cmc-csci181
 cmc-csci181 copied to clipboard
cmc-csci181 copied to clipboard
increasing batch size results in not learning
This questions concerns #7 in hw6. I trained my model with the command
$ python3 names.py --model=rnn --learning_rate=5e-4 --optimizer=adam --num_layers=2 --hidden_layer_size=128 --gradient_clipping --batch_size=1
and everything works. However, when I set --batch_size=2, the accuracy is hovering around 5% and clearly not improving I've checked over my code several times (I'm pretty sure the str_to_tensor function is correct, but there may be something wrong in the training loop) and tried printing values, which seems to be reasonable. I'd appreciate any directions to proceed?
I also found a similar problem of hovering around 5% with similar parameters but using the adadelta optimizer. This was after 300k training samples for question 9 and 10 and it unfortunately still stayed at 5% accuracy. Mabye this is expected? Predicting countries of origin based on name alone is very difficult so I could see how our model isn't very good, but mabye I'm doing something wrong as well. :/
@benfig1127 The default batch_size=1 seem to lead to a steady increase in accuracy. My best model seemed to be the CNN, which achieved at best 93% accuracy after 100k samples. I think the batch size is causing some weird issues on its own. Try just doing stochastic i.e. batch_size=1 to find the best model for the last questions.
Okay, I will try the SGD and see what happens with a batchsize of 1, for reference these were the parameters I used:
$ python3 names.py --learning_rate=1 --gradient_clipping --optimizer=adadelta --model=cnn --hidden_layer_size=256 --num_layers=1 --batch_size=16 --input_length=20
@AlexKer @benfig1127
I've edited your comments so that the code is properly formatted. In general, anything that is copied from code or the terminal needs to be formatted with the backticks so that it is obvious which sections of a comment come from code. Also, we want to put the hyperparameters as the actual command that you are running so that is is trivial to copy and paste the code into a terminal to reproduce a result.
@AlexKer
Please include the code for your str_to_tensor function here. Again, in general, it is much better to share too much code than too little. I'll check back after I've put my son to bed tonight.
