modAL
 modAL copied to clipboard
modAL copied to clipboard
Performance on MNIST doesn't seem great
When comparing to random sampling it does not seem to give significantly different results. I would have expected the curve to be much higher for active learning. Potentially the defaults aren't great?

learner = ActiveLearner(
estimator=RandomForestClassifier(random_state = 1234),
X_training=start_X,
y_training=start_y
)
Yes, the default maximum uncertainty sampling has some drawbacks. Its performance can be affected by the bias of the classifier. It also heavily depends on the initial data. How did you obtain start_X?
In any case, in the examples you can find a script where the shape of a square needs to be learned. The uncertainty sampling performs much better there, as you can see:


So start_X was taken as a randomly sampled stratified collection of 10 samples (one for each class). The rest of the training set was then used as the pool and the test (validation) set was used to score the models
start_X, rest_X, start_y, rest_y = train_test_split(train_X, train_y,
test_size = train_y.shape[0]-10,
stratify = train_y,
random_state = 2018)
print(start_X.shape, rest_X.shape)
(10, 784) (59990, 784)
The full self-contained notebook for reference: https://nbviewer.jupyter.org/gist/kmader/7883dce3cb7c430d4c655ede66541dfd
Also on Fashion MNIST using 3 different sampling (margin, entropy and uncertainty), it doesn't seem to reliably do better than random sampling.

I think that the issue is not in the library, but simply that the basic methods doesn't perform well on a large dataset like MNIST. There are several reasons for that, for instance a basic uncertainty-based sampling method tends to select data from the same location in the feature space, which might lead to dataset bias.
Wow, thanks for the quick reply. Yes, you may be right. I am running some experiments using random and min_margin sampling strategies, but I intend to use the back method as well and see what happens.
From running the straightforward pytorch_integration.py example without modifications (i.e. with the provided Neural Network), my accuracy curve doesn't seem to exhibit an overall increasing trend (even discounting the unusual drop, the model doesn't seem to be improving much)-- is this expected? (Asking because I also implemented active learning with modAL on my other dataset and the curve looks very similar to this one, so trying to figure out if it's a mistake on my end)
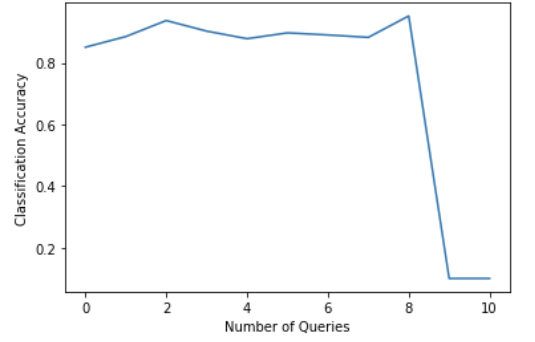
@michelewang Sorry for the late reply! With uncertainty sampling, no increasing trend in accuracy can indeed happen. In pytorch_integration.py, 1000 random instances are selected and each subsequent query adds 100 more. The issue with uncertainty sampling is that the queries can become concentrated to a rather small area of the feature space. (An extreme example would be to only query from a single class.)
However, the drop is quite unusual, I haven't figured out why that happens, but I also haven't been able to reproduce this as well.
Hi @cosmic-cortex , no worries! Thank you for your explanation, I really appreciate the response. I agree, it might be possible that because the initial seed set is randomly selected, if those are biased somehow, the model might not improve as much.
I wonder if the drop in accuracy is because pytorch_integration.py uses a NeuralNetworkClassifier rather than the RandomForestClassifier. Do you know if modAL works well with neural networks too? I am planning to use modAL for an undergrad senior thesis research project to segment images (likely using a CNN) so I wanted to see if it'd work with the MNIST dataset first... I have the code I used to produce the above graph in this colab notebook. Thank you again for making this + for your response!
modAL works with neural networks as well, but the issue is that most of the implemented query strategies were developed for classical machine learning methods, such as SVM. When confronted with a massive dataset and a neural network, a baseline sampling strategy such as uncertainty-based sampling does not perform well.
I have relased modAL around January 2018, and at that time, I was not aware of a lot of research in active learning regarding neural networks. So, I didn't implement any query strategy that was specifically developed for deep learning. Since the release, a lot was discovered and previously niche topics became popular, like Bayesian active learning. (See this paper and other works of Yarin Gal.) Unfortunately, by the time I learned about these works, I had little time to add new features to modAL, as this would have required almost a complete rewrite. I think that doing this would require 100% of my attention, which I cannot do now :( (I have left research since then and founded a startup in a different direction.)
However, there is a relatively new book called Human in the Loop Machine Learning by Robert Munro, with the accompanying code here: https://github.com/rmunro/pytorch_active_learning It contains a chapter on semantic segmentation, probably it can give you an insight into what query strategy might work. If you find one that works, you will be able to implement it in modAL and use it with PyTorch models. Let me know if you find some concrete strategy and I'll help!
@michelewang did you see this Deep Bayesian Active Learning implementation: https://github.com/damienlancry/DBAL
This is also based on the modAL software. This might fit your task as well!
Apologies for the late response!! Thank you @cosmic-cortex and @pieterbl86 for directing me to these resources!! I think I'm going to use part of the DBAL implementation for my project!