mmdetection
 mmdetection copied to clipboard
mmdetection copied to clipboard
[WIP]: Add DINO
Motivation
Implement the results in the paper "DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection" with mmdetection. The original code has released.
Remark
This is my first time to submit a PR to reproduces an algorithm, and I'm still lack of experience. I hope that developers who pay attention to this PR can comment more problems in my implementation and share some results. I will also follow up and share some of my own experimental results and progress arrangements.
Hi, thanks very much for your code. May I ask if you have met this problem?

When did this happen ? at the beginning or after a few epochs of training ?
@czczup I haven't fully trained yet, but I have tested 1000 iters training (2 GPU dist_train). I didn't met it. Could you please provide more information? Thanks for your attention.
Hi, thanks very much for your code. May I ask if you have met this problem?
When did this happen ? at the beginning or after a few epochs of training ?
Thanks for your reply. I use a single GPU to train (debug) with the config you provided. It happened at the beginning of training (50 iters).
As you can see in this log:

It seems that bbox_head.label_embedding.weight did not receive a gradient during some iterations.
I could use find_unused_parameters=True to avoid this problem, but it would affect training efficiency.
@czczup Hi, the newest config file contains other incompatibility problems.
norm_cfg=dict(type='FrozenBatchNorm2d'), # should use BN instead
conv_cfg=dict(type='Conv2d', bias=True), # should be deleted
I made modification in my local workstation, which I haven't committed. Did you meet these problems.
@czczup I'm working on experiments for aligning training results, there is still a few modification which i have not committed.
You can comment the FrozenBatchNorm2d, use BN instead. I modified the bn file of mmcv to registry the FrozenBatchNorm2d, but i prepare to delete it at last. In the original DINO, the convs of neck has bias, which is not recommended in mmdetection. To align inference accuracy, i had to modify the conv building func in mmcv. You can comment this line.
@czczup The label_embedding is used in DINOHead.forward_train() and DnQueryGenerator.forward(). I haven't found the bug yet, and maybe a few days later it'll be found. I'm pushing full speed ahead with the training. And more details will be committed. Thanks for your attention and discussion.
@Li-Qingyun
When the latest config is used, the label_embedding problem disappeared. Thanks for helping.
I checked with the paper and the source code published by the authors, and it seems that most of the settings are aligned, except for the learning_rate (1e-4 in paper but 2e-4 in this config) and noise_scale (0.5&0.4 in paper but 0.5&1.0 in this config).
I'm not sure if there's any detail I missed. I plan to train DINO-R50 for 12 epochs with 8 GPUs today.
@czczup Hi, the original repo has a sh file to launch training, in which the box_noise_scale is set 1.
The description is at the last paragraph of the D.3 (Supplementary Materials) of the paper.
Multi-scale setting. For our 4-scale models, we extract features from stages 2, 3, and 4 of the backbone and add an extra feature by down-sampling the output of the stage 4. An additional feature map of the backbone stage 1 is used for our 5-scale models. For hyper-parameters, we set λ1 = 1.0 and λ2 = 2.0 and use 100 CDN pairs which contain 100 positive queries and 100 negative queries.
The learning rate was indeed misaligned, thank you very much!
I met a new problem, it happens in the middle of training, such as 2000 iterations. I'm trying to fix it.
I notice that it happens when dn_cls_scores is None, so that keys in loss_dict are different across GPUs.
AssertionError: loss log variables are different across GPUs!
rank 2 len(log_vars): 21 keys: interm_loss_cls,interm_loss_bbox,interm_loss_iou,loss_cls,loss_bbox,loss_iou,d0.loss_cls,d0.loss_bbox,d0.loss_iou,d1.loss_cls,d1.loss_bbox,d1.loss_iou,d2.loss_cls,d2.loss_bbox,d2.loss_iou,d3.loss_cls,d3.loss_bbox,d3.loss_iou,d4.loss_cls,d4.loss_bbox,d4.loss_iou
@czczup Thanks! Maybe it's the special case when the current sample has no target, I'll have a check.
@czczup Hi, I'm waiting for the queue of lab's slurm cluster, so can't experiment in time. Could you have a test of setting filter_empty_gt=True?
