deep-landmark
 deep-landmark copied to clipboard
deep-landmark copied to clipboard
training 1_F network
Hi,
I downloaded the recommended data and trained 1_F network for 1 million iteration, and it got:
 Those error are consistent on the training data and test data.
on a test image it is clear that the nose is set on the bounding box on the x axis:
Those error are consistent on the training data and test data.
on a test image it is clear that the nose is set on the bounding box on the x axis:
 I tried to re-train it again and then got the same kind of error for the left eye:
I tried to re-train it again and then got the same kind of error for the left eye:
 Everytime I re-train I get a different defective point, which mad me think it is a random phenomena related to the data generation, but I was unable to detect a bug in the augmentation.
When running the pre-trained 1_F model you provided than I am able to get perfect results as you present.
I'm running on ubuntu 14.04 python 2.7
Everytime I re-train I get a different defective point, which mad me think it is a random phenomena related to the data generation, but I was unable to detect a bug in the augmentation.
When running the pre-trained 1_F model you provided than I am able to get perfect results as you present.
I'm running on ubuntu 14.04 python 2.7
Let me know what output can be useful in order to debug it
Thanks
@imryki If the training data itself is wrong, you can use some tool to view the hdf5 file, https://www.hdfgroup.org/products/java/hdfview/ may be useful. If the ground truth landmark is wrong, there might be some bug in the code.
From the result, you have trained 1_F twice, did you train the cnn on the same data (same xxx.h5 file) ? Or you have process the training data twice?
Hi, Thanks for your quick reply @luoyetx I run two training session in sequence. I run the beginning of the pbootstrap.sh code in order to train level 1:
python2.7 prototxt/generate.py GPU
# level-1
python2.7 dataset/level1.py
echo "Train LEVEL-1"
python2.7 train/level.py 1 pool_on
I used the same input data for both run from: http://mmlab.ie.cuhk.edu.hk/archive/CNN_FacePoint.htm, the ground truth data doesn't include systematic errors. As I got different errors for each training session, I suspected that the random augmentation in dataset/level1.py had a bug. But when plotting its augmented images with corresponding points I didn't find any mis-match.
Where you able to reproduce 1_F results with the most recent caffe version?
@imryki The Caffe version I use is pretty old which may be one year ago, but I don't think the recent Caffe will cause this error.
As you mentioned, the augmented data is good (landmark position and landmark order). I think the training process may need more tuning. What's more, use hdf5 viewer to see train.h5 is good or not, If the landmark order is wrong, you may not be able to find it by plotting the landmarks on face using the same color. I use these python code to process the data and train the model. So, the code is good for me. My environment is Centos6.5 and Python2.7
By the way, I recommend you to directly use caffe train --solver xxxx command to train the cnn. All prototxt files should be in prototxt.
You may find this pdf useful which I present some more detailed data.
Thanks for the pdf, I will try to reproduce its 1_F loss plot to understand why it fails. I will also try to validate the point's order in the augmented data I will keep you update @luoyetx
@ikvision hi, sorry to interrupt you. i met the same problem as you. I also trained 1_F network for 1 million iteration, and got a pretty high error of left eye . Have you find out how this problem comes?
hi @yyytq
I tried debugging the input loading and processing but didn't find its root cause or a solution for it
@yyytq @ikvision Recently, I find a reason why this happens, there's something wrong with your training loss, it's not small enough. Make sure you training loss is about to be 0.00X at beginning, if not, restart the training.
@luoyetx Sorry to interrupt you.I can't make my training loss be about 0.00X at beginning when I train level 1.I wonder to know whether you had tried many times at the beginning of the train to get sush low loss or just got it easily? I will appreciate you if can tell me the answer.Of course, you may forget the experiment detail...
I find the loss picture of level-1. I think you need to tune the solver parameters like learning rate.
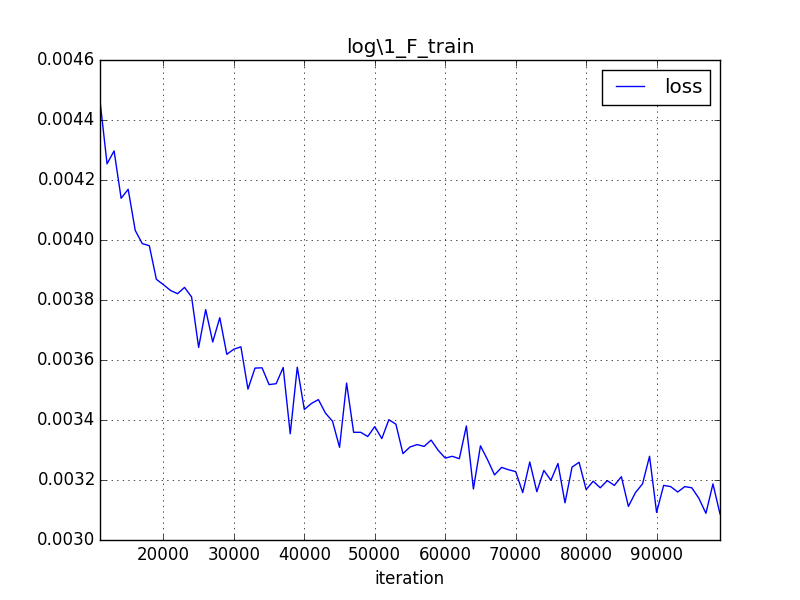
@huinsysu I have upload all plots. I think the solver parameters in this repo are not good, better parameters can converge much faster.