read_namespaced_job_status doesn't report failed job
What happened (please include outputs or screenshots): I'm using python client to receive job status from kubernetes API. However it seemed like it doesn't report job status properly.
Actual
status.failed is None
Expected
status.failed should be not None
job_api = client.BatchV1Api()
job = job_api.read_namespaced_job_status(name="test", namespace="prefect")
job.status
{'active': None,
'completed_indexes': None,
'completion_time': None,
'conditions': [{'last_probe_time': datetime.datetime(2022, 3, 29, 10, 37, 15, tzinfo=tzutc()),
'last_transition_time': datetime.datetime(2022, 3, 29, 10, 37, 15, tzinfo=tzutc()),
'message': 'Job has reached the specified backoff limit',
'reason': 'BackoffLimitExceeded',
'status': 'True',
'type': 'Failed'}],
'failed': None,
'ready': None,
'start_time': datetime.datetime(2022, 3, 29, 10, 31, 25, tzinfo=tzutc()),
'succeeded': None,
'uncounted_terminated_pods': None}
This is the payload received using kubectl
kubectl get jobs -n prefect test
apiVersion: batch/v1
kind: Job
metadata:
creationTimestamp: "2022-03-29T10:31:25Z"
labels:
controller-uid: 9836903a-812d-4379-8b43-2d9f6e23aac9
job-name: test
name: test
namespace: prefect
resourceVersion: "108867733"
uid: 9836903a-812d-4379-8b43-2d9f6e23aac9
spec:
backoffLimit: 6
completions: 1
parallelism: 1
selector:
matchLabels:
controller-uid: 9836903a-812d-4379-8b43-2d9f6e23aac9
template:
metadata:
creationTimestamp: null
labels:
controller-uid: 9836903a-812d-4379-8b43-2d9f6e23aac9
job-name: test
name: test
namespace: prefect
spec:
containers:
- env:
- name: HOST
value: 1.2.3.4
- name: PORT
value: "1"
image: registry.gitlab.com/phangiabao/postgres-cluster-swarm/test-prefect:0.0.8
imagePullPolicy: IfNotPresent
name: test
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: OnFailure
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
status:
conditions:
- lastProbeTime: "2022-03-29T10:37:15Z"
lastTransitionTime: "2022-03-29T10:37:15Z"
message: Job has reached the specified backoff limit
reason: BackoffLimitExceeded
status: "True"
type: Failed
startTime: "2022-03-29T10:31:25Z"
Environment:
- Kubernetes version (
kubectl version): v1.21.1 - OS (e.g., MacOS 10.13.6): Windows 10
- Python version (
python --version): Python 3.9.10 - Python client version (
pip list | grep kubernetes): 23.3.0
/assign
Hi @ptsp01, please try this command kubectl get jobs -n prefect test -ojson, usually, it will show failed: 1 like below
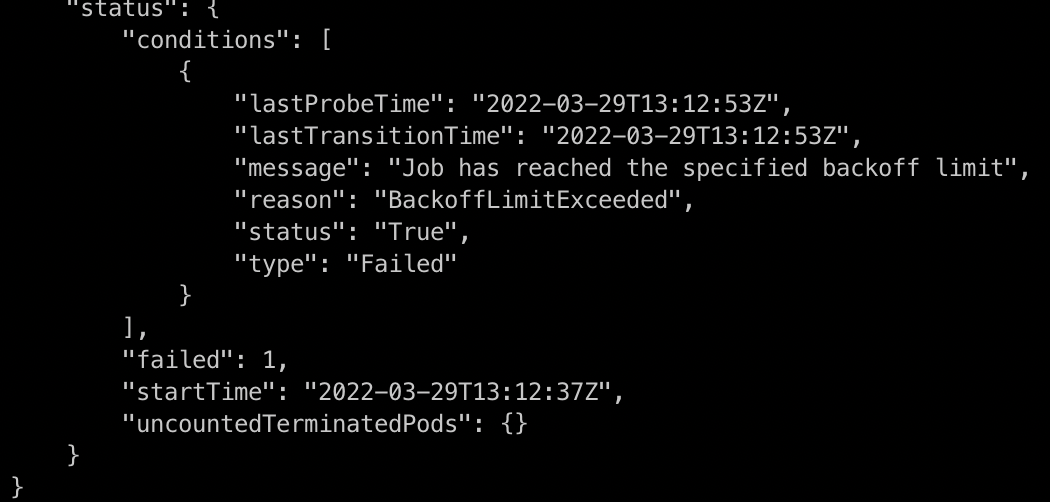
Thanks, but doing that in cli doesn't help the python implementation. How can I workaround this in kubernetes-client?
Thanks, but doing that in cli doesn't help the python implementation. How can I workaround this in
kubernetes-client?
The purpose of using CLI is getting job status from kubernetes directly, compare it with the printout of your script. Consider your python client version is 23.3.0 higher than kubernetes version, you can try to degrade the python client version to 21.0 or lower, because I run your scrip on my testing cluster(kubernetes 21.1, python client 18.0) and got the right response.
@ptsp01 In your https://github.com/kubernetes-client/python/issues/1766#issue-1184705898, status.failed is None in both the Python client and kubectl (note that in kubectl, the field gets omitted). Any reason that you expect the Python client to show a different result?
The Kubernetes project currently lacks enough contributors to adequately respond to all issues and PRs.
This bot triages issues and PRs according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Mark this issue or PR as fresh with
/remove-lifecycle stale - Mark this issue or PR as rotten with
/lifecycle rotten - Close this issue or PR with
/close - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/lifecycle stale
The Kubernetes project currently lacks enough active contributors to adequately respond to all issues and PRs.
This bot triages issues and PRs according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Mark this issue or PR as fresh with
/remove-lifecycle rotten - Close this issue or PR with
/close - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/lifecycle rotten
The Kubernetes project currently lacks enough active contributors to adequately respond to all issues and PRs.
This bot triages issues and PRs according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Reopen this issue or PR with
/reopen - Mark this issue or PR as fresh with
/remove-lifecycle rotten - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/close
@k8s-triage-robot: Closing this issue.
In response to this:
The Kubernetes project currently lacks enough active contributors to adequately respond to all issues and PRs.
This bot triages issues and PRs according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied- After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied- After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closedYou can:
- Reopen this issue or PR with
/reopen- Mark this issue or PR as fresh with
/remove-lifecycle rotten- Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/close
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.