mars
 mars copied to clipboard
mars copied to clipboard
Proposal - Group by order preservation
Background
The current implementation of the group by aggregation API in Mars uses the shuffle implementation for large dataframes. In the shuffle algorithm, the final order of the grouped and aggregated dataframe is not guaranteed.
In this proposal we propose a solution to preserve the order of the final groups in the resultant dataframe when sort=False
Pandas API
sort : bool, default True Sort group keys. Get better performance by turning this off. Note this does not influence the order of observations within each group.
When sort = False then the original order of the dataframe groups is preserved.
Mars however currently does not support this feature.
This proposal build upon the group by sort proposal https://github.com/mars-project/mars/issues/2915
Groupby order preservation
For the groupby order preservation support, we make changes to groupby sort.
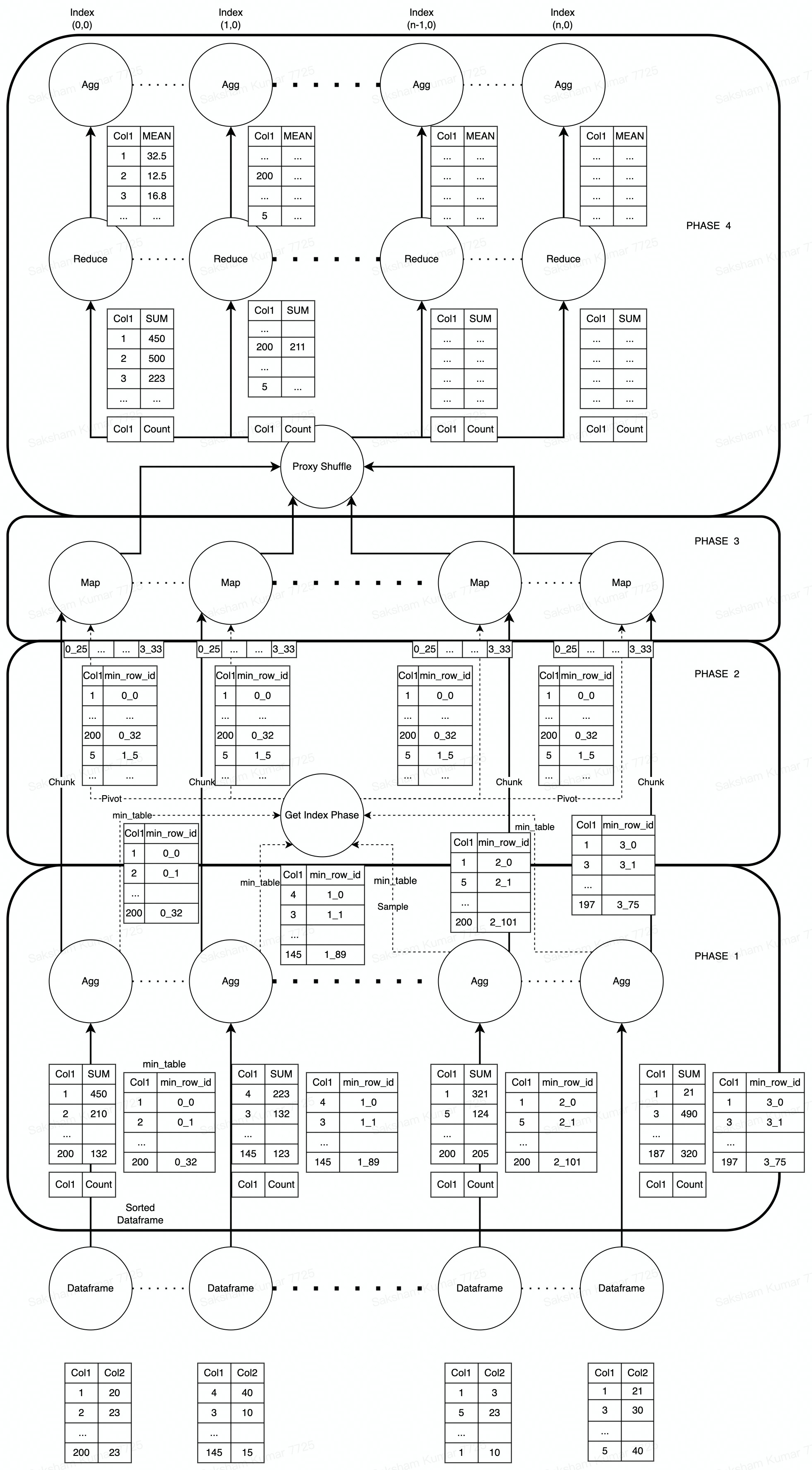
- PHASE 1: In Phase 1, Apart from the normal aggregation with sort=False, we add a new col row_id and then run groupby with operation min() to get a new dataframe called the min_table in this document. This will give us the index of the group in this dataframe. So for a groupby.mean() operation, we will have 3 dataframes at this stage.
