Burrow
 Burrow copied to clipboard
Burrow copied to clipboard
Question: Total vs Partition Lag
I have a question on proper monitoring of Kafka group/topic lag using the endpoint referenced below, my objective is to figure out when a consumer isn't consuming outside of it's given threashold. Some apps that may be 1MM messages, once a week.. Other apps that should never be more than 2k messages deep over 5m.
I looked at: v3/kafka/(cluster)/consumer/(group)/lag
In there I see two interesting elements:
status.totallag
and
status.partition[0..n].start.lag
status.partition[0..n].current_lag
Ideally, I would like to use status.totallag, however, when I tally up, that value never matches either start.lag or current_lag. Especially when there is a great deal of lag for the consumer group.
In addition we are using a burrow-->prometheus exporter to generate a scrape with the above referenced route.
Thank you for your time in answering this question.
Wanted to add a visualization on the partition lag and the total lag data points:
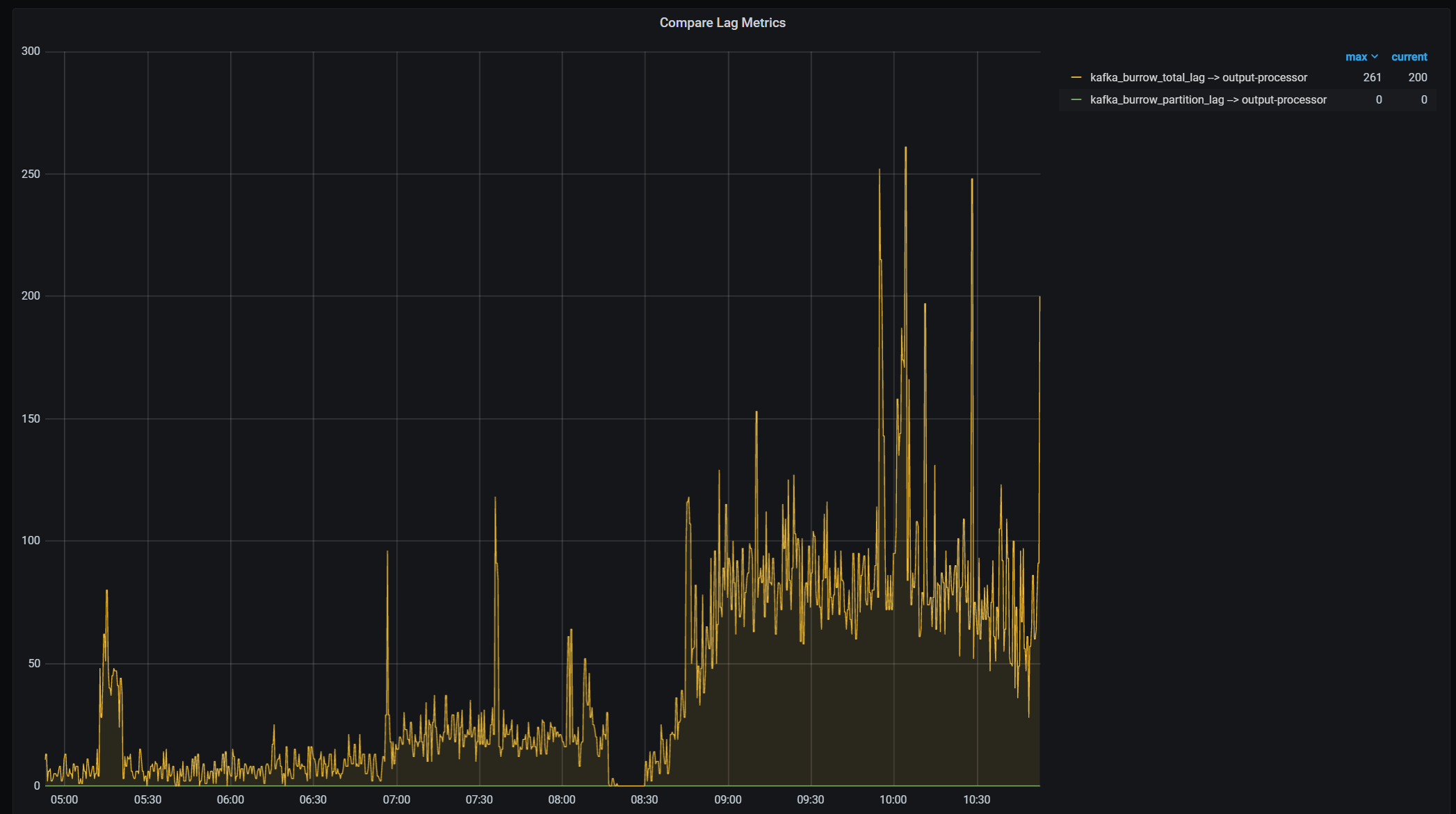
Run into the same problem and realized there's a bug in burrow_exporter v0.0.6. It's not exporting the correct kafka_burrow_partition_lag. There's already an unreleased fix, just need to build the master branch yourself https://github.com/jirwin/burrow_exporter/commit/a40362c95ca5534040d8c29a23b40168a9d70015