DeepCompression-caffe
 DeepCompression-caffe copied to clipboard
DeepCompression-caffe copied to clipboard
snapshot crasp
when snapshot start, it crash.
I0721 11:04:23.275313 17167 solver.cpp:244] Train net output #0: acc = 0.428571
I0721 11:04:23.275321 17167 solver.cpp:244] Train net output #1: loss = 1.88784 (* 1 = 1.88784 loss)
I0721 11:04:23.275328 17167 sgd_solver.cpp:106] Iteration 9, lr = 0.001
I0721 11:04:23.275475 17167 solver.cpp:454] Snapshotting to binary proto file dataset/lenet_iter_10.caffemodel```
Process finished with exit code 139 (interrupted by signal 11: SIGSEGV)
我也拉了博主的代码,跑了下,没有遇到你这个问题,不过跑出来后,发现caffemodel和以前一样的大,不知道是不是哪里操作的不对,你最后有弄出来没有?
@daimagou 直接用caffe跑出来的模型依然是原始大小,因为模型依然是.caffemodel类型,虽然大部分权值为0且共享,但每个权值依然以32float型存储,故后续只需将非零权值及其下标以及聚类中心存储下来即可,这部分可参考作者论文,写的很详细。
@xiaohu2015 deep compression 需要读入已训练好的模型做压缩,在LayerSetUp函数中,每层仅仅做了内存分配但未读入已训模型,因此此时的模型参数是随机初始化的,需要在CopyTrainedLayersFrom函数中调用ComputeBlobMask函数
@may0324 @daimagou @guozhongluo
在读取caffemodel参数时(前提是make matcaffe 已成功,且成功读取其它模型参数)使用MATLAB读取剪枝聚类后的caffemodel,出现如下错误
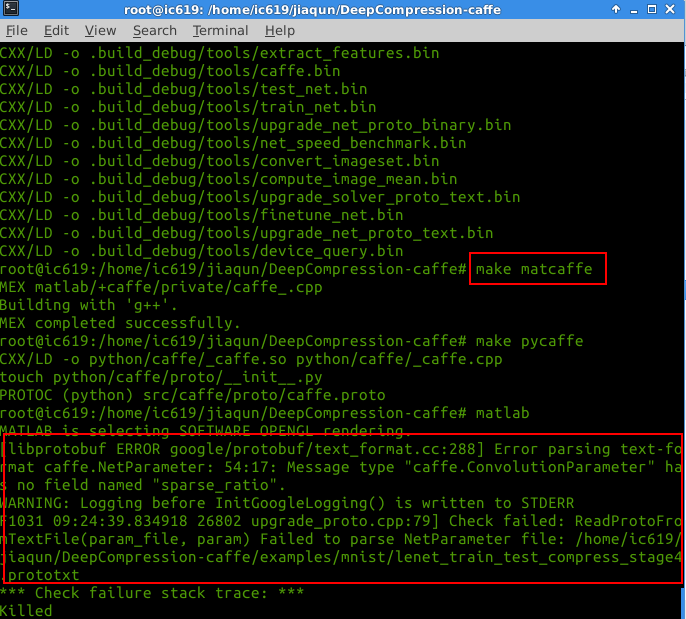
然后又用Python读取,也发生错误,程序与错误如下

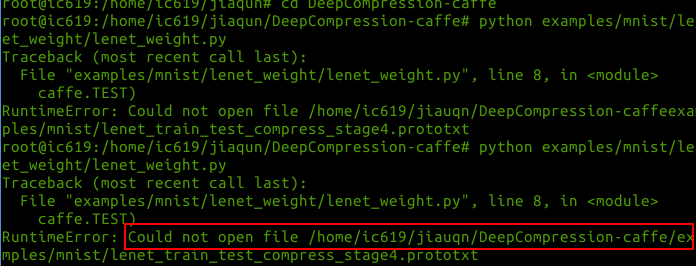 希望能得到你们的帮助,非常感谢~
希望能得到你们的帮助,非常感谢~
@pgadosey @may0324 hi,can you share the code that how to store the non zero weights and cluster center for reference? thanks very much
@jiaqun123 unforyunately, i never got around it. I found this repository that implemenets the quantization part of this paper but for inference purposes you have to dequantize your weights in order to use them. https://github.com/yuanyuanli85/CaffeModelCompression . Kindly let me know if you are able to store them in another way
@pgadosey thanks, I found this repository that implemenets the storage of sparse matrix. https://github.com/ZhouYuSong/caffe-pruned . You can learn from it.
