blog
 blog copied to clipboard
blog copied to clipboard
Your internal mediocrity is the moment when you lost the faith of being excellent. Just do it.
# 前言 最近在反作弊过程中,涉及到前端后端测试。以及运维安全(我自己)的沟通。在开始这篇随笔之前,让我们先思考三个问题。ps:当然以下思考受限于个人工作环境,实非我之所愿。面临诸多问题,也不得不反思一二。尤其是公司当前面临着的诸多问题。 * 如何避免滥竽充数之人掺和进工作范围之内 * 如何在外部视角发现自己工作中的不足 * 怎么保持平和的心态应应对不正常的沟通过程 * 如何避免领导不懂技术的情况下却指手画脚 * 面临参差不齐的员工时怎么去尽量统一水平,不至于拖慢进度 * 如何在浮躁的行业或者环境里保持平心静气的继续学习 注意:心态一定要好,心态一定要好,心态一定要好。另外,这种合作是以实现功能为目的而临时的组合,所以大家都是平级关系。好好相处最好。不配合的话,再找他们leader。团队合作或者跨团队合作过程中很重要的一环应该有项目激励,但是在当前的情景下,并不具有该条件,谁让我只是个搞技术的呢...... 需求调研,安全研究,技术点demo,协调后端,协调前端,协调测试,效果分析。 判断涉及人员: Me, 后端一个,前端2个,测试一个 职责划分: * Me: 安全技术研究,demo实现,协调前后端实现,协调测试进行测试,技术上线后的数据分析对比 * 后端: demo技术点迁移修改后端代码,通过单元测试,对接前端 * 前端A: demo技术点迁移修改前端一系统代码,通过单元测试,对接后端...
Terrafrom多区部署虚拟货币的demo代码详见[这里](https://github.com/mylamour/devops-note/tree/master/terraform/cryptocoin) 目录结构如下:  只需将每个货币的部署方式和脚本实现放在对应的不同文件夹下,然后在main.tf进行每个模块的调用即可。当然,这只是为了钱包节点的同步,而不是为了挖矿。采用多区同步用于确保尽可能的使节点能够同步到最新的区块。当然还可以在每个区设置多台,然后多区部署。 ```hcl module "coinnode-us-east-1" { source = "coin/btc" region = "us-east-1" } module "coinnode-us-east-2" { source = "coin/btc" region = "us-east-2" } module "coinnode-us-west-1" { source =...
# 前言 这不是一篇基础教程。 先决条件: * docker : 容器 * k8s : 微服务容器平台 * kops : 自动化在aws上构建k8s * helm : k8s包管理器 * istio : 微服务管理平台 * datadog : 流量,日志收集分析平台(云) 完整流程: 使用...
## 安全无小事 到BTCC也快一个月了,入职以来的第一件事就是负责安全架构的设计和整个体系的架构。很忙,东西基本也有出来个眉目了。干了不少事,也没时间记录,抽空码一点吧。当然,此处特别感谢安全小飞侠师傅最初给的一些建议。思路吻合,非常不错。整理了一下,我在整个过程中需要面临的问题。 - [x] 基线加固和架构安全 - [x] AWS云安全 (Done, AWS配置策略检查,IAM权限划分,并依托AWS自身的Guardduty, WAF&shield,Cloudwatch等服务,建立监测报警体系,SNS推送) - [x] 内网安全(Doing, 已经做了划出单独网段,与市场,运营,客服分开。跳板机记录开发人员操作历史) - [ ] 开发SDL落地与安全意识培训 - [x] 流量监控和服务器状态监控分析(Doing,基于AWS的一套已经差不多了,但是目前计划要切k8s) - [ ] 日志聚集和分析 - [ ]...

 # 若批评无自由,则赞美毫无意义 诸事繁杂,许久未曾动笔,思及过往,时有许多感慨。虽未不满,却有忧思。自毕业以来,入职以来,亦数月有余。前前后后,亦有20周矣。择二三事记之,便于日后反思。 ## 理想中的工作方式 我理想中的工作环境是这样的,早上10分钟站会解决昨天遗留和今天预定, 上午修修bug,下午码会代码看会书,下班前花30分钟和结对编程的对象来个code review, 每周组内有一次技术分享,一次刷题。有问题能够快速得到解决,同时有所反馈,问题是否解决,有无引发新的问题。 这是之前几个人讨论关于一个小密圈应该怎么运营时我举到的例子,是希望以此做比对,在小密圈内也能采取这种形式,使分享更加集中和有目的性,以便于小密圈能够更好的营造出一种技术氛围。 ## 琐事记 * webshell检测 * 技术分享会 * 密码提取 * 华为全连接 * ___ ___ 检测 ? * 兰亭叙小聚和佘山五黑 ### 6.25-7.21...
