STL
 STL copied to clipboard
STL copied to clipboard
<locale>: Excessive locking is slow
Hello,
I’m trying migrate server application from outdated STLPort to MSSTL and faced with significant performance degradation. As it turned out, excessive locking in 'locale' library kills the performance.
Consider following code:
#include <iostream>
#include <string>
#include <sstream>
#include <locale>
struct myfacet : std::locale::facet
{
myfacet(std::size_t refs = 0) : facet(refs) { std::cout << __FUNCTION__ << std::endl; }
static std::locale::id id;
};
std::locale::id myfacet::id;
int main()
{
auto* f = new myfacet;
// point 1
std::ostringstream oss;
std::locale l = std::locale(oss.getloc(), f);
oss << 123.456 << '\n';
oss << 456.789 << '\n';
// point 2
}
Between point 1 and 2 there are 92 (sic!) _lock_locales CRT function calls. Even simple std::ostringstream creation involves 4 _lock_locales calls. This CRT function on its own turn has non-trivial behavior which only increases chances of contention on critical section which protect locales.
C++ standard defines std::locale as an immutable indexed set of immutable facets. According to definition and Technical Report on C++ Performance one may expect that creation or modification of locale object doesn’t involve locking and only atomic operation are involved. Actually, this is a case for STLPort implementation which doesn’t have any locking whatsoever.
I’ve created a simple test application which creates std::ostringstream object and add some doubles boost::posix_time::ptime (uses custom facet) objects. Below you can see latency distribution for different number of threads for MSSTL and STLPort implementation.
8 logical CPU, 4-cores:
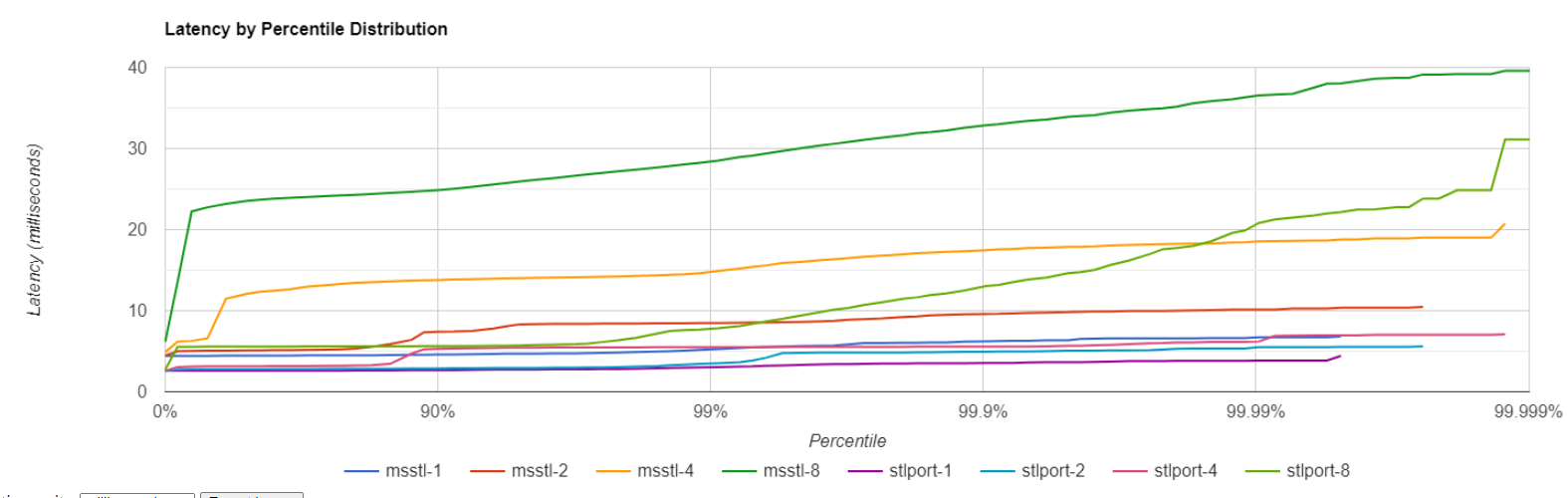
Things becomes even worse on server grade hardware.
