java
 java copied to clipboard
java copied to clipboard
SharedIndexInformer does not work while watching the kubernetes event
Describe the bug The SharedIndexInformer does not work while watching the kubernetes event.
Client Version
<dependency>
<groupId>io.kubernetes</groupId>
<artifactId>client-java</artifactId>
<version>13.0.0</version>
</dependency>
Kubernetes Version
1.18
Java Version
Java 8
To Reproduce See below "Additional context"
Expected behavior The informer should always work and watch the event of kubernetes.
KubeConfig
N/A
Server (please complete the following information):
- OS: [Linux]
- Environment [container]
- Cloud [Azure SG ]
Additional context The problem is after several days running, I saw there is no log printed in the log file, and check the data of service-pod map which stored in the memory cache is not correct. Seems the watch stop working.
such as below image:

Based on the timestamp in log file , our IT supporter says "kubernetes apiserver connection timeout at that time".
Is there any suggestion on this ?
Below is my code sample:
public void run() {
if ("Y".equals(this.k8sTemplate.getK8sCfgProperties().getEnable())) {
k8sTemplate.prepareApiClient(0, TimeUnit.SECONDS);
CoreV1Api api = new CoreV1Api();
try {
log.info("try to init the endpoints......");
k8sTemplate.init(api); // initial
log.info("try to watch the endpoints......");
Thread.sleep(500);
RetrieveKubernetesPodsJob.kubInitFlag = true;
Executors.newSingleThreadExecutor().execute(() -> {
k8sTemplate.watch(api); // then create a single thread to trigger the watching
});
}
catch (Exception e) {
log.error("Exp : " + e.toString());
}
}
else {
log.info("The k8s.config.enable is not Y, don't start the k8s init and watch job.");
}
}
public class KubTemplate {
private static final Log log = LogFactory.getLog(KubTemplate.class);
public static SharedInformerFactory sharedInformerFactory = null;
......
public ApiClient prepareApiClient(int timeout, TimeUnit timeUnit) {
ApiClient client = null;
try {
client = ClientBuilder.cluster().build();
Configuration.setDefaultApiClient(client);
}
catch (IOException e) {
log.error("[getApiClient]Exp : " + e.toString());
}
return client;
}
public void init(CoreV1Api api) {
......
}
public void watch(CoreV1Api coreV1Api) {
SharedInformerFactory factory = new SharedInformerFactory();
sharedInformerFactory = factory;
SharedIndexInformer<V1Endpoints> nodeInformer = sharedInformerFactory
.sharedIndexInformerFor((CallGeneratorParams params) -> {
return coreV1Api.listEndpointsForAllNamespacesCall(null, null, null,
null, null, null, params.resourceVersion, null,
params.timeoutSeconds, params.watch, null);
}, V1Endpoints.class, V1EndpointsList.class);
nodeInformer.addEventHandler(new ResourceEventHandler<V1Endpoints>() {
@Override
public void onAdd(V1Endpoints ep) {
String namespace = ep.getMetadata().getNamespace();
String name = ep.getMetadata().getName();
if (StringUtils.hasText(name) && StringUtils.hasText(namespace)
&& !"default".equals(namespace)
&& !"kube-system".equals(namespace)) {
String serviceName = name.toLowerCase().trim();
log.info("[watch] add V1Endpoints " + serviceName + "." + namespace);
// do something
}
}
@Override
public void onUpdate(V1Endpoints oldEp, V1Endpoints newEp) {
String namespace = newEp.getMetadata().getNamespace();
String name = newEp.getMetadata().getName();
if (StringUtils.hasText(name) && StringUtils.hasText(namespace)
&& !"default".equals(namespace)
&& !"kube-system".equals(namespace)) {
log.info("[watch] update V1Endpoints old: "
+ oldEp.getMetadata().getName() + ", new: " + name + "."
+ namespace);
String serviceName = name.toLowerCase().trim();
// do something
}
}
@Override
public void onDelete(V1Endpoints ep, boolean deletedFinalStateUnknown) {
String namespace = ep.getMetadata().getNamespace();
String name = ep.getMetadata().getName();
if (StringUtils.hasText(name) && StringUtils.hasText(namespace)
&& !"default".equals(namespace)
&& !"kube-system".equals(namespace)) {
log.info("[watch] delete V1Endpoints " + name + "." + namespace);
String serviceName = name.toLowerCase().trim();
// do something
}
}
});
sharedInformerFactory.startAllRegisteredInformers();
}
}
we have the same problem, no error, seems sometimes it will stop watch. maybe this issue https://github.com/kubernetes-client/java/issues/896 need to reopen.