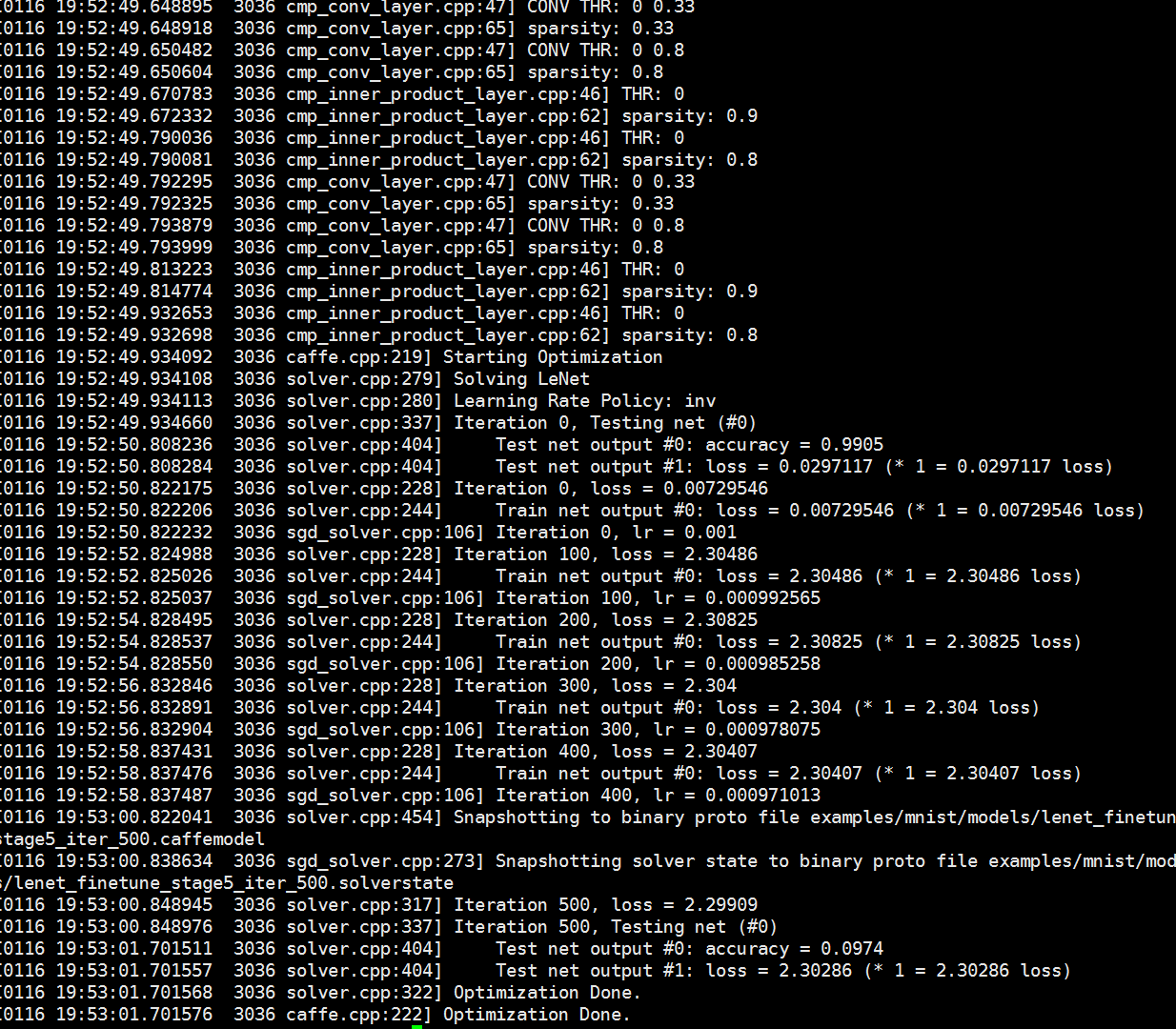 hi,I run the python script,why the final accuracy is 0.0974?
hi,I run the python script,why the final accuracy is 0.0974?
@may0324 我感觉这种方式只能减少在硬盘或者flash上的的存储大小啊,在实际运行时,0还是要恢复到内存中,而且即使加了一个mask,也需要一条判断语句,感觉效果应该不明显啊。有没有人能解释解释。