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(filter_empty_gt=True, pipeline=train_pipeline), # Modify here
val=dict(pipeline=test_pipeline),
test=dict(pipeline=test_pipeline))
@Li-Qingyun Only set filter_empty_gt=True is not enough, I also set allow_negative_crop=False.
Image without any bbox ground-truth will cause this problem.
@Li-Qingyun Only set
filter_empty_gt=Trueis not enough, I also setallow_negative_crop=False. Image without any bbox ground-truth will cause this problem.
My model is still in training and I can share my results with you when it's finished
@czczup thank you very much for the information
The model modules should have the ability to handle this kind of case. I will check and fix this. Thanks for your sharing.
@Li-Qingyun
My last box AP is 48.4 and 0.6 points lower than the official repo (49.0 box AP), I suspect skipping negative samples may cause some performance degradation.
@czczup thanks for your sharing!
In the latest commit, I have modified DINOHead.loss_dn_single() at mmdet/models/dense_heads/dino_head.py to return Tensor(0) as each loss for dn. (extract_dn_outputs() has been modified too)
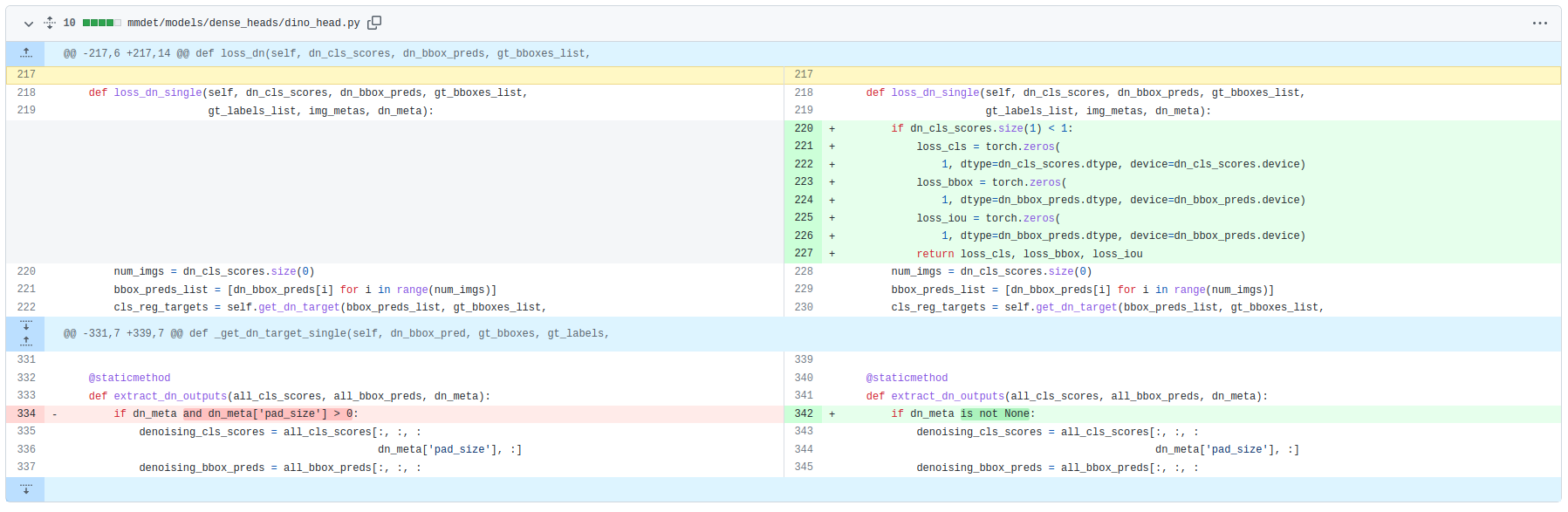
My Finished work
In the past week, I have finished aligning inference accuracy (with converted ckpt released by the authors, FrozenBatchNorm and Convs with bias in neck were used), and aligned the losses generated by the two codebases from the same samples (gap about 2e-4 of the total losses). The state_dict convert scripts and other aligning utils has been upload to this repo. The aforementioned work were all conducted on DINO_4scales.