Everyone: You shouldn't feel a need to self-censor your code just because this is a classroom environment. Our goal is to reproduce the best practices for how people actually work remotely with each other, and all forms of collaboration are 100% encouraged in this class. That goes double now that we're having to make all the coronavirus adjustments.
@AlexKer It is working much better with the batch size of 1 as well for me, this is the only thing I have changed and I can already see much better results. See screenshot below.
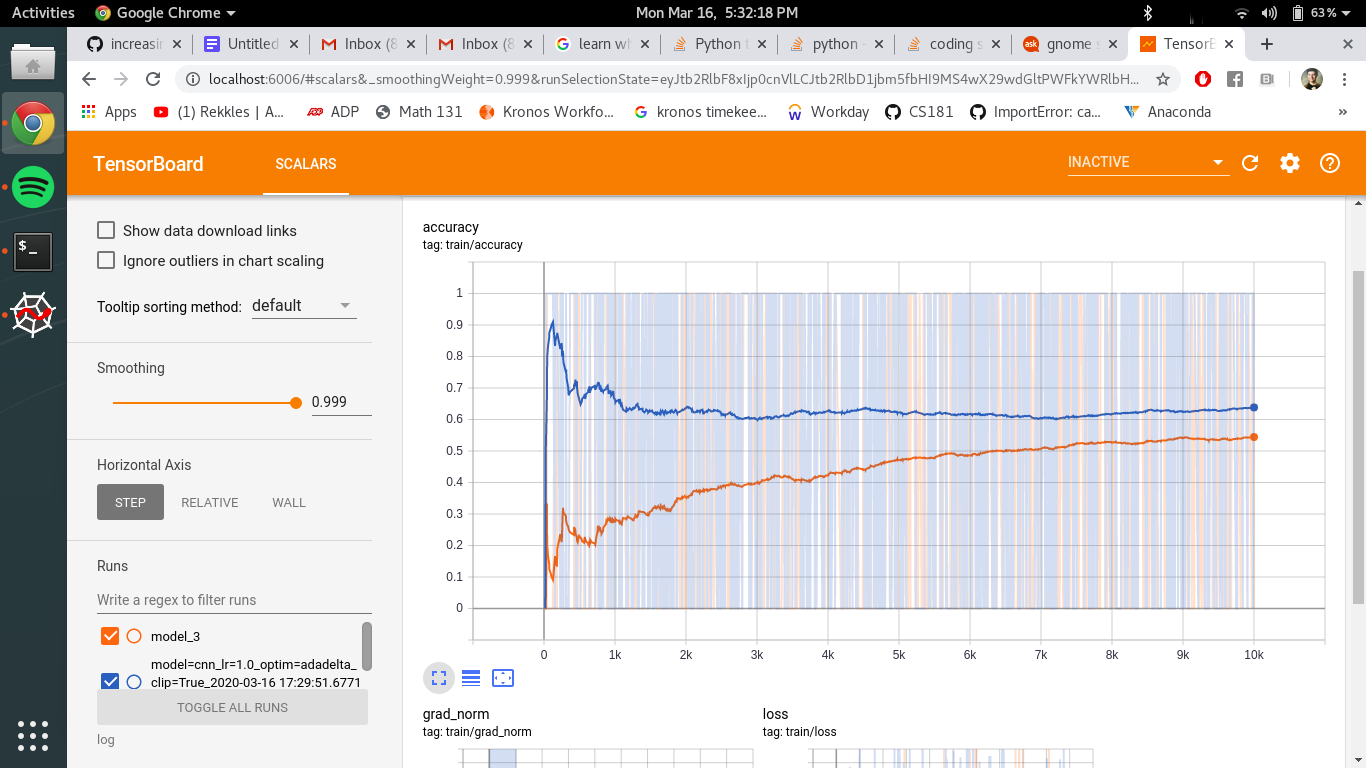
Here are the exact hyper parameters I used and how I used the warm start.
$ python3 names.py --train --learning_rate=1 --gradient_clipping --optimizer=adadelta --model=cnn --hidden_layer_size=256 --num_layers=1 --batch_size=1 --input_length=20 --samples=10000
$ python3 names.py --warm_start /home/ben/log/model_3 --train --samples=10000
@mikeizbicki Thanks for the formatting help, I will make sure to add the code in markdown form from now on.
@benfig1127 looks great! Glad my suggestion helped. You might want to lower the lr by a factor after each subsequent warm_start, as you get closer to the minima.
@mikeizbicki Here is my function,
def str_to_tensor(b):
'''
converts list of b strings into a <max(len(str in b)) x b x len(vocabulary)> tensor
'''
# take max length and add one space for '$'
max_length = len(max(b, key=len))+1
if args.input_length is not None:
max_length = args.input_length
tensor = torch.zeros(max_length, len(b), len(vocabulary))
for idx, s in enumerate(b):
s+='$'
for li, letter in enumerate(s):
if li<max_length:
tensor[li][idx][vocabulary.find(letter)] = 1
return tensor
and part of my training loop
for step in range(1, args.samples + 1):
# get random training example
categories = []
lines = []
for ex in range(args.batch_size):
category = random.choice(all_categories)
line = random.choice(category_lines[category])
categories.append(all_categories.index(category))
lines.append(line)
categories_tensor = torch.tensor(categories, dtype=torch.long)
lines_tensor = str_to_tensor(lines)
# perform training step
output = model(lines_tensor)
# print(output, categories_tensor)
loss = criterion(output, categories_tensor)
loss.backward()
This all looks good to me. Can you show me the tensorboard output of all three plots over time?
