MultiResUNet
 MultiResUNet copied to clipboard
MultiResUNet copied to clipboard
How we can predict the model?
Dear Author, I did not found any dataloader and prepared code for dataset organization. How we train the model. Moreover, How we can test the performance of the model?
Hi, thank you for your interest in our project.
We actually, did our experiments in a pretty boilerplate configurations, without any fancy pre or post-processing. Hence, I didn't include those simple scripts as we used usual keras functions anyway.
However, the lack of a complete pipeline may have caused inconvenience to some of us. Therefore, now I've added a Demo here. This is just a simple pipeline, involving downloading data from ISIC-17 dataset, creating a model, and training it. The model is evaluated using custom functions computing Jaccard Index or perhaps Dice Coefficient.
Thank you so much for your attention and high consideration. I read your paper and found out that you have applied your proposed architecture on Electron microscopy images(have you test your work on cells segmentation). I check your code and train the model with this dataset but I could not receive good results from the method and which dataset in ISBI(cell tracking challenge) you used in your paper? I will be thankful if you guide me on this issue.
Hello, we used this dataset from the "ISBI 2012 : Segmentation of neuronal structures in EM stacks" challenge. Which dataset are you using ?
For the dataset we used, we got a mean Jaccard Index value of 87.9477 ± 0.7741 from 5-fold cv using MultiResUNet, which was just apparently a slight improvement over U-Net (87.4092 ± 0.7071). What kind of results are you getting? Also how does the output segmentation masks look?
Thanks a lot for your response. About the dataset which i mean has the segmentation mask like below.

I used 30 image in training process but my jaccard Index is very low about 0.25. In your opinion how many annotated dataset i need to have good result in test set.
Thank you for your interest in our project as well. Thanks for providing the segmentation mask. Would you kindly include the input image, ground truth mask and the predicted mask for this image? Sorry if I am troubling you by asking too much.
Dataset of 30 image is indeed small, however the ISBI -2D EM dataset also consists of 30 images. But those images are quite alike. Hence, if your images are not too drastically different they should work just fine.
For how many epochs did you train the model? Also have you tried some other architectures like U-Net, DeepLab ? If so how did they perform?
Thanks.
Thank you so much again for your high attention.
I put the dataset sample below and I did it for 20 epochs. after the 5th epoch, the dice and Jaccard index reduce significantly. yes, I cheeked the unet and got the accuracy of approximately 90 percent with this dataset. I thought that maybe your model is not robust in grayscale input image but after reading your paper, I figured out that you have used also grayscale images in your experiments. I use several Chanel is 3 for input dataset(each channel has the same input and merged with together in each steps. actually this dataset that i used is public dataset. i put input image with mask of dataset below.
input image
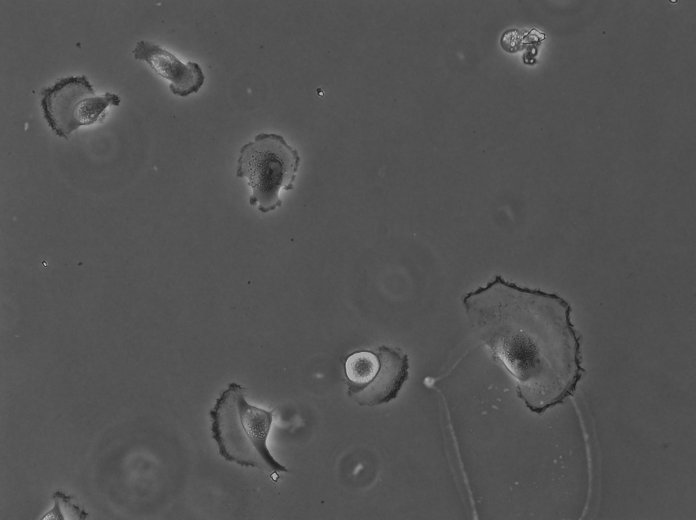
Ground Truth

