feat(core): allow JsonType to use a stable JSON.stringify algorithm
fixes #3583
We introduced an option on JsonType to allow user to choose between speed or better serialization.
I'm not sure if the option is required, or if stable stringify should simply be the only option because it's more robust ?
I'm not sure either of what you prefer as a default: slightly more speed or less diffs. In doubt, we kept the the old behaviour by default.
Feel free to decide what option is best.
This pull request introduces 1 alert when merging 3341e63b1414e2d770354d5c8b7fe056179c0a93 into 9d5d457e4bcf67b03c4c0982b838163b382bf3b8 - view on LGTM.com
new alerts:
- 1 for Unused variable, import, function or class
Can you prepare some benchmarks so we know how much slower this solution is? If its fast enough, I dont mind doing this by default, but it would have to be very close to the native implementation.
I am not sure if the type constructor is the right place for this (I do understand this is the "least modified code path"), a global config option would be definitely a good idea, and a property level option to have fine grained control. Because in generall you dont need to work with the type instance, a type: 'json' (or type: t.json) will work the same here, and I dont want to force users to instantiate the types for this.
Maybe something like this?
@Property({ type: 'json', stableStringify: true })
object: { foo: string; bar: number };
That way we could easily control it globally too, I guess if the user wants it stable, they will want to have it stable for all the JSON properties.
I also dont mind having the constructor option in JsonType, I'd like to have it available in other ways too.
Codecov Report
Base: 99.84% // Head: 99.62% // Decreases project coverage by -0.21% :warning:
Coverage data is based on head (
3341e63) compared to base (b23f015). Patch coverage: 15.15% of modified lines in pull request are covered.
Additional details and impacted files
@@ Coverage Diff @@
## master #3584 +/- ##
==========================================
- Coverage 99.84% 99.62% -0.22%
==========================================
Files 211 212 +1
Lines 13174 13207 +33
Branches 3053 3062 +9
==========================================
+ Hits 13153 13158 +5
- Misses 21 44 +23
- Partials 0 5 +5
| Impacted Files | Coverage Δ | |
|---|---|---|
| packages/core/src/drivers/IDatabaseDriver.ts | 100.00% <ø> (ø) |
|
| packages/core/src/utils/stableStringify.ts | 3.57% <3.57%> (ø) |
|
| packages/core/src/types/JsonType.ts | 94.44% <80.00%> (-5.56%) |
:arrow_down: |
Help us with your feedback. Take ten seconds to tell us how you rate us. Have a feature suggestion? Share it here.
:umbrella: View full report at Codecov.
:loudspeaker: Do you have feedback about the report comment? Let us know in this issue.
Can you prepare some benchmarks so we know how much slower this solution is? If its fast enough, I dont mind doing this by default, but it would have to be very close to the native implementation.
Will do
I am not sure if the type constructor is the right place for this a global config option would be definitely a good idea, and a property level option to have fine grained control. That way we could easily control it globally too, I guess if the user wants it stable, they will want to have it stable for all the JSON properties.
yeah, makes sense 👍
to add some thoughs about json fields before doing more:
-
going though strings to check for diffs may not be the best way.
- a custom
deepEqualmade for ORM would be better / faster / use less memory when most diffs ends-up without changes- lodash and other ones are both too complex (support dates) and wrong (they compare the number of keys, which incorectly deals with undefined
{a:1, b:undefined}and{a:1}should be equal under a comparaison diff.
- lodash and other ones are both too complex (support dates) and wrong (they compare the number of keys, which incorectly deals with undefined
- a custom
-
sometimes, I think I'd also prefer to use ref equality (===) instead of real diffs, because I know my objects will only be replaces, not modified. this is unsafe, and should totally be behind a "I know what I do and will not complain when it turns out I was wrong in my assumptions", but it is massively faster.
- should there be an option for json object to also
Object.freezethem, especially when === comparaison is active (this would catch real-life bugs for specific needs, just had to quickly debug that in my project yesterday, I had one field that needed a stable stringify compare, and an other that only needed a === comparaison)
- should there be an option for json object to also
-
should there a way to specify diff strategy on Types, i.e.
ReferenceEquality(or 'StrictEquality') |==(or 'Equality') | 'ViaDBValue', are there mutually exclusive "axis" here that would deserve a different strategy configuration -
would it makes sense to allow use to use hints at the compare change time, something like
computeChangeSets({ strategy: { BookEntity: {SomeJsonField: 'StricEquality' }} )orcomputeChangeSets({ useStricEqualityFor: ['Entity.Field']] }). This is probably not the lowest hanging fruit for perf / memory usage optimisation
@B4nan the perf impact is massive for my use-case, if used everywhere !
