blog
 blog copied to clipboard
blog copied to clipboard
Your internal mediocrity is the moment when you lost the faith of being excellent. Just do it.
4月11号来自同程的面试题: [neargle](http://blog.neargle.com/) 和张维垚 先是根据项目详细询问了webshell检测,然后以及其他的问题。没想到的是问的还问了git的使用,有点意外。 1. nmap 的扫描方式? 怎么判断服务器信息,哪些常用命令? banner之外呢? > 暂时PASS 2. 扫描服务器(CDN背后)得到的端口一定是一台服务器上的吗? > 不知道,这个的话,我今天想想其实可以不在一个目标服务器上的。但一定在当前托管的网站上,要不然lamda服务器,serverless服务器? 仍需深入了解 3. 如何获取到托管在服务器背后的真实ip. > 以前在网上看到说是多地ping,其实POC-T的bingc插件或者根据子域名ip,然后扫描整个子域名的网段,也是能获取的。 4. 哪些子域名获取方式. > `dnsdumpstar`, `Sublist3r`, `visualsitemapper`,`layer子域名挖掘机`,`certstream`(https的比较好,缺点是有可能有失效的), `nmap`的dns-enum脚本也可以, `搜索引擎`的site方式。总的来说就是枚举,解析记录,数据库。 5. DMZ以及办公网络安全知识,如何建设办公室网络安全,内网安全?...
ipynb文件在我的gist[点这里](https://gist.github.com/mylamour/b1700c0b22253dac66498fe4d01fa727),等到后期整理下,把`bitbucket`上我的机器学习笔记迁移过来, 本篇是 https://www.cnblogs.com/jasonfreak/p/5448385.html 的学习笔记 ```python # Learn from https://www.cnblogs.com/jasonfreak/p/5448385.html # Note And Tutorial # use `notedown features_engine.ipynb --to markdown --strip > xx.md` # notedown installed by `pip install notedown` %matplotlib...
# Create Keras Model ```python from keras.wrappers.scikit_learn import KerasClassifier def create_model(kernel_initializer='he_normal', optimizer='adam', activation='relu', dropout=0.5): inputs = Input(shape=(sequence_length,), dtype='int32') embedding = Embedding(input_dim=vocabulary_size, output_dim=embedding_dim, input_length=sequence_length)(inputs) reshape = Reshape((sequence_length, embedding_dim, 1))(embedding) conv_0 =...
京东面试题

4月3号,愚人节后的两天,也恰是清明的前两天。意外收到来自京东的面试,简历是3月28号投的,未曾想到能会通过筛选,面试官聊了一会,不出意外,并没有通过。自省之余,对其中的5道问题并不能很好的回答,因此予以记录 --- # 一面 1. 一般sql注入怎么发现触点的,从源码阐述sqlmap如何测试注入点的. 2. masscan扫描端口时靠什么检测,为什么这么快? 请详述. 3. 你写过哪些小工具,你为你使用过的工具做过什么修改. 4. 如何提高采用python编写的扫描速度,谈谈对GIL锁的了解. 5. 你觉得你发现的那个漏洞影响比较大. **Other** * 常见的web漏洞有哪些. * 有没有玩过硬件安全,研究程度如何. **Backup** 收货很多,面试官脾气很好,虽不曾相识,但十分感谢。保持学习,以免退步。 --- 二面和三面是一天,周四,4月19号。请了一天假,太阳很热。没想到的是夏初的时候,两盆绿植却要凋零了。熬过了秋冬春,却没赶得上盛夏。不过生命的尽头就是死亡,也没什么可悲哀的。早走晚走都是要走的。 # 二面 1. 反爬虫,如果是你如何进行反爬虫,如何绕过反爬措施。 使用无头浏览器被检测到了,如何绕过 2....