Experimental modifications which are not committed
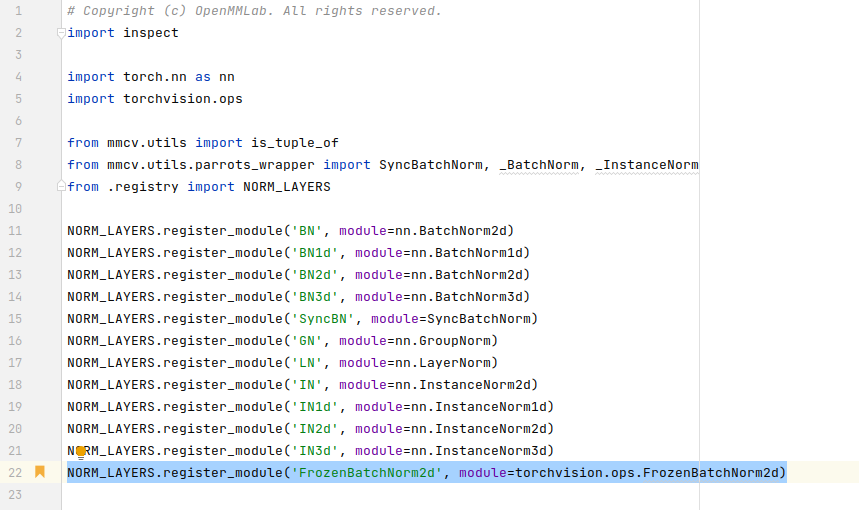
/mmcv/cnn/bricks/norm.py
For setting norm_cfg=dict(type='FrozenBatchNorm2d')
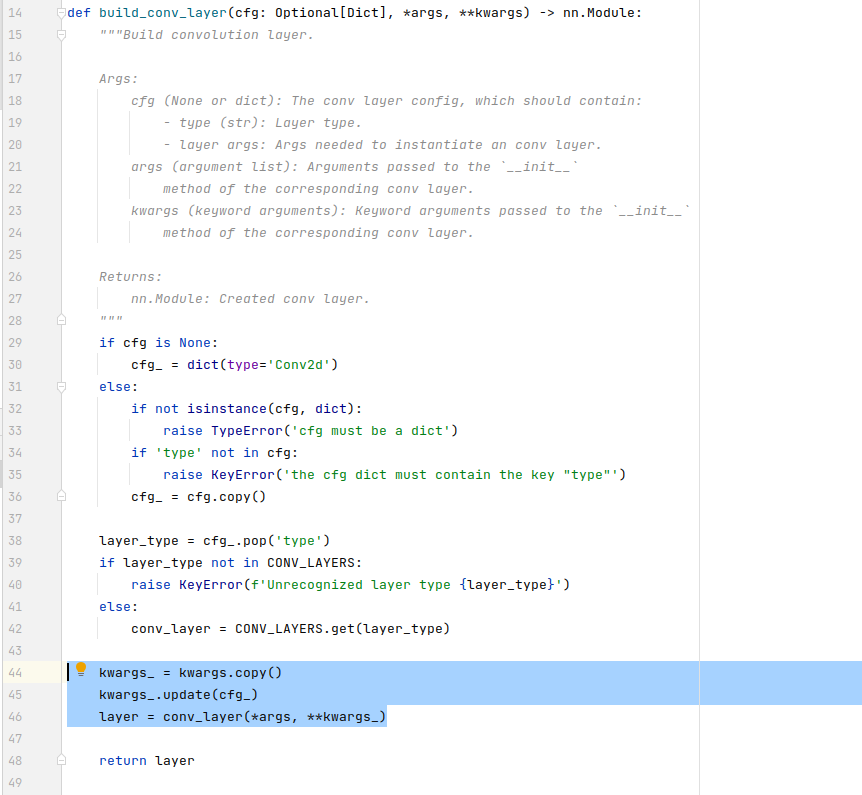
/mmcv/cnn/bricks/conv.py
For setting conv_cfg=dict(type='Conv2d', bias=True)
/mmdet/dataset/coco.py
The original DINO repo set num_class=91, to align inference map without training, the CocoDataset is modified to get aligned target labels. I have uploaded the coco.py file to this repo.
Overwrite the coco.py, and you can set add --options data.train.continuous_categories=False model.bbox_head.num_classes=91 at the end of your training commands.
For example:
python tools/train.py \
configs/dino/dino_4scale_r50_16x2_12e_coco.py \
--seed 42 \
--deterministic \
--options \
data.train.continuous_categories=False \
model.bbox_head.num_classes=91
Following arrangement
Additionally, I'm going to have a check to make sure the model initialization is aligned with the source code.
