torchsparse
 torchsparse copied to clipboard
torchsparse copied to clipboard
[BUG] spnn.Conv3d cuda and cpu the inference results are not comparable
Is there an existing issue for this?
- [X] I have searched the existing issues
Current Behavior
我正在尝试移植 spnn.Conv3d,但是发现cuda 版本和cpu 版本的推理结果是有差异。
spnn.Conv3d的参数如下: self.conv3d=spnn.Conv3d(4, 32, 3,1)
Expected Behavior
spnn.Conv3d的参数如下: self.conv3d=spnn.Conv3d(4, 32, 3,1)
他们直接的差异如下: tensor([[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000], [-1.1202, 2.1639, 1.7971, ..., 0.4754, 0.0078, 1.6174], [ 0.2442, -1.3255, 0.1495, ..., 0.2552, 0.7134, -1.8028], ..., [-0.4101, 0.6871, 0.0756, ..., -0.3250, -0.9230, 1.2904], [-0.1787, 0.5095, -0.9485, ..., -0.6150, 0.3025, -0.8932], [ 0.4376, 0.0704, -0.2781, ..., 0.0972, -0.5459, 0.4709]], grad_fn=<SubBackward0>)
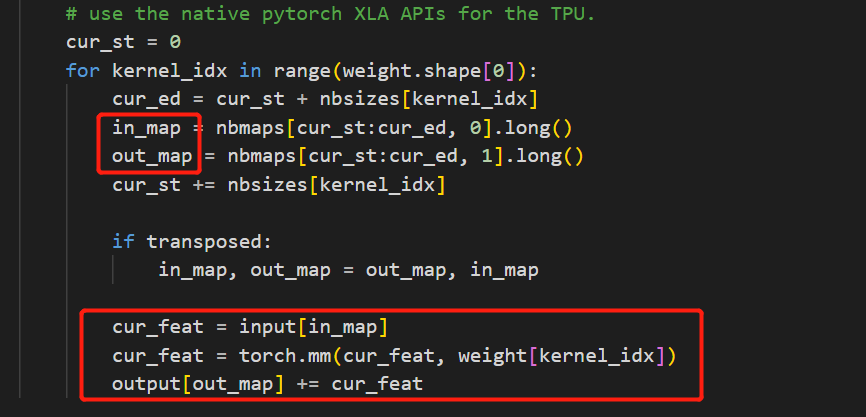
cpu 版本的部分源码如下:
cur_ed = cur_st + nbsizes[kernel_idx]
in_map = nbmaps[cur_st:cur_ed, 0].long()
out_map = nbmaps[cur_st:cur_ed, 1].long()
#print((in_map==out_map).sum())
cur_st += nbsizes[kernel_idx]
if transposed:
in_map, out_map = out_map, in_map
cur_feat = input[in_map]
cur_feat = torch.mm(cur_feat, weight[kernel_idx])
output[out_map] += cur_feat
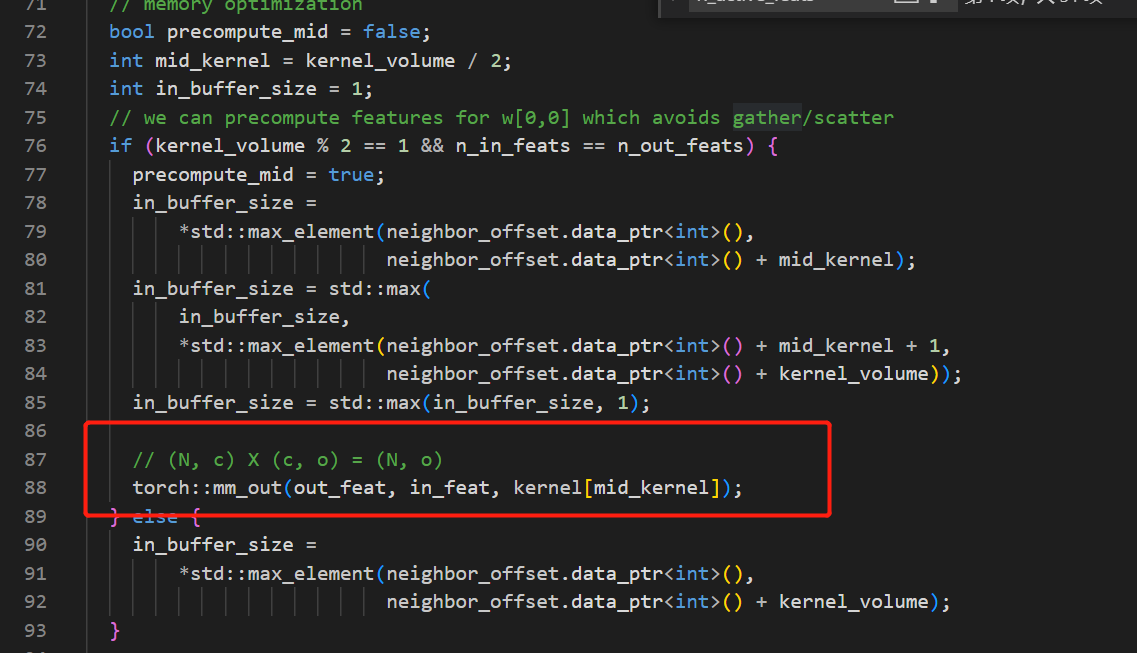
gpu 版本的部分源码如下: // we can precompute features for w[0,0] which avoids gather/scatter if (kernel_volume % 2 == 1 && n_in_feats == n_out_feats) { precompute_mid = true; // (N, c) X (c, o) = (N, o) torch::mm_out(out_feat, in_feat, kernel[mid_kernel]); }
我理解是做了一个in_map与out_map 相等时的对input 数据重排的优化,但是直接使用 torch::mm_out(out_feat, in_feat, kernel[mid_kernel]) ,如果in_map与out_map不相等,out_feat的结果也会受到影响。
Environment
- GCC:
- NVCC:
- PyTorch: 1.10.0
- PyTorch CUDA:
- TorchSparse:1.4.0
Anything else?
Thanks for reporting this issue! Could you please provide a minimal code snippet for us to reproduce this bug?
I have a very simple example to reproduce:
device = torch.device("cpu")
c2 = torch.randint(0, 10, (32, 3,), dtype=torch.int32, device=device)
f2 = torch.rand(size=(32, 1), dtype=torch.float32, device=device)
data = sparse_collate([
SparseTensor(
coords=torch.randint(0, 10, (64, 3,), dtype=torch.int32, device=device),
feats=torch.rand(size=(64, 1), dtype=torch.float32, device=device)
),
SparseTensor(
coords=c2.clone(),
feats=f2.clone()
),
])
data2 = sparse_collate([
SparseTensor(
coords=c2.clone(),
feats=f2.clone()
),
])
model = nn.Sequential(
spnn.Conv3d(1, 1, kernel_size=2, stride=1),
spnn.GlobalAvgPool(),
).to(device)
res2 = model(data2)
res2_alt = model(data)[-1]
assert torch.allclose(res2, res2_alt)
Note that the example works on cuda.
Since TorchSparse has been upgraded to v2.1.0, could you please attempt to install the latest version? I will now close this issue, but please don't hesitate to reopen it if the problem persists.