adventofcode
 adventofcode copied to clipboard
adventofcode copied to clipboard
Add entry-point
This was actually fairly trivial - on most of your puzzles it just worked. The few ones that failed are for silly reasons (e.g. in https://github.com/mjpieters/adventofcode/blob/master/2017/Day%2004.ipynb it has printed "Part 1:" for both parts).
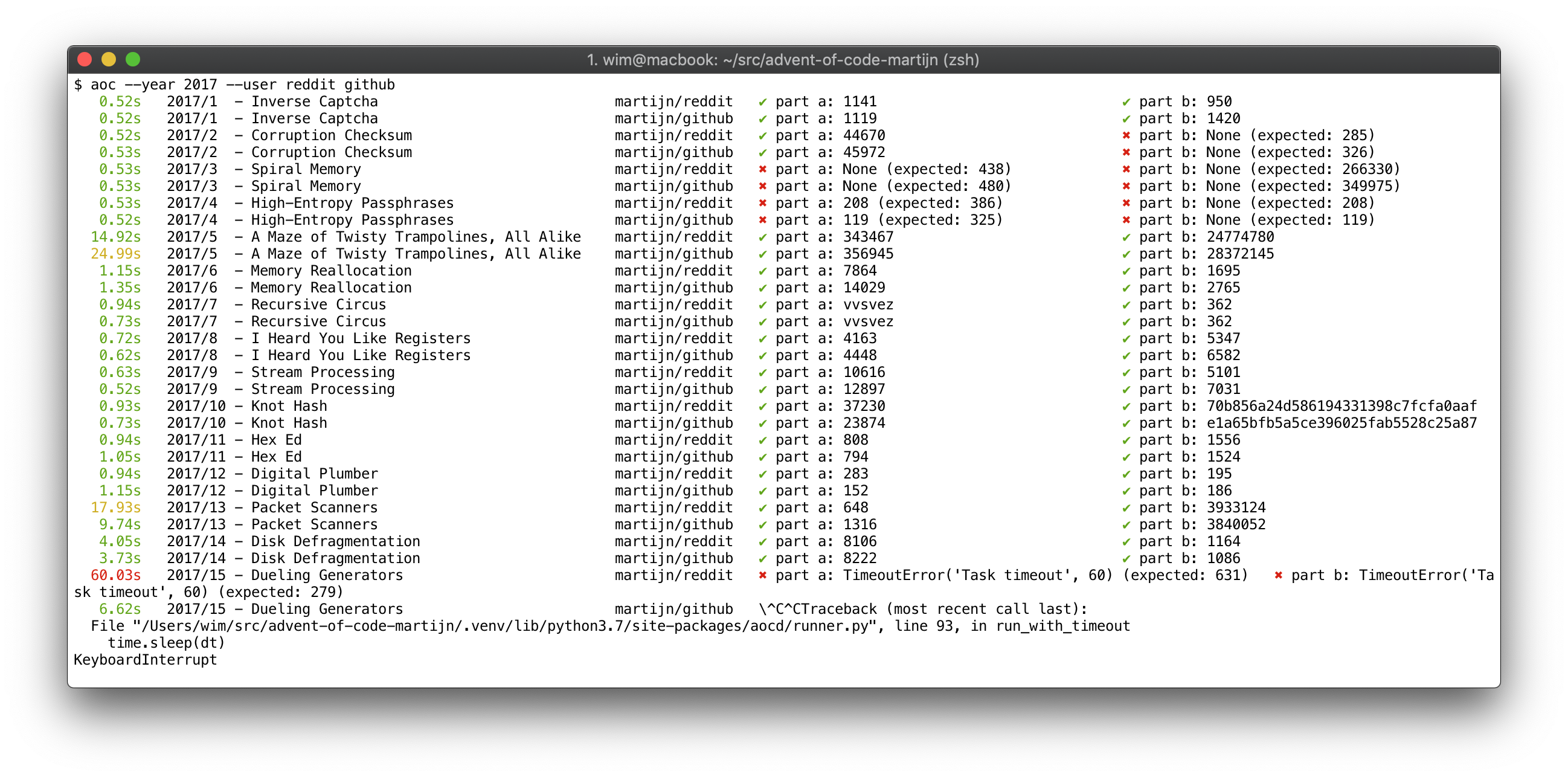
@mjpieters I looked at this today, but can not find any public API to execute the cells. It seems it's the IPython display hook - that actually executes them. So, I don't think your idea of using nbformat is going to work?
I think you misunderstood. You currently parse out the result from a subprocess call to nbconvert. I want you to replace that with using nbformat, so that no extra process is needed and the result will be more reliable. So still parse text, but limit what text you are parsing and how you obtain the source.
@mjpieters I've added a commit to avoid subprocesses, but it complicates things quite a bit - what do you think? There is a bit more mucking around now, because it's no longer easy for the import knothash to be resolved.
Ah. No. There definitely is a misunderstanding here. Sorry if this wasn't clear, but notebook files already contain the resulting output. All that nbconvert does is take the stored contents of the notebook format and output the information in a different form. No cells are executed. The nbconvert script is nothing but a wrapper around nbformat to read the data, then some output formatter that operates on textual data.
See https://gist.github.com/mjpieters/46fdf415a2807b3568b4f6f64ef81013 for what I had in mind. Just looping over the cells, if the cell is a code cell, loop over the outputs that cell produced. If the output is a stdout stream, look for Part 1: and Part 2: strings. No exec() required.
I don't know at this point what advantages there would be in actually executing the code again for your display to work best? Do you want to track timings?
Something to consider: I use Python 3.7 and its features, so you can't always execute my notebooks on earlier Python versions. Just grabbing the text is probably much more permissive.
It is tracking timings, yes. If you look in the screenshot in the first post, you will see wall time in the leftmost column. And it is verifying results against multiple input tokens. Grabbing the pre-computed output text would be entirely pointless.
I'm going to close this PR, because while I can see that it'd be nice to compare timings with loads of other repositories, the benefit isn't great enough for me to have to figure out the constraints every year to keep this working.
The need to look for magic strings to blacklist cells is just a bit too fragile, and I'd have to keep the minimum Python version updated too. That's more head-ache than I want to deal with for a bit of end-of-year coding fun.
Sorry!