- PHASE 2: In this phase, like the groupby sort algorithm, our aim is to find the pivot values for the mapper phase. However, we also need to find the final index of the groups. For this we will use this phase to create an aggregated min_table. This aggregated min_table will contain the final index of each group in the column min_row_id, and will be used by mappers to assign keys to groups This section is elaborated further later. The pivot will also consist of values from the min_row_id according to which data will be split amongst reducers.
- PHASE 3: Phase 3 is similar to the groupby sort algorithm, where we have each Map assign reducer key using the pivot information (generated in Phase 2) instead of using hashes. This ensures that all groups G such that pivot_i < G < pivot_(i+1) are mapped to reducer_i. For reducer key, we will need to leverage the existing indexes for each chunk. I.e. Reducer with reducer key reducer_i will be the reducer with index i. The only exception is that we join the dataframe with the aggregated min_table to propagate the index information in the min_row_id column.
- PHASE 4: In Phase 4 we use the existing proxy shuffle method to have each reducer take keys belonging to this reducer. Then we sort each individual dataframe by the min_row_id column to get the final order. Then in the aggregation phase, the min_row_id column is dropped, and the dataframes are aggregated with the flag "sort=False"
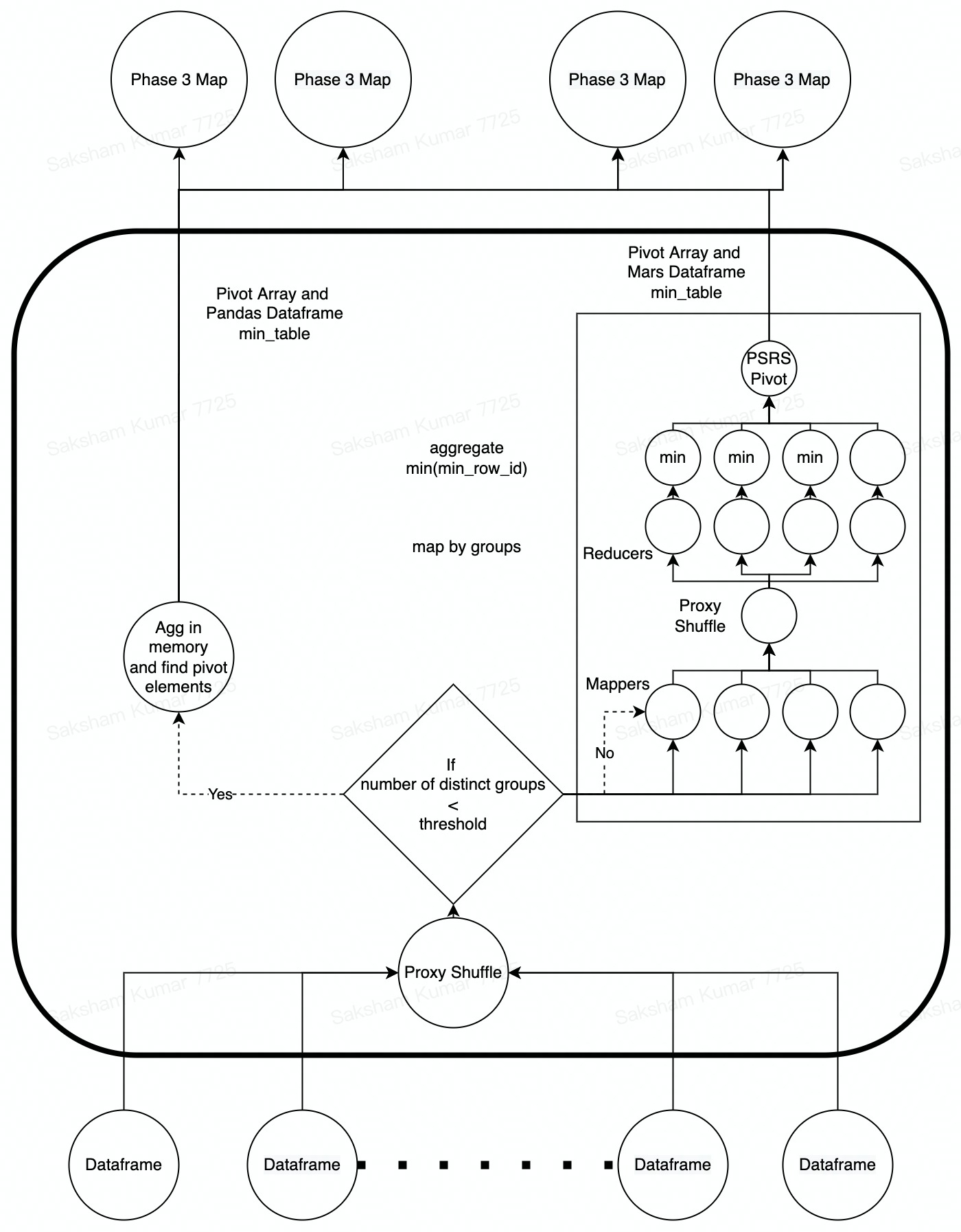
Phase 2 Elaboration
For phase 2 we propose two alternatives.
- When the number of the unique groups across dataframes is small. In this case the min_tables from each chunk is brought into memory on the proxy shuffle machine and then aggregated. The pivot elements are calculated and then sent to the Phase 3 mappers. The output here is a pivot table and a pandas dataframe.
- When the number of unique groups is too large to fit onto memory, we suggest a Map-Reduce phase.
- In the map phase, all groups are hashed to the same reducer.
- In the reducer and aggregation phase, we run a min() aggregation on the row_id to get the smallest row_id for each group. This gives us a distributed dataframe, where each group has an associated index value in the min_row_id column Next we use the pivoting phase of the PSRS algorithm to generate the pivot table using the distributed dataframe, which is sent along the distributed dataframe to the Phase 3 mappers. The output here is a pivot table and a mars dataframe.
Limitations
- One of the limitations is the addition of the row_id column. For a very large dataset this might lead to a very large overhead. Also this row serves no purpose after the group by is complete and needs to be dropped to maintain consistency. An alternative would be to use a column as a primary key (if one exists) and a user provided sorting logic to deduce the order for this primary key. Another alternative would be to leverage the index that all dataframes have as instead of the row_id.
- Another big limitation is the min aggregation operation.
- This operation requires a parallel aggregation all for the purpose of order guarantee. This parallel aggregation also needs to collect all the individual min_df from each node. This process is both memory and network intensive.
- This operation is memory intensive as it requires all unique groups and index numbers to be present at all nodes for sorting. This may work for a small number of unique groups. But as the number increases, so will the memory footprint.