deep-high-resolution-net.pytorch
 deep-high-resolution-net.pytorch copied to clipboard
deep-high-resolution-net.pytorch copied to clipboard
what does "exchange block" really mean?
Dear sir,
Thanks for your excellent job of paper "Deep High-Resolution Representation Learning for Human Pose Estimation"! I have an question about the "exchange block":
In the "Repeated multi-scale fusion"part, it says "We divided the third stage into several (e.g., 3) exchange blocks, and each block is composed of 3 parallel convolution units with an exchange unit across the parallel units", and in "Network instantiation" part says "The 2nd, 3rd, 4th stages contain 1, 4, 3 exchange blocks, respectively", which I think are 3, 4, 4, and how the number "1, 4, 3" are obtained, please?
I've also check the related paper of your "Deep High-Resolution Representation Learning for Visual Recognition", "HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation", "High-Resolution Representations for Labeling Pixels and Regions" and source code but cannot understand, hope you could give me an interpretation,thanks very much!
According to my understanding,
In "Deep High-Resolution Representation Learning for Human Pose Estimation", a "exchange block" is equal "modularized block" in "Deep High-Resolution Representation Learning for Visual Recognition". The modularized block is divided into two
components: multi-resolution parallel convolutions (Figure 5 (a)), and multi-resolution fusion (Figure 5 (b)).
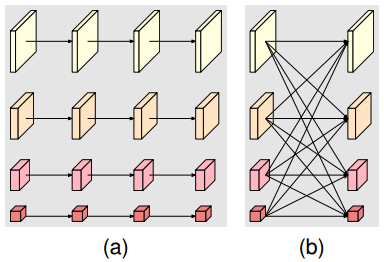 The 2nd, 3rd, 4th stages contain 1, 4, 3 exchange blocks in the picture above, respectively.
The figure 1 in "Deep High-Resolution Representation Learning for Human Pose Estimation" and the figure 2 in "Deep High-Resolution Representation Learning for Visual Recognition" are not a complete HRNet neural network structure diagram.
The 2nd, 3rd, 4th stages contain 1, 4, 3 exchange blocks in the picture above, respectively.
The figure 1 in "Deep High-Resolution Representation Learning for Human Pose Estimation" and the figure 2 in "Deep High-Resolution Representation Learning for Visual Recognition" are not a complete HRNet neural network structure diagram.