of other people in case if they do not want to download the whole dataset (size ~ 20 GB). annotations.csv
u modify topdown_coco_dataset.py?
where shall I do such modification? I have a look on this file topdown_coco_dataset but i did not know where those things will be added/changed?