🔴 this should not be merged as is 😨
👉 One big problem is that registering managed entities seems to also serialize JSON values pre-emptively 😨
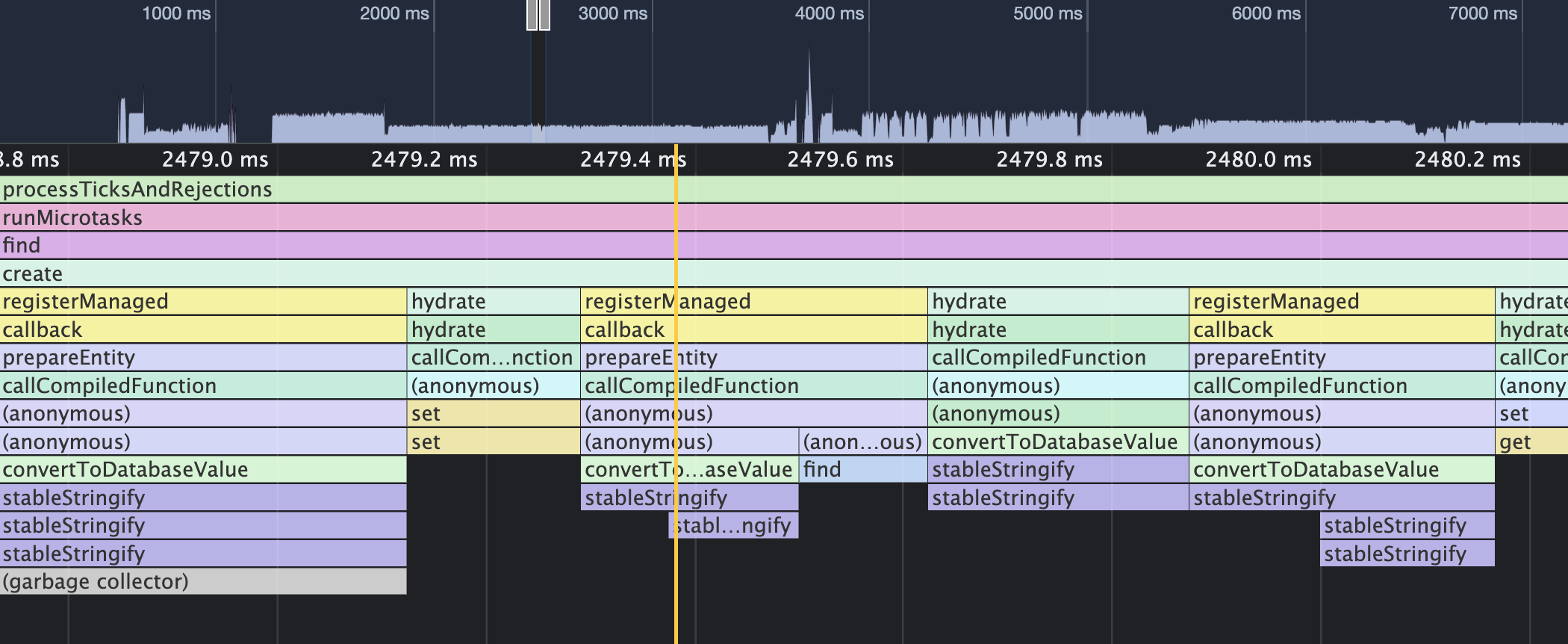
also, in my random current use case, >90%of json fields of my loaded models would be perfectly fine if compared as references, which I don't know how to do with current type abstraction.
(side note: all those little perf problems really seem easilly fixable. I have a ~150seconds script, where most of the time is just MikroORM doing things => early profiling show quick win everywhere, despite the code already beeing very clean; I know you probably have many other things to do, but I'd really like to help optimize mikro-orm further ! Your code is really clean ! :)
@B4nan your precisions have been noted. I'll need to take a couple days to dive deeper in the Mikro ORM codebase. An approximative bench : https://jsbench.me/x1l94p0qvx/1 (TLDR: 60% slower)
In any case, @rvion profiling proves that more work is required. I'll get back to you.
also, in my random current use case, >90%of json fields of my loaded models would be perfectly fine if compared as references, which I don't know how to do with current type abstraction.
Maybe for your use case, the go to way shouldn't be replacing references, but object mutation instead and there you can't just compare references.
👉 One big problem is that registering managed entities seems to also serialize JSON values pre-emptively 😨
Yes, that's how it works, we need to compute the state that is later used for changeset computation. And due to possible differences in the input (based on differences when using the joined loading strategy mostly) we need to serialize the entity instead of using the data that came from database.
I think we should add the compare method to the Type interface, that would allow you tu compare by reference, and it would be explicit.
Indeed the alternative to this could be smarter diffing, so instead of handing custom serialization, we would just make sure the values are same regardless of the order of keys in objects. And if we have this new compare method, we could use it to compare JSON values via compareObjects method we already have (or probably via the generic equals method instead as JSON can store arrays and raw values too, not just objects).
Maybe for your use case, the go to way shouldn't be replacing references, but object mutation instead and there you can't just compare references.
yeah, especially since it's impossible to hack around field order, since postgres will not preserve ordering on update like node does. But since node preserves the field oder from postgres, I went with Object.assign(entity.jsonField, newJsonField) so JSON.stringify() is similar, since entity.jsonField field order will remain unchanged.
your proposal to allow custom way to compare, without having to serialize first the fields would indeed solve all my problems.
for this specific entity, I'll go with a custom compareObject function, to skip the double json serialization (at fetch and at compare time)
And for for some of my other entities (with hundreds of thouthands of instances loaded in the EM in this very specific example), some of them have json fields known to be frozen and only assignable by reference, I'll go with an even simpler reference comparaison, thus saving seconds of runtime