Hi, sorry for my delayed response as I've been away for a while. Thank you very much for providing the images and responding to all my queries.
20 epochs is however a small time to train a model properly. Also as you state that the metrics fall drastically after 5 epochs, indicates to overfitting. Maybe some augmentation and regularization can be done. Also, would you test the model by using 1 channel input instead of 3? It would be helpful if you mentioned the name of the dataset since it is public, perhaps I may be able to witness the issue myself then as well.
Thanks again, have a great day, best wishes.
again, Thank you so much for your high attention and consideration. Yes, sure I can also put the link of the dataset here and also i upload it in my dropbox and share it with you.
link of the dataset :
http://celltrackingchallenge.net/datasets/
Link which i uplead the dataset here:
[https://www.dropbox.com/sh/vicmoxtv8rn68jk/AABC0XyXF82QfA6opuwUqKrwa?dl=0] (dropbox link)
It is better to download the dataset from the dropbox instead of website it needs to register and needs some days to register and get promo code.
Thanks again and Best wishes,
Hello. Sorry for such a delayed response. I had been overly occupied for the last few days.
Thank you for being so kind to upload the images for me. I've downloaded them and will check them out. I'll let you know how things turn out.
Hi @Ayanzadeh93 , pardon me for this long delay, I've been overly occupied last month.
Thank you for providing me with the data. I've downloaded it and ran my model on it. I found that only the train folder had segmentation masks under the SEG directory. So I took those data only (around 30+ images) and performed a train-test split of 80-20 using Sklearn standard function.
After that I ran the model for 100 epochs, I found that the dice score reaches above 90% for multiresunet model, and if I do some image augmentations it exceeds 92%.
It should be noted that the segmentation mask was signifying instance segmentation mask, i.e., cell no. 1,2,3 etc. But I converted it to a binary mask, i.e. if it is a cell or background.
Very sorry for the delayed response, if you find any issues please let me know. Thanks.
hi @nibtehaz , first of all, thanks for your response on this topic. I am a beginner to Deep Learning, and I have one question regarding measuring the performance of the MultiResUnet model. If I am not wrong It is common to use IoU score and Dice Score to measure the performance of the segmentation model. and F1 score , Precison, and Recall score for this classification model. So I'd like to know if there is any way we can calculate the F1 score , Precision and Recall from this MultiResUnet model ?
@nibtehaz for instance , to measure how accurate the model able classify ( or predict ) each pixel compare to the ground truth image pixel.
Hi @reachsak , I'm very delighted that you've liked my project. Don't worry being a beginner, we all start somewhere, hopefully pretty soon you'll be an expert.
Yes you're right we use IoU and Dice usually to assess the performance of segmentation models. However of you wish to calculate accuracy, recall, precision, f1 etc. you can do so.
The simplest way is to take the ground truth mask and your (thresholded) predicted segmentation mask. Then, you can use ravel() of numpy array, which will convert 2d images to 1d array. Now you have the predictions for individual pixels and the ground truth for the same. So you can compute TP, TN, FP, FN and get the metric scores from them.
You can also do this much simpler, just take the predicted and ground truth arrays obtained from ravel() and use the Scikit learn functions to compute accuracy, recall, precision and f1.
By this you'll obtain the result for a single image, do this for all the images and compute the mean to score the overall performance.
Hope this helps, please let me know if I can aid you further. Have a good day.
Hi @nibtehaz , Thank you so much for your attention and high consideration of the project issues and questions. I will be thankful if you send me the link of the Fluorescence microscopy Murphy Lab dataset which you use it in your paper. I can not find it throughout the internet, I need it to use it in my master thesis. please send it to send them to this Email: [email protected]
Hi @Ayanzadeh93 , I've just sent you a mail with link to that dataset. Hope this helps, please let me know if you require any further assistance. Best of luck with your MS thesis.
@reachsak you are most welcome. Please let me know If I can help you with something else.
@nibtehaz Thanks again sir for your attention, I am planning to use this model for my next image segmentation project but still stuck with the model evaluation part as mention above, if possible can you help me by including in the demo the code you mention above that will be able to compute the model Accuracy, Recall, Precision, and F1 score. or send the code to my email [email protected]
Hi , @nibtehaz ,I've managed to calculate the F1 , precision and recall score from your model but still have a few questions about the my results and the method i used.
Here is the function I used for the calculation , I also used the same y_true and y_pred parameters for the functions as you used for the Dice and Jaccad function. But I'm not sure whether by doing this will allow me to actually calculate the result for the classification between groundtruth and predicted images pixels. So I'd to know if this y_true and y_pred that you used actually represent the groundtruth image and predicted segmentation mask pixel ?