I'm still waiting for the queue. The computing resources of the lab seem tight recently, I decide to try using 2 GPU with 4x bigger batch_size for exp.
Results of preliminary training experiments of the current version
Results of DINO_4scale_R50_12e
Train with origin repo code
script:
PARTITION_NAME=$1
NUM_GPUS=8
srun -p $PARTITION_NAME -n 1 --ntasks-per-node=1 --gres=gpu:$NUM_GPUS --cpus-per-task=40 \
python -m torch.distributed.launch --nproc_per_node=$NUM_GPUS main.py \
--output_dir logs/DINO/R50-MS4 -c config/DINO/DINO_4scale.py --coco_path data/coco/ \
--options dn_scalar=100 embed_init_tgt=TRUE \
dn_label_coef=1.0 dn_bbox_coef=1.0 use_ema=False \
dn_box_noise_scale=1.0
Results (Official: 49.0):
seed=42:
"test_coco_eval_bbox": [0.4873132674960999, 0.6613892204926395, 0.5299718405240965, 0.3097563780570846, 0.5200259496800922, 0.6276603680117593, 0.3760974947699587, 0.648398246301584, 0.7259767833244375, 0.5585821102614945, 0.7691926278555588, 0.8832943363588871
seed=1999:
"test_coco_eval_bbox": [0.48881166833204975, 0.6625810511292044, 0.5337058970483411, 0.310836480374128, 0.5213143580767997, 0.6386154609695947, 0.375656002127738, 0.648566769851021, 0.7225129787686829, 0.5469380246490395, 0.7644535576931001, 0.8857967425155622]
seed=2022:
"test_coco_eval_bbox": [0.48596151760994727, 0.6591535604313493, 0.5308893680282089, 0.3048096267805175, 0.5166487219765998, 0.6290219521155032, 0.37418452677145564, 0.6453000252716654, 0.7215818952300844, 0.5433005018910609, 0.7590221671325503, 0.8817776135205894]
I'll experiment a few more times to see the approximate range of fluctuations in the results
Train with committed code
script:
PARTITION_NAME=$1
SCALE=$2
EPOCH=$3
SEED=$4
ARGS=${@:5}
GPUS=8 GPUS_PER_NODE=8 \
./tools/slurm_train.sh \
mm_det \
dino_${SCALE}scale_r50_8x2_${EPOCH}e_coco \
./configs/dino/dino_${SCALE}scale_r50_8x2_${EPOCH}e_coco.py \
/mnt/lustre/liqingyun.vendor/work_dirs/dino_${SCALE}scale_r50_8x2_${EPOCH}e_coco_seed_${SEED} \
--seed ${SEED} ${ARGS}
Results:
The results below adopted FrozenBatchNorm2d and Conv w/ bias for neck for model arch aligning, please refer to previous comments for modifications required to run. I'll conduct experiments of the mmcv native module.
seed=42 --deterministic
bbox_mAP: 0.4860, bbox_mAP_50: 0.6600, bbox_mAP_75: 0.5310, bbox_mAP_s: 0.3120, bbox_mAP_m: 0.5190, bbox_mAP_l: 0.6310
seed=68
bbox_mAP: 0.4890, bbox_mAP_50: 0.6610, bbox_mAP_75: 0.5340, bbox_mAP_s: 0.3050, bbox_mAP_m: 0.5190, bbox_mAP_l: 0.6410
seed=1920
bbox_mAP: 0.4880, bbox_mAP_50: 0.6620, bbox_mAP_75: 0.5340, bbox_mAP_s: 0.3040, bbox_mAP_m: 0.5230, bbox_mAP_l: 0.6320
seed=1999
bbox_mAP: 0.4880, bbox_mAP_50: 0.6620, bbox_mAP_75: 0.5340, bbox_mAP_s: 0.3040, bbox_mAP_m: 0.5230, bbox_mAP_l: 0.6320
seed=2022
bbox_mAP: 0.4860, bbox_mAP_50: 0.6580, bbox_mAP_75: 0.5300, bbox_mAP_s: 0.3080, bbox_mAP_m: 0.5210, bbox_mAP_l: 0.6310
seed=6666
bbox_mAP: 0.4860, bbox_mAP_50: 0.6590, bbox_mAP_75: 0.5300, bbox_mAP_s: 0.3050, bbox_mAP_m: 0.5150, bbox_mAP_l: 0.6360
seed=6666, --diff-seed
bbox_mAP: 0.4850, bbox_mAP_50: 0.6580, bbox_mAP_75: 0.5290, bbox_mAP_s: 0.3110, bbox_mAP_m: 0.5190, bbox_mAP_l: 0.6280
seed=2022, --diff-seed
bbox_mAP: 0.4840, bbox_mAP_50: 0.6540, bbox_mAP_75: 0.5270, bbox_mAP_s: 0.3090, bbox_mAP_m: 0.5160, bbox_mAP_l: 0.6320
The results below adopted mmcv native BN2d and Neck, see the configs of latest version.
