NBA-Machine-Learning-Sports-Betting
 NBA-Machine-Learning-Sports-Betting copied to clipboard
NBA-Machine-Learning-Sports-Betting copied to clipboard
Issue for using future information as input data
I found a possible problem in your model inputs. basically, I think when you scraped the historical team data, for a certain team, at a certain day, the data scrapped has included its current day matches stats. for example, lets say the nba team data for 11/2/2021, you use that to predict the matches on 11/2/2021. However that nba team data is already including the teams win/lost information on that day. To me I think this will impact results a lot at season start.
I assume the input for the model should be the team data from previous day. Please check if this is correct.
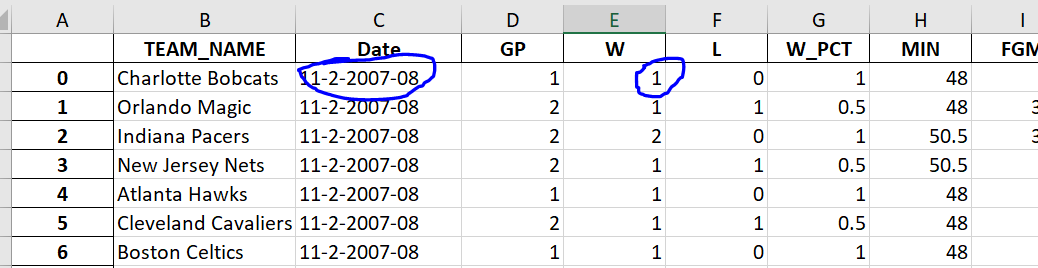 Here is an example.
For this row of data, the charlotte has never played a game before 11/2/2007, so theoretically the nba team data shouldn't have win loss counts for this team.
Here is an example.
For this row of data, the charlotte has never played a game before 11/2/2007, so theoretically the nba team data shouldn't have win loss counts for this team.
I do think you are technically correct on this one. I don't like to run early in the season and wait about a month till averages start to form for these stats. I think this would be a great improvement in the future.
Feel free to contribute as well. I have so many ideas and improvements for this with not much free time to do everything. 😊
11/2/2021, you use that to predict the matches on 11/2/2021
For this its usually run before any games have been played for that day. I think this only comes into training.
Yes I notice this too. This will mostly affect training and backtesting.
Interesting fact. I tried retraining the model using previous day data, it turns out that the percentage of wins keeps similar, but the ability to beat the win/lose odds data is no longer good. It seems the one day diff is huge lol.
By any chance can you share to code for this? Id love to take a look and see what I can do. @supersheepbear
percentage of wins keeps similar, but the ability to beat the win/lose odds data is no longer good
Can you explain more in depth on what you mean by this? @supersheepbear
percentage of wins keeps similar, but the ability to beat the win/lose odds data is no longer good
Can you explain more in depth on what you mean by this? @supersheepbear
Yes. Here are explanations:
-
To address the issue in previous comments, I created new training data on my own. When combining everyday matches data set(in your repository these are derived from odds data), with the team stats data, I now attempt to select the team stats data from previous day, instead of the current day. For example: For matches at 4/6/2022, now the team stats are from 4/5/2022 I was trying to do everything from scratch instead of using your code, just to be clear on what I was doing. My code is here for reference: https://github.com/supersheepbear/nba_ml/blob/master/nba_ml/app/combine_score_stats/main.py
-
Then I used my training data sets to train a NN model, which uses exactly same code from your Train_Model.py Note: I only trained on money lines. I did not test on your train xgboost module. My model's accuracy on my data set is around 67%
My trained code is here for reference: https://github.com/supersheepbear/nba_ml/blob/master/nba_ml/app/train_nn/main.py
My trained model is saved here: https://github.com/supersheepbear/nba_ml/tree/master/bin/models/nn_2022-04-05_23-22-10
- I did some back testing which used the models to predict 2019 to 2022 matches results, and then simulated bettings against odds data (same as what you did in your personal tests folder)
Similar to what you did, my strategy is to bet 1 dollar when the predictions indicates a win on one side of the team.