And regarding to the result , I'd like to know what is the different between the score we got when compiling and the one by evalutation. For instance the Jaccad and dice score while compiling are different with the one when evaluation. Can i use the metrics while compiling ( like the f1, precision , recall to measure the performance of the models )

Hi @reachsak , sorry for the delayed response, I had been distracted with a number of things. Yes the code you have there will actually compute the precision and recall of predicting the pixels. However, you should also note that it will be mean over all the pixels not over all the images. So you should be careful with the interpretation of the F1 score.
Also about your second query, the two values of dice and jaccard are different, because the first one is on the training data and the second one is the validation data.
Though using Keras backend is convenient and should be used, but for your cause I think it would be better if compute the precision, recall and f1 using Sklearn functions, as they would give more control to you. If you wish I can share a simple implementation of that with you.
Again apologies for this late response.
Hi @nibtehaz , thanks very much for your response . actually my main purpose is to evaluate how well can a model predict an images compare to its original ground truth with precision and recall score ( which If I am wrong lead to a kind of pixel classification task) . And Regarding your above Comment , I’m not quite understand by the term “ mean over all pixel , not over all image “ , so have my the methods I used above actually Calculate the precision and recall score that the model predict compare to its origami ground truth ?
And regarding to the metrics while training and validation, may I know which one do you think is more important in evaluating the performance of the task of this kind ?
It’ seems that my above code only calculate the metrics while compiling. ( training ) I’ve actually tried to modify your code for calculating the metrics while fitting the model but haven’t managed to. And yes , It’d be very helpful if you help me with your implementation on this task. Thanks lots for your time :)
Hi @reachsak , yes I understand that you wish evaluate the performance using Precision and Recall.
About my mean over pixels and mean over images, I think it would be easier to understand with an example
Let us assume you have 5 images
image 1 -> has 180 pixels with value 1 (ground truth) -> the model predicts 100 pixels (prediction) image 2 -> has 5 pixels with value 1 (ground truth) -> the model predicts 0 pixels (prediction) image 3 -> has 5 pixels with value 1 (ground truth) -> the model predicts 0 pixels (prediction) image 4 -> has 5 pixels with value 1 (ground truth) -> the model predicts 0 pixels (prediction) image 5 -> has 5 pixels with value 1 (ground truth) -> the model predicts 0 pixels (prediction)
The codes you have done, i.e. average over pixel would compute as follows: TP = 100 TP + FN = 180 + 5 + 5 +5 +5 = 200 so Recall would be = 100 / 200 = 50% using your function
But it is a false perception as you can see that predictions for 4 images are completely wrong.
On the other hand if you computed the average over the images it would have been like:
Recall Image 1 = 100 / 180 = 55.55 % Recall Image 2 = 0 / 5 = 0 % Recall Image 3 = 0 / 5 = 0 % Recall Image 4 = 0 / 5 = 0 % Recall Image 5 = 0 / 5 = 0 %
Now if you compute the average it would be 11.11 %. This shows the actual outcome.
I hope you understand what I've tried to mean by this
And regarding to the metrics while training and validation, may I know which one do you think is more important in evaluating the performance of the task of this kind ?
It should always be the metrics of validation data. as you can understand training metrics may eventually overfit and obtain high scores.
It’ seems that my above code only calculate the metrics while compiling. ( training ) I’ve actually tried to modify your code for calculating the metrics while fitting the model but haven’t managed to. And yes , It’d be very helpful if you help me with your implementation on this task. Thanks lots for your time :)
This is because in the training function most likely you haven't added the validation_data, if you added that it would have also be displayed. You may have a look at this link https://keras.io/models/model/#fit
About changing my code, you should just add the metric computations in the evaluateModel function. Please have a look at that, if you face issues I'll try to help you with implementations. Please provide me your email id if that is needed
Hi , @nibtehaz here is what I add earlier today to the evaluteModel fuction aim to caculate the validation metrics of the precision and recall , there is an error (below)

 Here is my email address : [email protected]
Hope you can help me with the implementation of this task.
Here is my email address : [email protected]
Hope you can help me with the implementation of this task.
And yes, thanks for your clear explanation above about the mean over pixel and image part , it's really helpful
Hello all, Allow me ask, If my dataset has 3 classes(green, cyan color and background), can we use this code and how do we fix? Thanks.