本来在看K-means (最最基础的聚类算法)和EM算法(具体看统计学习方法,此处就不列推导相关的了),在学习的过程中发现了Spectral Clustering的效果看起来更好。 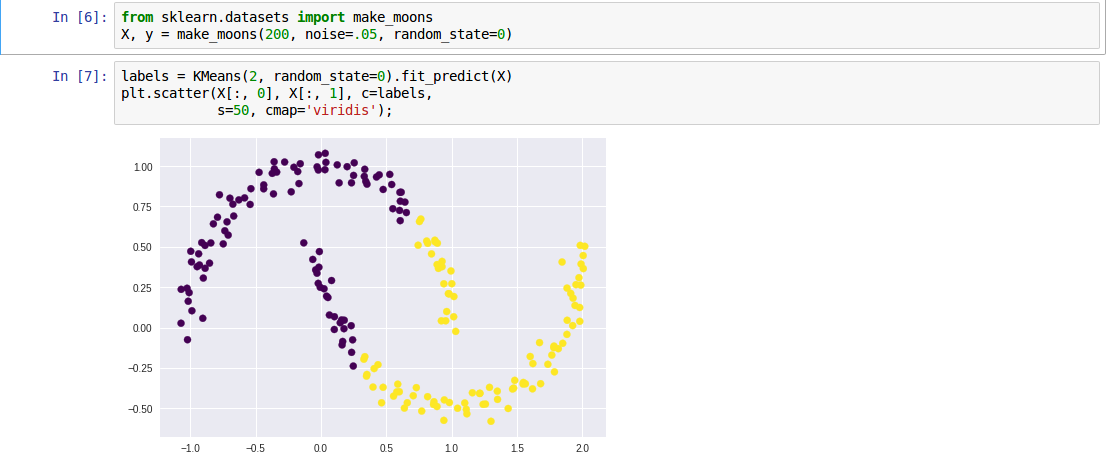 从该图中不难看出其聚类效果并不是很好,未能准确的将中间部分完全分开。于是乎看到了教程中提到的Spectral Clustering的方法,也就是下图中所使用的算法,可以看到已经能够将数据准确的分开了。 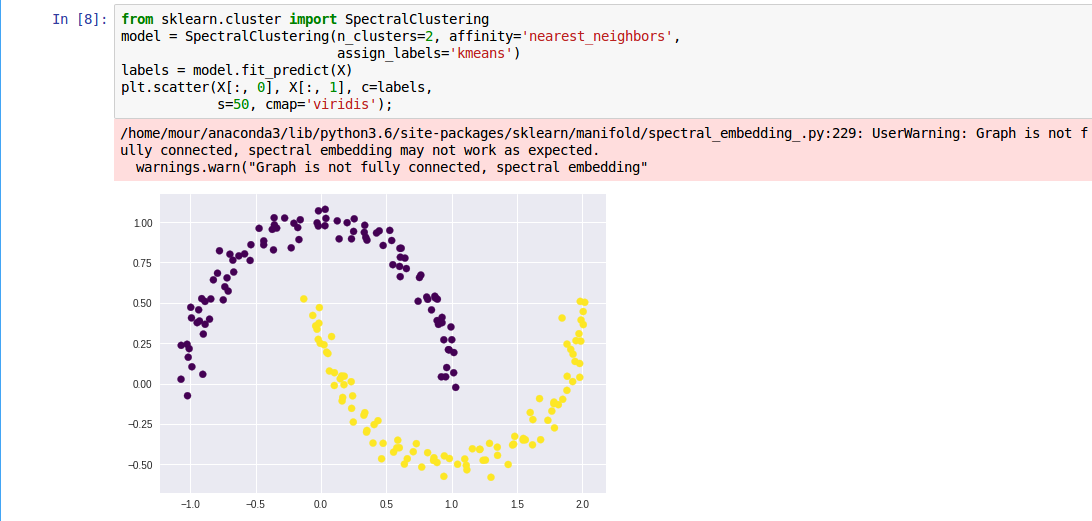 > 以上两图来自Python Data Science Handbook 5.11 教程 关于Spectral Clustering 算法,这篇估计是经典中的[经典](https://arxiv.org/pdf/0711.0189.pdf),但是还没有看。只是尝试了下其用于对已知的webshell进行聚类的效果。因为如果直接在对未知样本进行分类的时候 采取多分类,显然会导致精度下降很多,但是当有需求判断这个webshell是哪一种时,这个方法就可以一试。以下代码采用sklearn编写。 ```python import os, sys, re import logging import pickle import numpy as...
 这是一份OWASP TOP10变更对比,不过注入始终是NO.1,多出来个XXE,把错误配置,和授权绕过排名提高关注。 作为第一次阅读OWASP 的白皮书,除了系统化一下整个概念流程之后,个人觉得比较好的是最后的几个提问,比较值得思考(不要自己看着什么就是是是,要想一想): * What’s Next for Developers * What’s Next for Security Testers * What’s Next for Organizations * What’s Next for Application Managers   而我自己主要作为一个安全研发,和web渗透测试,比较关注前两个问题。...
进击的安全
 少时常看一兄灰鸽子种马,QQ钓鱼等。2013年拥有自己电脑,11月左右寻找各种工具包,后常深夜修仙,依旧苦苦无果。又因诸事繁杂,时有断续,却未敢停歇。自2016.11月起则专心此道,自忖无名,实当努力。鉴于自身所学繁杂,精通者少,故以此为记载,增删修补,当显凡人之努力,以期所获,更当砥砺前行,上下求索。。若有益于后来者,则幸甚至哉。 以下部分来自日志,有所残缺。另有残本两册如下: * [Web安全](https://_._._._.iami.xyz/) * [爬虫](http://spider.iami.xyz/) 2016.12.05: * https://www.zhihu.com/question/48187821 > 吊炸天的一行`js` > * www.jsfuck.com 2017.08.07: * 这一段时间在玩`LAN Turtle`, `L eonardo` ,还不错 2017.09.18: * https://github.com/kevthehermit/PasteHunter > 通过`Yara`规则扫描抓取`Pastbin`上的数据 2017.09.19: * https://github.com/Neo23x0/signature-base/blob/master/iocs...
最近写了一些`Powershell`脚本,然后列出一些`CMD`和`PowerShell`作为比较。使用`PowerShell`进行渗透的话,`github`上有许多不错的资源。 ## Windows Cmd * REG > ```cmd reg save HKLM\Security security.hive (Save security hive to a file) reg save HKLM\System system.hive (Save system hive to a file) reg save...
# 输入输出在哪里 * 在属性里 > ``` formaction action href xlink:href autofocus src content data ``` * 在标签里 > ``` ``` >> 没有标签制造标签也要上 * 在事件上 > ``` onload onunload onchange onsubmit...