metrics-server
 metrics-server copied to clipboard
metrics-server copied to clipboard
Metrics Server connection refused in Prometheus Target
Metrics server Deployment file on kubernetes
apiVersion: v1 kind: ServiceAccount metadata: labels: k8s-app: metrics-server annotations: prometheus.io/scrape: "true" name: metrics-server namespace: kube-system
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: k8s-app: metrics-server app.kubernetes.io/instance: prometheus app.kubernetes.io/component: metrics rbac.authorization.k8s.io/aggregate-to-admin: "true" rbac.authorization.k8s.io/aggregate-to-edit: "true" rbac.authorization.k8s.io/aggregate-to-view: "true" annotations: prometheus.io/scrape: "true" name: system:aggregated-metrics-reader rules:
- apiGroups:
- metrics.k8s.io resources:
- pods
- nodes verbs:
- get
- list
- watch
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: k8s-app: metrics-server annotations: prometheus.io/scrape: "true" name: system:metrics-server rules:
- apiGroups:
- "" resources:
- nodes/metrics verbs:
- get
- apiGroups:
- "" resources:
- pods
- nodes verbs:
- get
- list
- watch
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: labels: k8s-app: metrics-server annotations: prometheus.io/scrape: "true" name: metrics-server-auth-reader namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: extension-apiserver-authentication-reader subjects:
- kind: ServiceAccount name: metrics-server namespace: kube-system
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: labels: k8s-app: metrics-server annotations: prometheus.io/scrape: "true" name: metrics-server:system:auth-delegator roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:auth-delegator subjects:
- kind: ServiceAccount name: metrics-server namespace: kube-system
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: labels: k8s-app: metrics-server annotations: prometheus.io/scrape: "true" name: system:metrics-server roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:metrics-server subjects:
- kind: ServiceAccount name: metrics-server namespace: kube-system
apiVersion: v1 kind: Service metadata: labels: k8s-app: metrics-server annotations: prometheus.io/scrape: "true" name: metrics-server namespace: kube-system spec: ports:
- name: https port: 9104 protocol: TCP targetPort: https selector: k8s-app: metrics-server
apiVersion: apps/v1 kind: Deployment metadata: labels: k8s-app: metrics-server name: metrics-server namespace: kube-system annotations: prometheus.io/scrape: "true" spec: selector: matchLabels: k8s-app: metrics-server strategy: rollingUpdate: maxUnavailable: 0 template: metadata: labels: k8s-app: metrics-server annotations: prometheus.io/scrape: 'true' spec: hostNetwork: true containers: - args: - --cert-dir=/tmp - --kubelet-insecure-tls - --secure-port=4443 - --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname - --kubelet-use-node-status-port - --metric-resolution=40s command: - /metrics-server - --kubelet-insecure-tls - --kubelet-preferred-address-types=InternalIP image: k8s.gcr.io/metrics-server/metrics-server:v0.6.2 imagePullPolicy: IfNotPresent livenessProbe: failureThreshold: 3 httpGet: path: /livez port: https scheme: HTTPS periodSeconds: 10 name: metrics-server ports: - containerPort: 4443 name: https protocol: TCP readinessProbe: failureThreshold: 3 httpGet: path: /readyz port: https scheme: HTTPS initialDelaySeconds: 20 periodSeconds: 10 resources: requests: cpu: 100m memory: 200Mi volumeMounts: - mountPath: /tmp name: tmp-dir serviceAccountName: metrics-server volumes: - emptyDir: {} name: tmp-dir
apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: labels: k8s-app: metrics-server annotations: prometheus.io/scrape: "true" name: v1beta1.metrics.k8s.io spec: group: metrics.k8s.io groupPriorityMinimum: 100 insecureSkipTLSVerify: true service: name: metrics-server namespace: kube-system version: v1beta1 versionPriority: 100
Prometheus values.yaml scrape configuration Added
- job_name: 'metric-server-pods'
scrape_interval: 10s
metrics_path: /apis/metrics.k8s.io/v1beta1/pods
static_configs:
- targets: ["LoadBalancerIP:9104"]
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: pod
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: pod
Prometheus Target Error

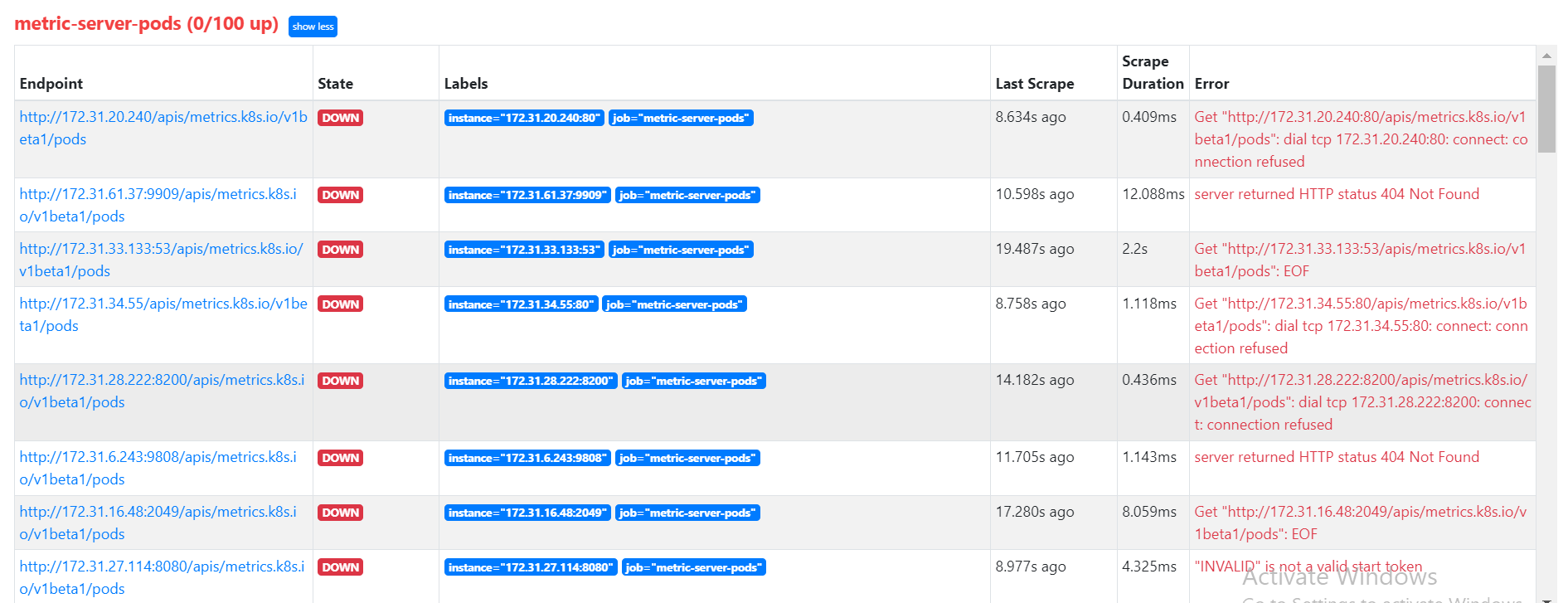
While connect with prometheus we are facing this issue can someone please suggest any solution for this error.
The Kubernetes project currently lacks enough contributors to adequately respond to all issues.
This bot triages un-triaged issues according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Mark this issue as fresh with
/remove-lifecycle stale - Close this issue with
/close - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/lifecycle stale
The Kubernetes project currently lacks enough active contributors to adequately respond to all issues.
This bot triages un-triaged issues according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Mark this issue as fresh with
/remove-lifecycle rotten - Close this issue with
/close - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/lifecycle rotten
Sorry we didn't get to look at your issue. Are you still facing this? If you are, can you properly format your description so we can read the yaml? E.g. with ``` YAML ``` /assign @dgrisonnet /triage accepted
This issue has not been updated in over 1 year, and should be re-triaged.
You can:
- Confirm that this issue is still relevant with
/triage accepted(org members only) - Close this issue with
/close
For more details on the triage process, see https://www.kubernetes.dev/docs/guide/issue-triage/
/remove-triage accepted
The Kubernetes project currently lacks enough active contributors to adequately respond to all issues and PRs.
This bot triages issues according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Reopen this issue with
/reopen - Mark this issue as fresh with
/remove-lifecycle rotten - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/close not-planned
@k8s-triage-robot: Closing this issue, marking it as "Not Planned".
In response to this:
The Kubernetes project currently lacks enough active contributors to adequately respond to all issues and PRs.
This bot triages issues according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied- After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied- After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closedYou can:
- Reopen this issue with
/reopen- Mark this issue as fresh with
/remove-lifecycle rotten- Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/close not-planned
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes-sigs/prow repository.