seed=42
bbox_mAP: 0.4860, bbox_mAP_50: 0.6600, bbox_mAP_75: 0.5320, bbox_mAP_s: 0.3120, bbox_mAP_m: 0.5210, bbox_mAP_l: 0.6330
seed=1920
bbox_mAP: 0.4870, bbox_mAP_50: 0.6590, bbox_mAP_75: 0.5290, bbox_mAP_s: 0.3150, bbox_mAP_m: 0.5180, bbox_mAP_l: 0.6330
seed=1999
bbox_mAP: 0.4870, bbox_mAP_50: 0.6620, bbox_mAP_75: 0.5340, bbox_mAP_s: 0.3040, bbox_mAP_m: 0.5220, bbox_mAP_l: 0.6360
seed=2022
bbox_mAP: 0.4880, bbox_mAP_50: 0.6620, bbox_mAP_75: 0.5310, bbox_mAP_s: 0.3110, bbox_mAP_m: 0.5220, bbox_mAP_l: 0.6340
Other problems
The training of my implementation took about 13 hours, while that of the origin repo code took 8 hours. I can not achieve the inference speed reported (benchmark.py got 7 img/s, while the FPS reported is 24. Note that the fps scripts were not aligned.). Hence I still need to check out the reason for the inefficiency in my implementation.
Results of DINO_4scale_R50_36e
Train with origin repo code
command:
PARTITION_NAME=$1
NUM_GPUS=8
srun -p $PARTITION_NAME -n 1 --ntasks-per-node=1 --gres=gpu:$NUM_GPUS --cpus-per-task=40 \
python -m torch.distributed.launch --nproc_per_node=$NUM_GPUS main.py \
--output_dir logs/DINO/R50-MS4-seed_1999 -c config/DINO/DINO_4scale.py --coco_path data/coco/ \
--seed 1999 \
--options dn_scalar=100 embed_init_tgt=TRUE \
dn_label_coef=1.0 dn_bbox_coef=1.0 use_ema=False \
dn_box_noise_scale=1.0 epochs=36 lr_drop=30
Results (Official: 50.9):
seed=1999:
"test_coco_eval_bbox": [0.5053947020639069, 0.685007231553511, 0.5513394037459328, 0.331298595377718, 0.5390263215394429, 0.6505427418959137, 0.3818753372181372, 0.6584023194710107, 0.7304000110183289, 0.56530672690942, 0.773200397094524, 0.8805619748917786], "best_res": 0.5053947020639069]
Train with committed code
Results:
The results below adopted mmcv native BN2d and Neck, see the configs of latest version.
seed=1920
bbox_mAP: 0.5070, bbox_mAP_50: 0.6870, bbox_mAP_75: 0.5540, bbox_mAP_s: 0.3330, bbox_mAP_m: 0.5370, bbox_mAP_l: 0.6560
seed=2022
bbox_mAP: 0.5050, bbox_mAP_50: 0.6830, bbox_mAP_75: 0.5530, bbox_mAP_s: 0.3390, bbox_mAP_m: 0.5370, bbox_mAP_l: 0.6580
我遇到了一个新问题,它发生在训练的中间,比如 2000 次迭代。我正在尝试修复它。 我注意到它在
dn_cls_scores为 None 时发生,因此 loss_dict 中的键在 GPU 之间是不同的。AssertionError: loss log variables are different across GPUs! rank 2 len(log_vars): 21 keys: interm_loss_cls,interm_loss_bbox,interm_loss_iou,loss_cls,loss_bbox,loss_iou,d0.loss_cls,d0.loss_bbox,d0.loss_iou,d1.loss_cls,d1.loss_bbox,d1.loss_iou,d2.loss_cls,d2.loss_bbox,d2.loss_iou,d3.loss_cls,d3.loss_bbox,d3.loss_iou,d4.loss_cls,d4.loss_bbox,d4.loss_iou
您好 您是如何解决这个问题的?