32 logical CPU, 16 cores:
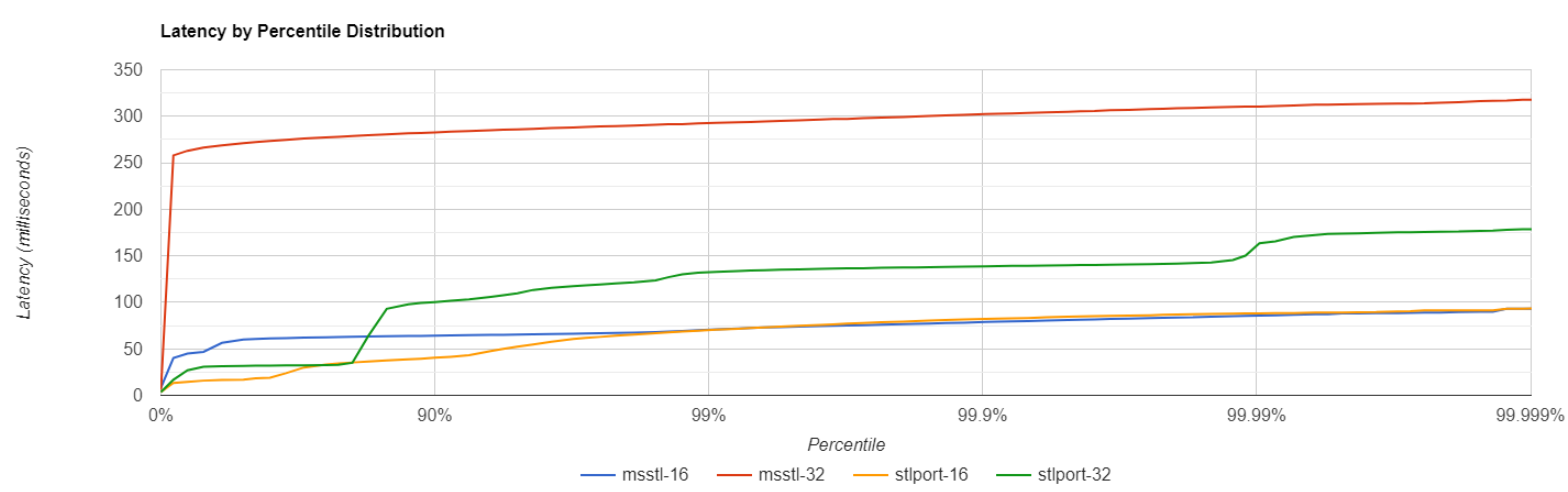
Profiler clearly shows that significant time is spent on locks.
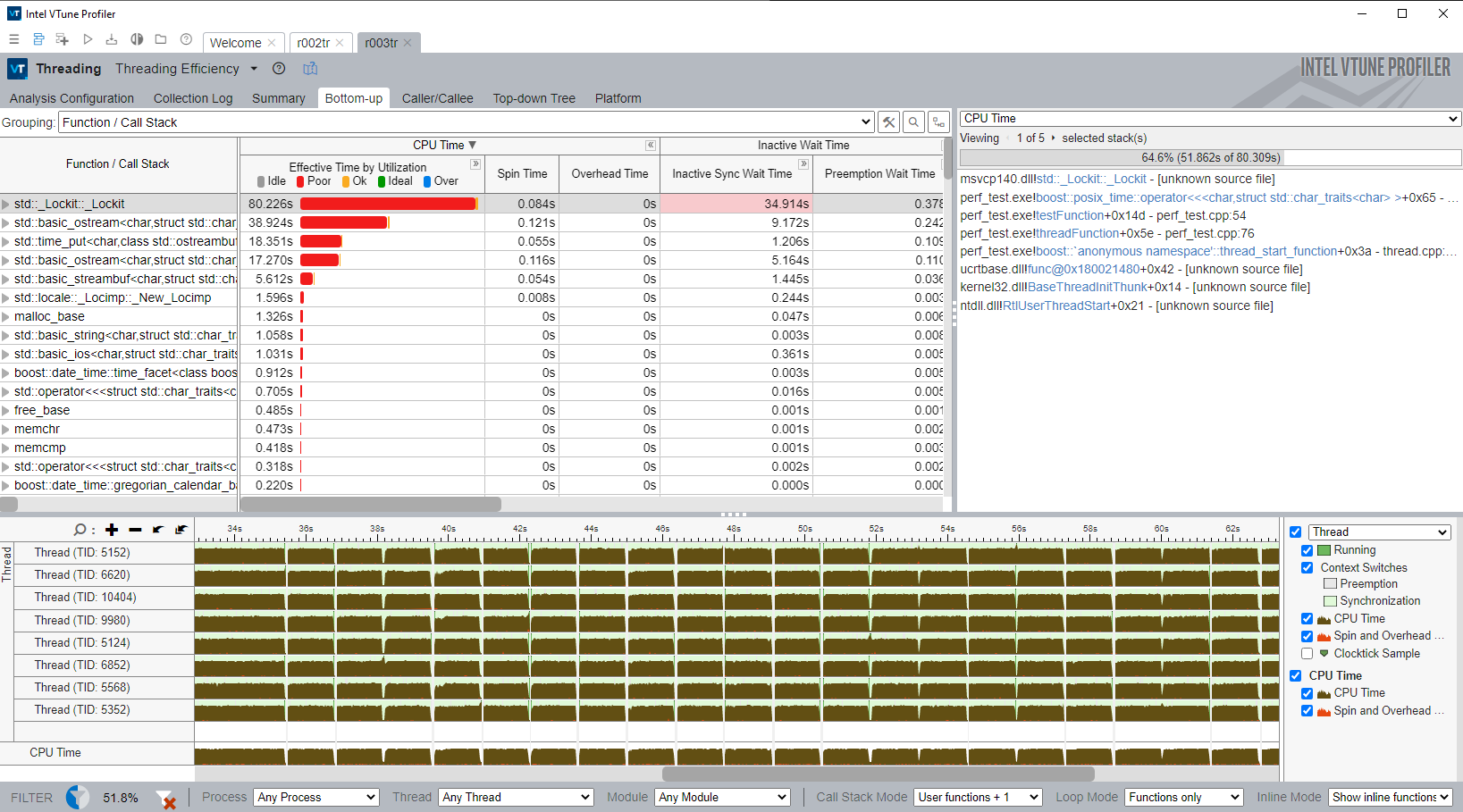
Unfortunately, such behavior make std::streams unusable for multithreaded server applications. Are there any chances that those locks will be removed in next releases of MSSTL and Visual Studio?
Thank you
Thanks for the profiling information. This is a known issue that we'd like to fix in our "vNext" binary-breaking release.
Any update on this? Is it still "we'd like to fix" or will it be there? Right now I have a process dump opened, where 34 threads have std::_Lockit::_Lockit in their callstack, absolutely killing performance.
No update. There is no ETA for vNext and no guarantee that we will be able to refactor the code here. (Some vNext progress is happening behind the scenes, but no promises yet. Locales are one of the most fragile parts of the STL, so we can't promise that this will be fixable even when we aren't constrained by bincompat.)
After some searching, I came here: I have an unordered_map object. I used = std::find_if to search and found that it occupied a high CPU. After analysis, I found that the CPU increase came from here (I used the latest vs2022 and the project was debug configuration):
Does stl internal implementation need locking?
Does stl internal implementation need locking?
Yes, locking is needed for iterator debugging.