Have a look at this here:
https://github.com/kubernetes-client/java/issues/1370
And see if that fixes it for you? If so we should add that to client initialization.
Hrm, looks like this is fixed in the 14.0.0 release:
https://github.com/kubernetes-client/java/pull/1498/files#diff-05af68ab89a99b7dd1b192fb42e908803b22fd66bb12263e5cd88710dd4cca4aR382
Can you try updating to 14.0.0?
Hrm, looks like this is fixed in the 14.0.0 release:
https://github.com/kubernetes-client/java/pull/1498/files#diff-05af68ab89a99b7dd1b192fb42e908803b22fd66bb12263e5cd88710dd4cca4aR382
Can you try updating to 14.0.0?
OK, I will try this version. Thanks. @brendandburns
@GitHub-Yann did this fix things for you?
It's running successfully for 6 days . We will keep monitoring this.
For this issue, I think we can close it right now. I will post futher monitor info on this issue.
Thanks.
Hi @brendandburns , At March 12, Our IT upgraded the confiuration of the kubernetes master node.
Today, March 14, I found my watch project was stopped.
In this project, It has 2 jobs: (1) watch the kubernetes event ; (2) pull the server list from eureka server every 30 seconds.
from below image, we can see the kubernetes watch log was stopped at march 12 , 22:00 , but the eureka pull log is always printing.
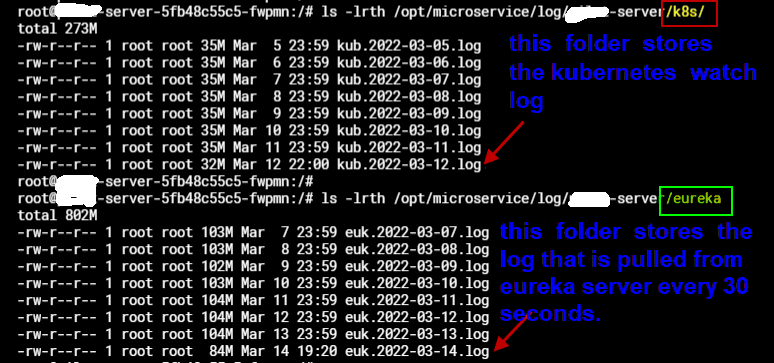
@GitHub-Yann Did you find a solution? We hit a similar issue after API server overwhelmed and restarted: some informers are still working while one of them stop getting updates.
@haoming-db No. After restart the project, we are still monitoring it and waiting the response. If you can tolerate the delay , I think you can pull the k8s service-pod list every fixed time like eureka。
Hi @GitHub-Yann, I recently found a potential bug: https://github.com/kubernetes-client/java/issues/2183#issue-1181153693 Base on my local experiments, once that bug is resolved, the watch call will have client-side timeout every 5-10mins, and will trigger a redo of list-watch. This will make sure your informer doesn't stuck forever - in worst case at least it can "re-list" from API server every 5-10 mins.
@haoming-db No. After restart the project, we are still monitoring it and waiting the response. If you can tolerate the delay , I think you can pull the k8s service-pod list every fixed time like eureka。
Hi @haoming-db , Can you share the main logic of your watch code ?
My usage is in my first comment.
The Kubernetes project currently lacks enough contributors to adequately respond to all issues and PRs.
This bot triages issues and PRs according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Mark this issue or PR as fresh with
/remove-lifecycle stale - Mark this issue or PR as rotten with
/lifecycle rotten - Close this issue or PR with
/close - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/lifecycle stale
The Kubernetes project currently lacks enough active contributors to adequately respond to all issues and PRs.
This bot triages issues and PRs according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Mark this issue or PR as fresh with
/remove-lifecycle rotten - Close this issue or PR with
/close - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/lifecycle rotten
The Kubernetes project currently lacks enough active contributors to adequately respond to all issues and PRs.
This bot triages issues and PRs according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied - After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied - After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closed
You can:
- Reopen this issue or PR with
/reopen - Mark this issue or PR as fresh with
/remove-lifecycle rotten - Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/close
@k8s-triage-robot: Closing this issue.
In response to this:
The Kubernetes project currently lacks enough active contributors to adequately respond to all issues and PRs.
This bot triages issues and PRs according to the following rules:
- After 90d of inactivity,
lifecycle/staleis applied- After 30d of inactivity since
lifecycle/stalewas applied,lifecycle/rottenis applied- After 30d of inactivity since
lifecycle/rottenwas applied, the issue is closedYou can:
- Reopen this issue or PR with
/reopen- Mark this issue or PR as fresh with
/remove-lifecycle rotten- Offer to help out with Issue Triage
Please send feedback to sig-contributor-experience at kubernetes/community.
/close
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.