FastChat
 FastChat copied to clipboard
FastChat copied to clipboard
Is there a way to optimize the output token per second?
Hi there,
I understand autoregression which outputs words one by one. With some manual benchmark, our deployment gives 50 English words in 6 seconds. Is there a way to optimize this? We plan to use better machine with 8 times of GPUs to test it, but before that, we want to do some proof researching.
We are using: vicuna13b
Regards,
we use a10 to inference, also looks slow.
Could you provide a brief measurement on that? etc. token/word per second
we use a10 to inference, also looks slow.
Could you provide a brief measurement on that? etc. token/word per second
@vinvcn
len(output) = 6756 (bytes or ?) duration = 109 seconds len/duration = 61/s
4xA100, and it's speed,seems not use GPUS fulling, Is there a way to improve inference speed? thx
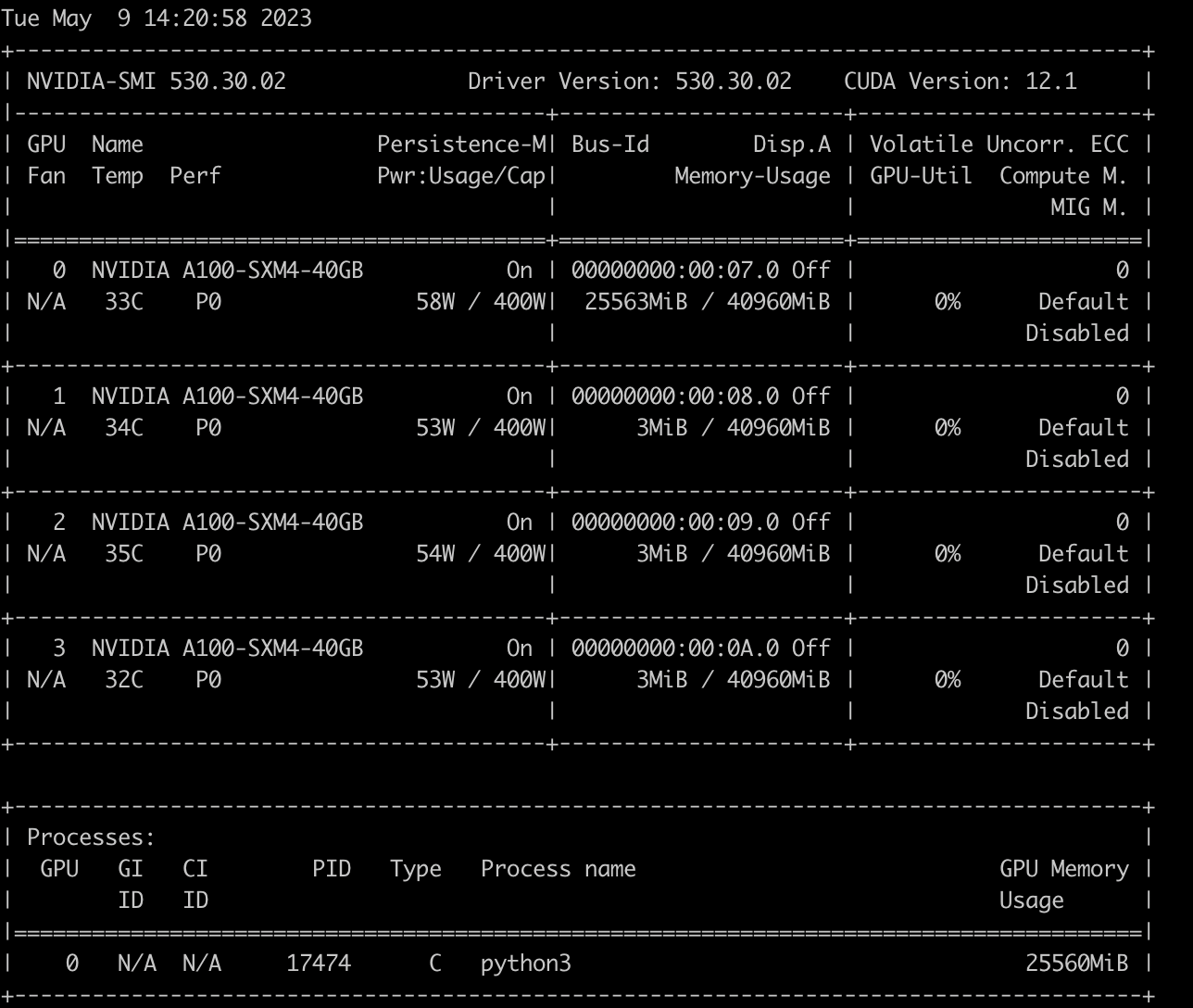

Command to start vicuna is : python3 -m fastchat.serve.model_worker --model-path /root/vicuna/vicuna13b --num-gpus 4
@vinvcn
You can use other fast inference libraries like FasterTransformers. We will also soon release a high throughput batching backend.
You can use other fast inference libraries like FasterTransformers. We will also soon release a high throughput batching backend.
Thanks for your work to improve this. Would you please give some hint about the idea of throughput batching for our analysis?