If it's that hard to reimplement it without mutexes, could you please consider changing it so it uses shared locks for reading when possible, and doing exclusive lock only when it's really necessary? While single-threaded performance could be a little bit slower with that, multithreaded application would benefit from it greatly, as these threads wouldn't block each other. Surely nowadays applications that have heavy CPU usage are all multithreaded.
I just realized that boost::algorithm::iequals calls toupper for each compared char, and toupper does this locale locking. So each single compared character does at least one locale locking. So the problem is even more serious than it looks at first glance.
If it's that hard to reimplement it without mutexes, There are number of implementation without locking.
Right, but I am under an impression that they see it as too much effort, seeing how huge the issue is and that it was opened three years ago. So my comment was an attempt to make them do something, even if it's not optimal.
But maybe they could review and copy+paste implementation of others, because as you say, there are some of them out there already. Practically anything without locks would be faster than it's now.
We're highly constrained by binary compatibility here, which is why we haven't made changes. Because many users in the ecosystem rely on previously built libraries, and have difficulty building everything consistently with the newest toolset, we guarantee binary compatibility (with restrictions), meaning that old and new object files can be mixed together. This means, among other things, that such object files need to agree on how they lock things. (It also prevents many class representations from changing.)
The "vNext" label on this issue indicates this. At some point we hope to have an ABI-breaking release, but not in the near future.