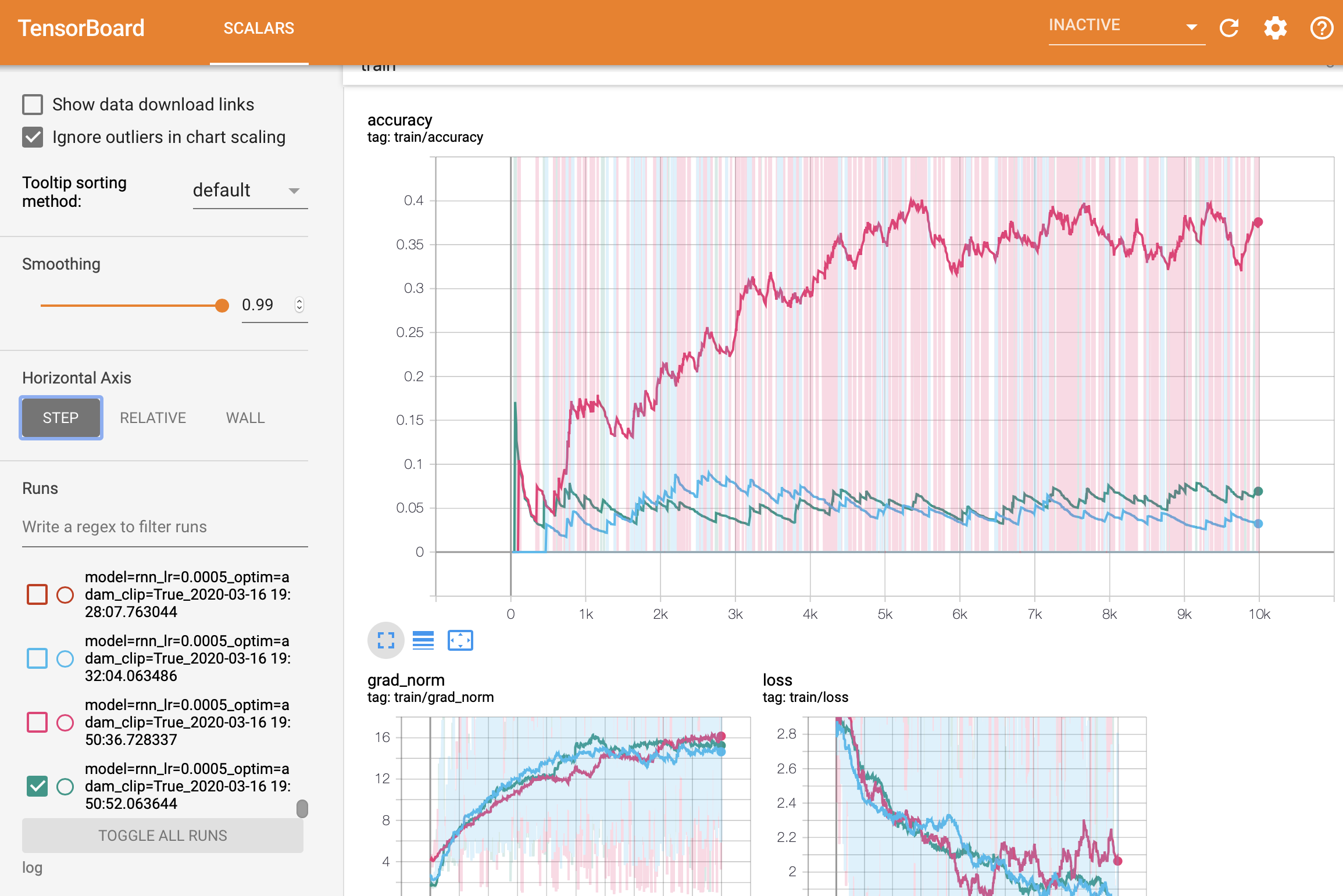 The pink is with batch_size=1, blue and green is batch_size=2.
The pink is with batch_size=1, blue and green is batch_size=2.
Whenever the loss goes down, the accuracy should go up a similar amount. Looking at your plots, we can see that this is not happening. This tells me that there is almost certainly a bug in how you are calculating one of these values. This is a general principle that holds for all machine learning classification, not just this problem. Also, this is a reason that it is always important to look at the loss function to determine whether your training is working correctly, not just the accuracy.
My guess is that you did not update the way that you are calculating the accuracy when you added batch sizes greater than 1, is that right? (The original code for calculating the accuracy does not work for batches greater than 1.)
Here's the code I'm using for calculating the accuracy for batches:
# get category from output
top_n, top_i = output.topk(1)
guess_i = top_i[0].item()
category_i = category_tensor[0]
guess = all_categories[guess_i]
category = all_categories[category_i]
accuracies = torch.where(
top_i[:,0]==category_tensor,
torch.ones([args.batch_size]),
torch.zeros([args.batch_size])
)
accuracy = torch.mean(accuracies).item()
You can see some sample runs from training at this link: https://tensorboard.dev/experiment/9eiEYkDMSO68SwDSEoc4Gg/#scalars&_smoothingWeight=0.99
Notice there that I have 4 runs with different combinations of learning rate and batch size. The combination with --batch_size=10 allows me to increase my learning rate by a factor of 10 as well, resulting in much faster convergence compared to the --batch_size=1 scenarios. You should be able to reproduce similar plots.
@mikeizbicki great this seems to work, I did not know we had to adjust that section of the code as well. Thank you!
Glad it worked!
I'm going to leave the issue open for now so that it's easier for other students to find.