睡醒突然想起上次要做没有做这个。每一关得到下一关的密码。 简单的就不记录了。还剩下3题没做。 记录下,去锻炼下身体。 ```sh grep -rnw "./*" grep -P '^=' -P perl regex ``` ```sh echo 5Gr8L4qetPEsPk8htqjhRK8XSP6x2RHh | python -c "import sys; print(sys.stdin.read().encode(\"rot13\"))" ``` 0-1 boJ9jbbUNNfktd78OOpsqOltutMc3MY1 1-2 CV1DtqXWVFXTvM2F0k09SHz0YwRINYA9 2-3 UmHadQclWmgdLOKQ3YNgjWxGoRMb5luK...
离职第一天,在家撸代码写博客,读读Write Up。 # 正文 IsolationForest 是周志华老师提出来的,简称iTree吧,是一种集成学习法方法,相对于LOF, oneclassSVM ,占用的内存更小,速度也快。原理就是构建树,但是因为不像决策树是有监督学习,根据label构建,这个构建过程是完全随机的。 构建过程: 从n中随机取出m条数据,作为训练样本,在样本中随机选一个特征,并在特征值范围内,随机选择一个值,然后划分。小于该值在左,其余在右。然后继续重复选择特征,划分到不能划分为止。或者树的高度达到一定高度。高度可以自己限制。构建完成之后就可以进行预测了。 预测过程是,把测试数据根据特征条件沿树到最后,记录该路径长度,以及走过边的数量。最后进行计算。然后分数越接近1,就越可能是异常点,低于0.5就是正常,0.5左右都是不明显的异常。 虽然上面说了这么多,具体也好理解,但是这篇论文还没有读。于是尝试此次atec的数据进行训练,代码如下: ```python import pandas as pd import numpy as np import itertools from sklearn.model_selection import train_test_split from sklearn.metrics import...
最近接到一批数据需要分析,当然常规的就是先用bs4解析处理,提取内容。然而很早之前就听说过了网页内容自动抽取,于是就尝试了下,`CxExtractor`来自[cx-extractor-python](https://github.com/chrislinan/cx-extractor-python) 目前我了解到的网页自动抽取方式有: * 基于行块分布 * 基于文本密度 本篇中尝试的方法为基于行块分布的。[CxExtractor](https://github.com/chrislinan/cx-extractor-python/blob/master/CxExtractor.py) 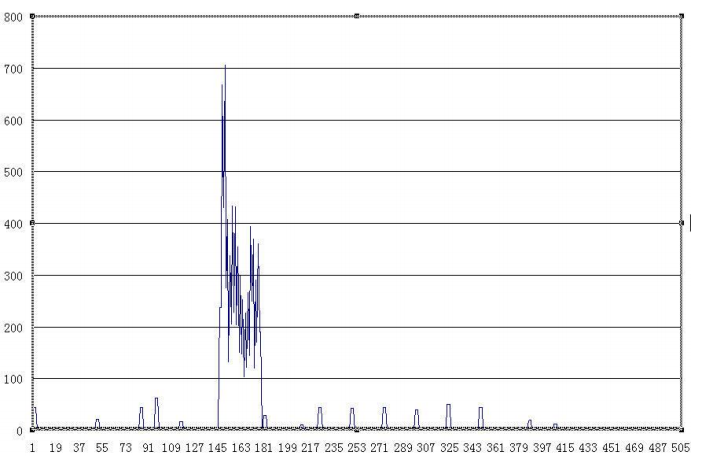 读取->提取->过滤即可 ```python import re import chardet import requests class CxExtractor: """cx-extractor implemented in Python""" __text = [] # __threshold = 186 __indexDistribution...
无论是在参加比赛,还是在实际工程中,把数据处理完之后,肯定不会只用一种算法进行测试,不可避免的采用多种算法进行比较。而[autoclf](https://github.com/mylamour/autoclf)就是这次在阿里风险支付大赛进行中,花了两天撸出来的一个简单框架。 目录结构为 ``` ├── [4.0K] clf │ │ │ ├── [4.0K] nn │ ├── [4.0K] data │ ├── [4.0K] pipe │ └── [4.0K] saved ``` `clf` 目录下是常见的或者自定义的算法, 而`nn` 目录下是自定义的深度学习算法,和`sklearn`接口绑定的,自定义的算法是以类的形式存在的,只需要实现`fit`,`score`,`predict`即可,但是如果自己的`fit`使用了 `sklearn`的训练,就无需再自定义`score`,`predict`了。例如这样:...