- When using the model you trained, on the training data set you had(which has the issue of using current data team stats) to make predictions, the betting simulated result is amazing. I believe you had the same conclusion in your personal test folder.

links to the backtesting jupyter notebook: https://github.com/supersheepbear/nba_ml/blob/master/notebooks/backtest_2019_to_2022_using_current_day_team_stats/backtest.ipynb
- When using the model I trained, the training data I just created(which used the previous day team stats) to make predictions, the betting simulated result is not good anymore:

links to the backtesting jupyter notebook: https://github.com/supersheepbear/nba_ml/blob/master/notebooks/backtest_2019_to_2022_using_previous_day_team_stats/backtest.ipynb
Please note that I also tried using the model you trained to predict on my training data set, it is similarly having a bad result, Which indicates the problem is the dataset, and not the model.
Conclusion:
- Correcting the training data set yields a 67% predicton accuracy
- Correcting the training data set can no longer has good predictions, which win in betting against odds.
Personally I don't understand why today's team stats is so important for the predictions to win againts odds. In season start I can understand it makes a big different, the thing is in season end it also makes a big difference, which I do not have a good explnation.
Thank you for all that. Ill take a look and make some changes. I think one thing too is that I trained thousands of models with tons of different NN architectures. I suspect playing around with that might help as well. Thank you for all this ill keep you updated.
One more thing, try XGBoost as well. My best results have come from that specifically.
@kyleskom Hi, I have interested in this prediction code! I have some questions. 1.Have you used the LSTM model to predict? Or just use regression model? 2. Have you tried to used only one season's data to train and predict? I think the data of different seasons may make the model unreliable. The most important is the player. 3. How you get the data from NBA?
Hi @KuoEuran 1.) I have not tried a LSTM model but would like to in the future. (Unless you want to contribute id love to look) 2.) I have not. I wasn't sure if 1 season or maybe a few would be enough data. 3.) I just hit the NBA's stat site endpoints and parse the JSON.
@supersheepbear Is correct in this, and I checked the NBA stats endpoint to verify.
I also created a scraping script in C# which pools each day, each player individually. As I am more interested in player props as there is more of an edge (My own personal beliefs). For the model inputs, I used the players data for the first set, then a combinate of all the people who will play in the game averaged (minus the player in question) and finally the opponent teams lineup and data. This should help for it to understand when players are in-out-covid-inquired.
I also limited the data to the last 10 games (though still testing) as I believe using the entire season will help with money line/O-U but I am not sure it will help with player props.
I am still downloading data (Done about 140 days so far from this season only), but I am getting somewhere around 32% accuracy for guessing the amount of assists a single person will get.
@kyleskom I would highly suggest maybe storing the data you scrap individually, and not as a summed value. This will really allow your to adjust when high profile players are out. (You can also scrap from Rotowire, who is injured and such before each run).
Maybe even adding something a new field like "games_missed" which show how long ago the player missed from the lineup.
If you want a datadump, I can assist if you need it (when I have it completed), but almost all my code is in C#.
@supersheepbear Just to confirm, you went back and grabbed the last 10+ years of data with the fix you made, or you just trained on 1 year?
@supersheepbear Just to confirm, you went back and grabbed the last 10+ years of data with the fix you made, or you just trained on 1 year?
Yes I grabbed all previous 10 years data for training. I used the same data source that the repo was using, i.e: from the NBA stats website.
The more I thought about this, @supersheepbear Is correct, but partially. Yes, how the data is included is bad, but I dont think it would cause such a change in performance. It would early in the season, but late in the season, 1 game would barely change the numbers. @kyleskom Can you confirm that there is no other models your using (Formats) that might cause this change?
I think one thing too is that I trained thousands of models with tons of different NN architectures.
@kyleskom You mentioned this. Are you sure the model you provided with us in the final build is produced by the same settings in the train folder?
Unfortunately I can not guarantee that the architecture is the same for the provided mode. It would be close but its been many years and not sure.