meilisearch
 meilisearch copied to clipboard
meilisearch copied to clipboard
Cannot allocate memory when creating indexes
I'm trying to create 10000+ indexes with 500+ documents and I get this error on a machine with 16GB of ram:
MeiliSearch ApiException: Http Status: 500 - Message: Cannot allocate memory (os error 12) - Error code: internal - Error type: internal_error - Error link: https://docs.meilisearch.com/errors#internal

MeiliSearch version: 0.23.1
Additional context Amazon Linux 2 - x86_64 - 16GB ram - With 10GB of ram free
1,1G data.ms/
Upon reaching 2.6gb meilin stops working. I tested with aws image: MeiliSearch-v0.23.1-Debian-10.3
MeiliSearch ApiException: Http Status: 500 - Message: Cannot allocate memory (os error 12) - Error code: internal - Error type: internal_error - Error link: https://docs.meilisearch.com/errors#internal

Hello @neylsongularte! This seems to be indeed a bug since it should not appear. I succeeded to reproduce it on my MacOS (16Gb RAM) by trying to create 100000 indexes in a raw: it stops around 1300 indexes with the same error as you. This is not an expected error, however, I need to understand your use case to know why you need to do 10000 indexes 🙂 I want to ensure you are using MeiliSearch as you expect
Hello @neylsongularte! This seems to be indeed a bug since it should not appear. I succeeded to reproduce it on my MacOS (16Gb RAM) by trying to create 100000 indexes in a raw: it stops around 1300 indexes with the same error as you. This is not an expected error, however, I need to understand your use case to know why you need to do 10000 indexes 🙂 I want to ensure you are using MeiliSearch as you expect
I have 10000+ pdf files and would like to perform an individual search on each of them. I figured I would have no problem creating an index for each file. Each document is a block of text in the pdf.
Thanks for the answer
Hello @neylsongularte,
A solution you could use is to use only one index where you just add a path field to every document/block of text you have and simply filter for the file you want i.e. path = document_name_1.pdf. This way you will not have this issue anymore as you will have only one index.
Thank you very much for reporting this issue 😃
Hello @neylsongularte,
A solution you could use is to use only one index where you just add a
pathfield to every document/block of text you have and simply filter for the file you want i.e.path = document_name_1.pdf. This way you will not have this issue anymore as you will have only one index.Thank you very much for reporting this issue 😃
I've already modified my strategy accordingly. I missed being able to delete documents using a filter.
Thank you for your help
FYI @meilisearch/product-team about this feature request: https://github.com/meilisearch/product/discussions/284
@neylsongularte Was this memory allocation issue fixed? I am also facing issue while adding a large number of indexes.
{
"uid": 623574,
"indexUid": "some_index",
"status": "failed",
"type": "documentAddition",
"details": {
"receivedDocuments": 461,
"indexedDocuments": 0
},
"error": {
"message": "Cannot allocate memory (os error 12)",
"code": "internal",
"type": "internal",
"link": "https://docs.meilisearch.com/errors#internal"
},
"duration": "PT0.002846507S",
"enqueuedAt": "2022-06-24T07:18:59.693875888Z",
"startedAt": "2022-06-24T07:18:59.696174469Z",
"finishedAt": "2022-06-24T07:18:59.699020976Z"
}
Hello @tanmaymaheshwari97! Can you check if you still have enough space on your machine for Meilisearch?
Hi @curquiza. My prod instance is on hosted on google cloud platform. And only around 4.5 GB of memory is utilized out of 16 GB.

Thanks for your quick answer. I was not asking about the RAM (16Gb), but the total about of space you have on your disk, and if there is enough space for Meilisearch to index your data 😊
I had a look at the disk space utilisation also. I don't think space is the issue here. Please suggest how to fix this issue as our search entirely depends on it. Thanks.
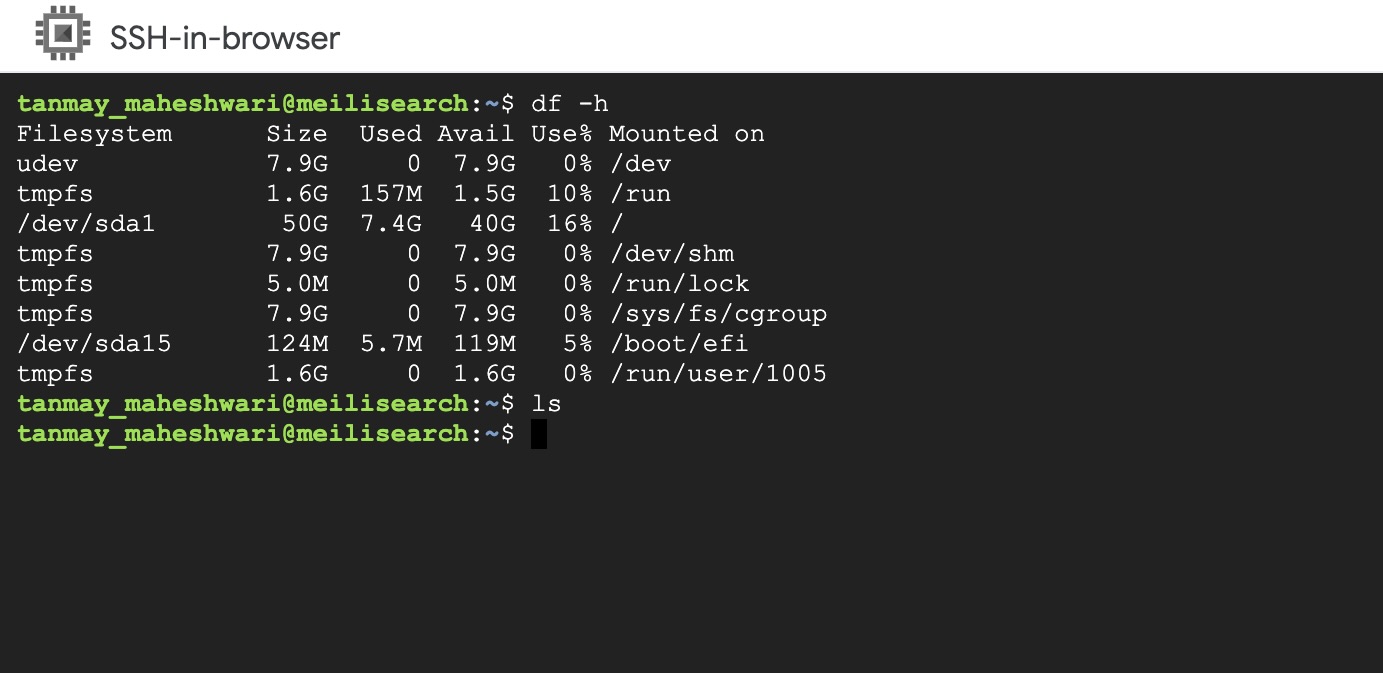
I had a look at the disk space utilisation also. I don't think space is the issue here. Please suggest how to fix this issue as our search entirely depends on it. Thanks.
I changed the strategy and put it in a single index as suggested.
For information, related issues: https://github.com/meilisearch/meilisearch/issues/1841 #2616
And it does not seem to be a huge amount of indexes
Discussed with @Kerollmops: an idea could be to use an LRU (least recently used) map instead of a HashMap
Discussed with @Kerollmops: an idea could be to use an LRU (least recently used) map instead of a HashMap
The issue with switching to a LRU is that the ecosystem does not have one that is maintained and can do get() operations behind a RwLock. I can roll one a simple one myself if we need to, though.
Should be fixed by #3331, we will communicate here once the RC is out so that you can test it 😊