FastChat
 FastChat copied to clipboard
FastChat copied to clipboard
WARNING: tokenization mismatch 139 vs. 141
Hello! During training, the data processing always reports the following error, what could be the reason?And what are the possible consequences?
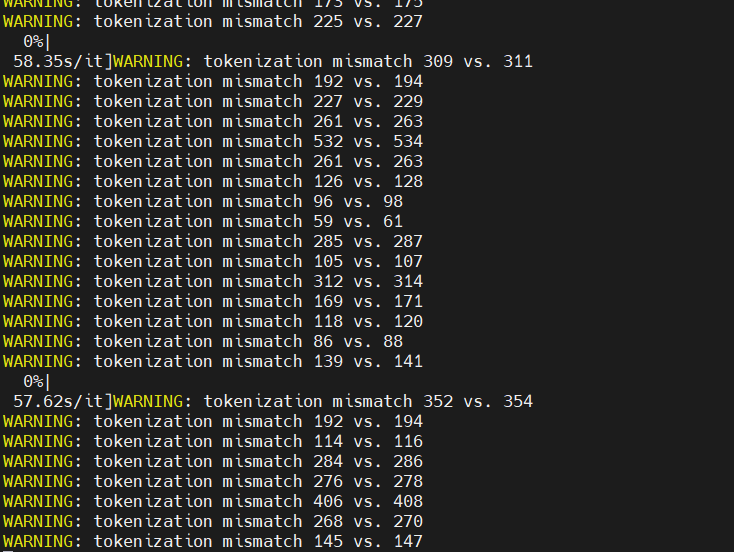
I have the same error as you, whether you used the author's cleaning code and then generated sharegpt_split.json, and reported the error during training with sharegpt_split.json data?
Please try to pull the latest version of Fastchat and the latest version of our weights.
I have the same error as you, whether you used the author's cleaning code and then generated sharegpt_split.json, and reported the error during training with sharegpt_split.json data?
后面你有解决吗?这个问题我不知道是出在哪里?之前的版本是没这个mismatch的问题的
I have the same error as you, whether you used the author's cleaning code and then generated sharegpt_split.json, and reported the error during training with sharegpt_split.json data?
后面你有解决吗?这个问题我不知道是出在哪里?之前的版本是没这个mismatch的问题的
I solved this problem with this code. https://github.com/lm-sys/FastChat/pull/537#issue-1677943634 This may be helpful to you.
I have the same error as you, whether you used the author's cleaning code and then generated sharegpt_split.json, and reported the error during training with sharegpt_split.json data?
后面你有解决吗?这个问题我不知道是出在哪里?之前的版本是没这个mismatch的问题的
I solved this problem with this code. #537 (comment) This may be helpful to you.
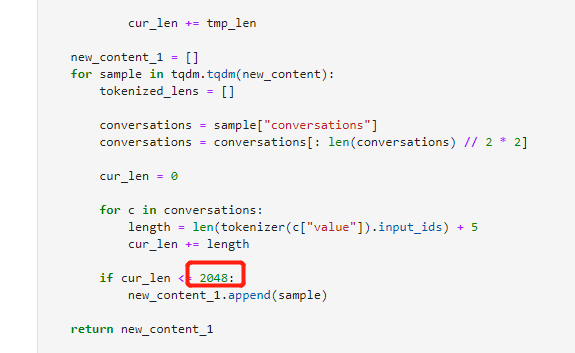 这个2048的参数是不是应该跟着max_length变动?
这个2048的参数是不是应该跟着max_length变动?
I have the same error as you, whether you used the author's cleaning code and then generated sharegpt_split.json, and reported the error during training with sharegpt_split.json data?
后面你有解决吗?这个问题我不知道是出在哪里?之前的版本是没这个mismatch的问题的
I solved this problem with this code. #537 (comment) This may be helpful to you.
Yes!
I also encountered this problem (i.e. total_len == curr_len + 2). Further debugging reveals that this is caused by a mis-tokenization of </s>.
Missing tokenizer_config.json and special_tokens_map.json in the converted model directory may be the cause of the wrong config. Following tokenizer-issues, I update these files from hugging face repo, and the problem is fixed.