FastChat
 FastChat copied to clipboard
FastChat copied to clipboard
safe_save_model_for_hf_trainer function save mode is very small
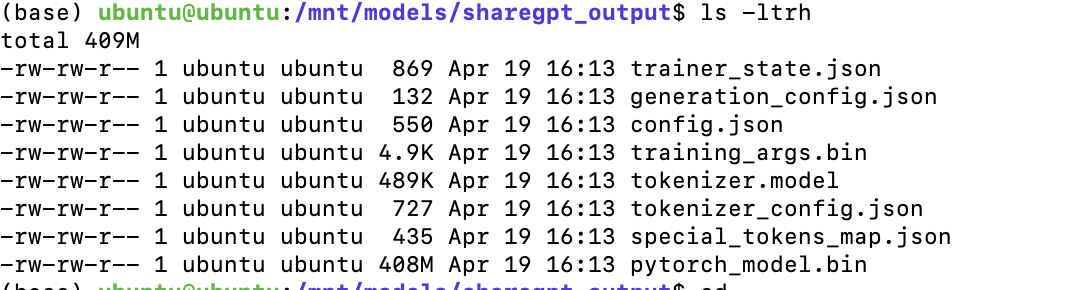 I trained the model using the 33B architecture and the train.py file with deepspeed , but when I saved the model using the safe_save_model_for_hf_trainer function, it was only 400M.
I trained the model using the 33B architecture and the train.py file with deepspeed , but when I saved the model using the safe_save_model_for_hf_trainer function, it was only 400M.
the deepspeed is :
{
"bf16": {
"enabled": "auto"
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"total_num_steps": "auto",
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": false
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 5,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
if you are using: https://github.com/lm-sys/FastChat/blob/main/fastchat/train/train.py,
then
in line 246: replace safe_save_model_for_hf_trainer(trainer=trainer, output_dir=training_args.output_dir)
with
checkpoint_dir = os.path.join(training_args.output_dir, "checkpoint-final")
trainer.deepspeed.save_checkpoint(checkpoint_dir)
then, checkpoint-final will contains zero_to_fp32.py after the training is done.
just run python zero_to_fp32.py . pytorch_model.bin
for more information, look here: https://huggingface.co/transformers/v4.10.1/main_classes/deepspeed.html#getting-the-model-weights-out
@lw3259111 Just try to get a clarification -- are you training your own llama 33B using deepspeed?
@lw3259111 Just try to get a clarification -- are you training your own llama 33B using deepspeed? yes , I use deepspeed
A takeaway if you want to impl the save weight yourself: https://github.com/lm-sys/FastChat/blob/4d33cde2322544532ab940ed1ece1f82d77fe18c/fastchat/train/train_lora.py#L55-L60 But I think hf should have the same code
A takeaway if you want to impl the save weight yourself:
https://github.com/lm-sys/FastChat/blob/4d33cde2322544532ab940ed1ece1f82d77fe18c/fastchat/train/train_lora.py#L55-L60
But I think hf should have the same code I have rewritten your code, but it still doesn't work
def maybe_zero_3(param):
if hasattr(param, "ds_id"):
assert param.ds_status == ZeroParamStatus.NOT_AVAILABLE
with zero.GatheredParameters([param]):
param = param.data.cpu().clone().detach()
return param
def safe_save_model_for_hf_trainer_clone(trainer: transformers.Trainer,
output_dir: str,training_args:TrainingArguments):
"""Collects the state dict and dump to disk."""
state_dict = trainer.model.state_dict()
to_return = {
k: state_dict[k] for k in state_dict
}
state_dict = {k: maybe_zero_3(v) for k, v in to_return.items()}
if training_args.local_rank == 0:
trainer.model.save_pretrained(training_args.output_dir, state_dict=state_dict)
Maybe you can try to print out the shape and size of tensors in the state_dict to check what happens. Typically for the ungathered zero-3 tensor, there is only a placeholder with an empty shape
I found a bug in the train_lora.py example. A hot fix is to use model.named_parameters() instead of state_dict(). Note that the named_parameters returns an iterable instead of a dict.
Please check https://github.com/lm-sys/FastChat/pull/1285
How much memory did you use to fine-tune the 33B, and what are the fine-tuning parameters? These are very important to me, thank you!