deep_preset
 deep_preset copied to clipboard
deep_preset copied to clipboard
The input of Encoder T
Thanks for your excellent work! I doubt why the preset predictor needs the input of X( content image). Looking forward to your reply.
Thanks for the interesting question.
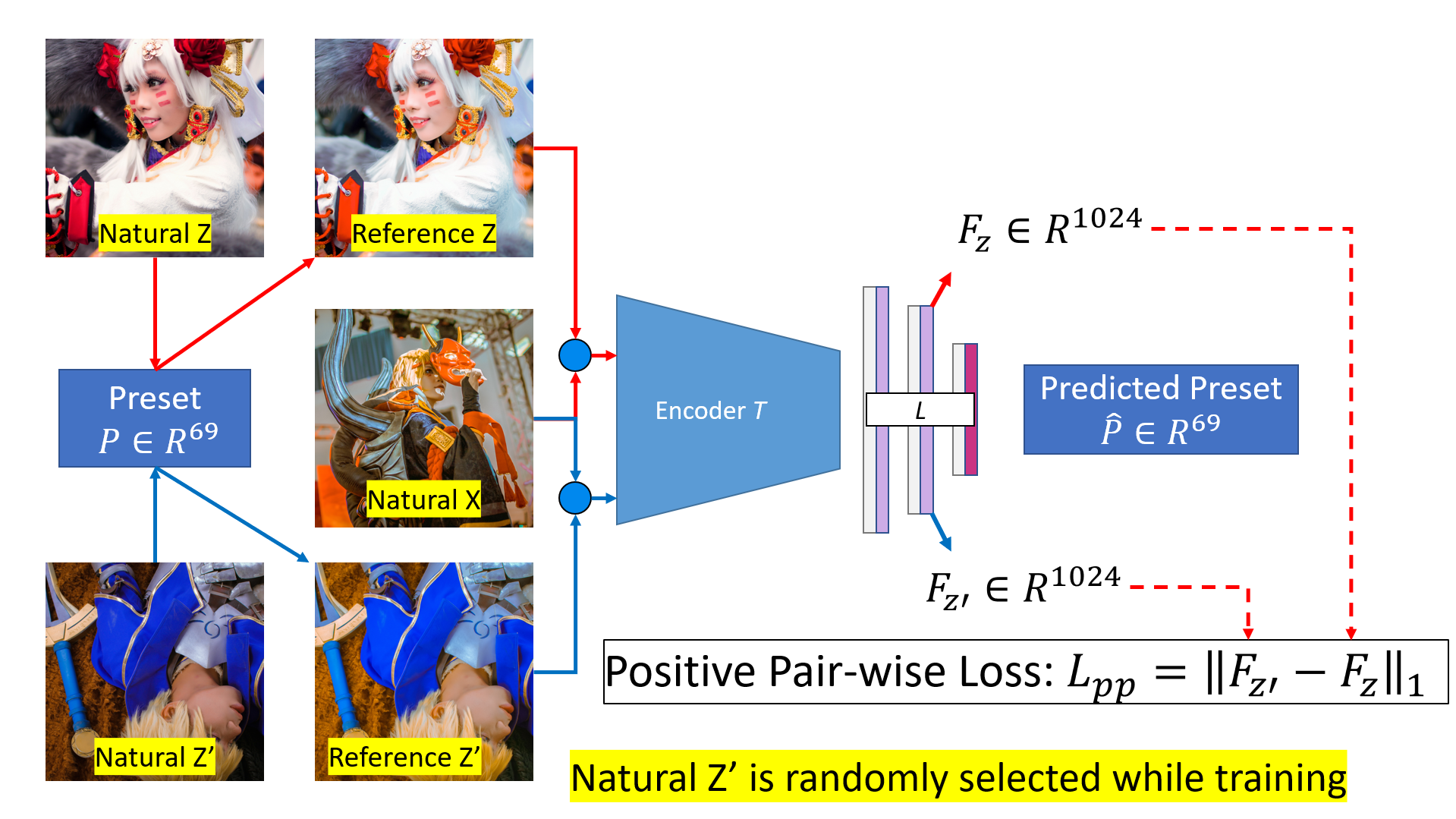
Honestly, the preset predictor does not need the content image X to predict the applied preset as X is always "natural". This is a better way to predict presets. Also, we can use features extracted from a single reference image for stylization. This totally can work.
Nevertheless, I want the encoder T to learn the color transformation from a content image to a reference image so that the extracted features work the best for the given content image (encoder T is aware of the content image). Besides, this design will enable positive pair-wise loss (Given content image X and 2 reference images Z and Z' retouched by the same preset P, the color transformation T(X, Z) should be similar to T(X, Z')).
I hope this will help you. Love to hear if you have any further questions.