我遇到了一个新问题,它发生在训练的中间,比如 2000 次迭代。我正在尝试修复它。 我注意到它在
dn_cls_scores为 None 时发生,因此 loss_dict 中的键在 GPU 之间是不同的。AssertionError: loss log variables are different across GPUs! rank 2 len(log_vars): 21 keys: interm_loss_cls,interm_loss_bbox,interm_loss_iou,loss_cls,loss_bbox,loss_iou,d0.loss_cls,d0.loss_bbox,d0.loss_iou,d1.loss_cls,d1.loss_bbox,d1.loss_iou,d2.loss_cls,d2.loss_bbox,d2.loss_iou,d3.loss_cls,d3.loss_bbox,d3.loss_iou,d4.loss_cls,d4.loss_bbox,d4.loss_iou您好 您是如何解决这个问题的?
现在的代码已经没有这个问题了
@zhaoguoqing12 你好,这个问题我们已经在 390b25a 基本解决
请问你是运行最新版本再次出现该问题吗。你可以检查你本地仓库的版本,目前最新版本为 d380deb,如果你本地不是最新版本,可以通过 git pull https://github.com/Li-Qingyun/mmdetection.git add-dino 更新本地仓库。如果是最新版本出现的问题,请麻烦提供一下环境版本,本地修改,运行命令 等信息
@zhaoguoqing12你好,这个问题我们已经在390b25a基本解决方案
你可以查看你本地仓库的最新版本,当前最新d380deb,你本地不是最新版本,git pull https://github.com/Li-Qingyun/mmdetection.git add-dino 可以更新本地仓库。是如果出现的更新版本修改问题,请解决一下最新的环境修改,本地提供的信息,运行命令等
我确实不是最新版本,但是我并不是在训练dino出现的这个问题。
@zhaoguoqing12 如果是你自己的仓库出现相同的问题,你需要保证 loss_dict.keys() 是固定不变的。例如:在目前版本的DINO中loss_dict应当有39项目,我的检查方法为,在 loss_dict 被 reduce 之前:
if len(loss_dict) != 39:
import ipdb; ipdb.set_trace()
通过移动帧发现 loss_dict.keys() 中缺少 dn 相关的 loss,所以在获取dn loss的函数中增加 无目标情况的分支,来保证所有的情况下,loss_dict 都稳定地由 39 项构成。目前这里的操作能暂时解决该问题,后续review阶段可能会用更好的方式替代。(例如,在没有目标的情况下,loss_giou和loss_bbox就自然为0,这种情况下补充的 loss_dn为0,但没有计算图)
我发现 DINO 源码中其实也有防止类似报错的操作,但 loss 部分基本是完全重构的,所以当时并没有注意到~
所以提供给你的思路是,去检查一下你报错信息中的这个 loss_dict 的获取。可以用上面的方式定位到报错情况,然后对特殊情况进行补位处理。
We start to refactor modules of DETR-like models to enhance the usability and readability of our codebase. For not affecting the progress of experiments in the current version and the works of those who follow our PR. I create a new PR of refactor:
#9149
I'll merge the refactor PR to this PR when it's finished. The followers can continue to conduct experiments based on our current PR, and the relevant bugs will continue to be fixed too. Besides, the experimental results will continue to be released.
Thank you for your attention!
We decide to complete the development of DINO on MMDetection 2.x in this pr. The code remains using the old style (the code has been refactored in MMDetection 3.x for a new style). The users are recommended to use #9149 in MMDetection 3.x. This support is mainly for the users who may have to use old versions.
TO-DO List
- [x] refactor CdnQueryGenerator
- [ ] Add DocString
- [ ] detector class
- [ ] Dino Transformer
- [ ] Dino Transformer Decoder
- [ ] DinoHead
- [ ] CdnQueryGenerator
- [ ] Add unit test
- [ ] Add readme
- [ ] Add model to zoo
- [ ] Add metafiles