Logan
Logan
@zhenghax > Hello community, has this issue been resolved? or what's the workaround? I believe this has been fixed: https://github.com/chroma-core/chroma/issues/364
> awesome, has it been converted to .ckpt stable diffusion format? It's fundamentally a different kind of thing. Stable diffusion works by taking `text--CLIP--> text embedding --SD--> image` This model...
This is the critical code: https://github.com/huggingface/diffusers/blob/bce65cd13a60c6f4ac7d3cab1a74d061964b55cd/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_image_variation.py#L173-L196 For the rest of the pipeline we would want to use webui's standard image-generation code
Another obvious extension is you could imagine like ` AND "text prompt"` similar to how [Composible diffusion](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features#composable-diffusion) works with 2 text prompts
Okay, I maybe kind of have it working... but it looks real bad, so I probably implemented something wrong 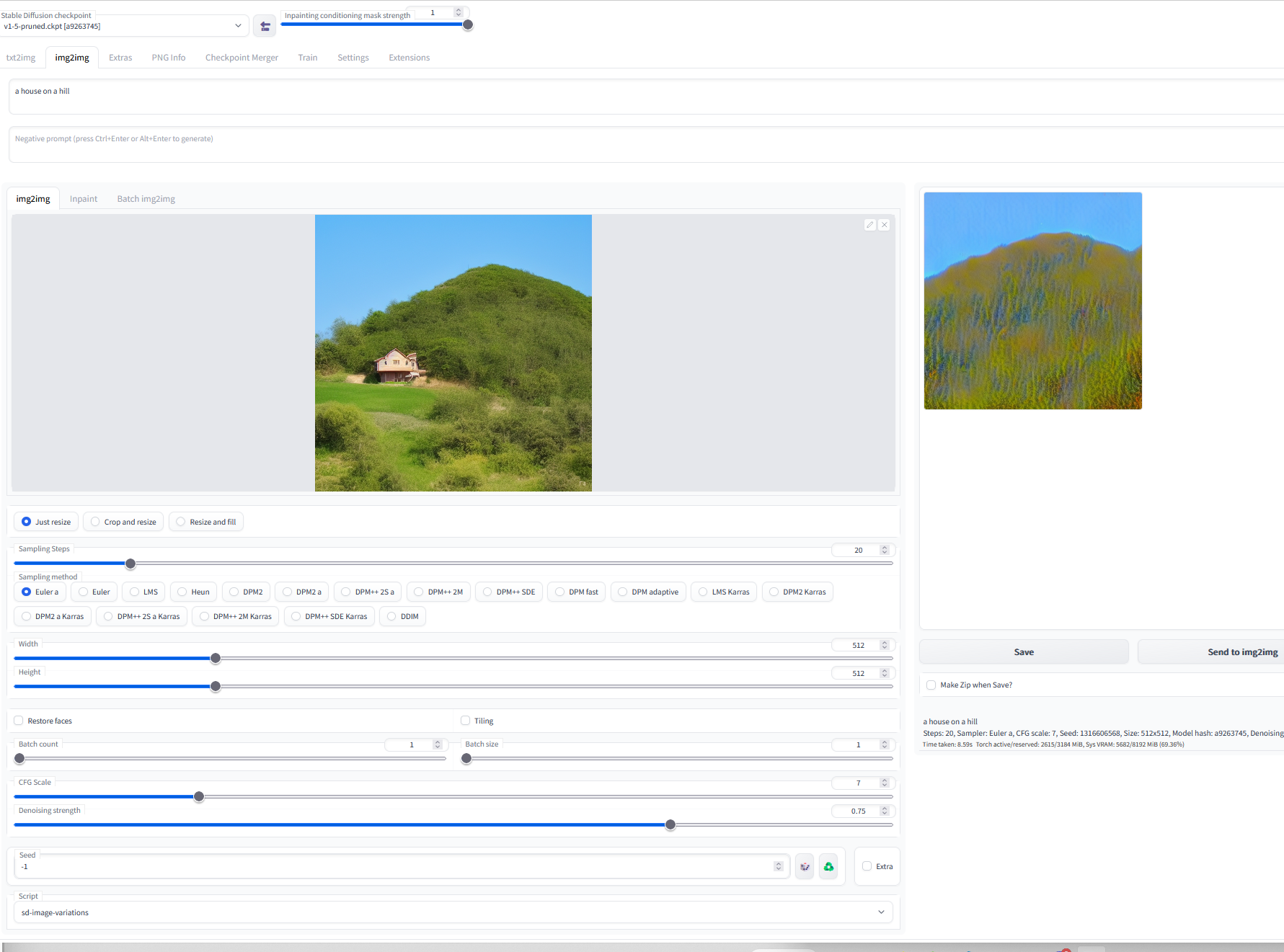 https://github.com/nagolinc/sd-image-variations-webui-plugin
@guwa1 Multiple-poses wouldn't actually be that hard to implement. You'd just have to imitate this block of code (**https://github.com/dreamgaussian/dreamgaussian/blob/main/main.py#L174-L185** ) with the other images.
Okay, I tried loaded the multi-views generated by https://github.com/liuyuan-pal/SyncDreamer#syncdreamer into dream-gaussian. Can't really tell if there's an improvement or not https://github.com/dreamgaussian/dreamgaussian/assets/7775917/c058d864-b8c9-4233-836c-6b1eb470ee43 code, if you want to try it out https://github.com/nagolinc/dreamgaussian/tree/mv...
@jeffchuber I had this error until I added these two lines to my code: https://github.com/nagolinc/toypedia/blob/f57b8b7015f4e3bd26c71c611a8b63c7936a265c/flaskApp.py#L30-L31
It would be even cooler if you could use https://huggingface.co/camenduru/one-shot-talking-face to generate videos of the characters talking like I do here: https://github.com/nagolinc/AnimeBuilder/blob/main/animeCreator.py#L565-L603
I've just been projecting the original image onto the front of the mesh ``` def projectImg(mesh, img_path, save_path="static/samples/",foreground_ratio=0.85): modified_img_path img_path # Load the modified image to get its size for...