btrfs-progs
 btrfs-progs copied to clipboard
btrfs-progs copied to clipboard
BTRFS restore question for a broken array during Bcache conversion. Possible UUID problem? Corrupt blocks.
A RUN DOWN So I was doing some stress testing on my 10 disk raid 10 than I have been running for close to 2 years. This will be the 2nd recovery I have done on this same dataset. The reason for the broken state is primary user in-put related (My fault). So I have had really good luck using BTRFS with Bcache. As long as you don't do a forced power off which causes a drop of the cache state and you are unable to boot until you re-online the drives in a chroot than reboot again. I have also found out its much better to use both Bcache and BTRFS as built in modules.
HOW IT HAPPENED So I have done a lot of risky things with BTRFS like yanking 3 drives out of my raid 10 to replace them and rebalance. I don't seem to have any issues when stressing BTRFS in this manner as long as its done smart and not toying with the balance command in the process but either after the new drives are inserted or to issue the commands carefully 1 at a time before removal. What I have noticed is some issues related to stupid user input and the BTRFS balancing function. So this is what I did, I was quickly converting my personal 10 disk raid 10 that is comprised of 10 3TB matching drives to lay on top of Bcache. I removed 2 drives by using parted / wipefs to remove the BTRFS partitions followed by a 5 sec shred command on 2 of the 3 drives just to make sure I killed the superblocks on those 2 removed BTRFS drives. I also noticed that if you just use parted to clear the BTRFS partition it will eventually recover it self and reinsert into the array(NICE). This was the force removal process for me I usually do a few drives at a time during a storage upgrade, I use the device delete command on the missing drives with a degraded mount and than balance. I know this is not the smartest way, but I do it for saving time and it tends to work good for me as long as I am not stupid about it. But this time I took it a bit too far, partly on purpose. So on the 3rd drive I decided to do something a bit different, I removed the drive and decided to my self I wanted to insert it and remove it correctly. So I inserted it again, after about 60-120ish seconds the drive was properly reinserted into the array while the other 2 drives where missing. This is when the issue occurred. I issued a BTRFS device delete command on david 1 (Not a new Bcache based drive) than decided I did not want to wait so long to do it that way. I pressed control C...... 0.o The device delete command was running for close to about 60 seconds before cancel. Right when I canceled the array went into a degraded mode and refused to remount in RO after i rebooted. I did all of the worst moves without going below 6 drives out of 10 disk array. I also did not write data back to the 6 drives in the array. So theoretically all the data should be on the array still in some form or fashion as it was balanced prior. I was aware I was pushing my luck but decided this would be a good time to get some more experience on BTRFS data recovery since I use it for a lot of projects. . As I could not remount with the backup root or in R/O mode at all it seems.
Data / Metadata across entire array 95% Balanced Estimate across 10 drives
btrfs filesystem show /dev/sdc (This is interesting)
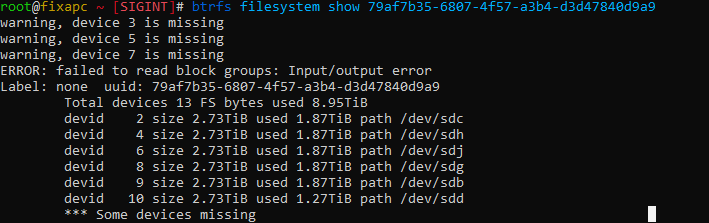 As you can see it is only showing 3 missing davids..... but david 1 is clearly missing.
As you can see it is only showing 3 missing davids..... but david 1 is clearly missing.
also used a hand full of other options but i forgot a lot of them.
Mount Options Attempted On Array /w dmesg output (It gets interesting here)
mount -t btrfs /dev/sdc /mnt/BROKENEVERYTHING

mount -t btrfs -o degraded /dev/sdc /mnt/BROKENEVERYTHING

mount -t btrfs -o rescue=usebackuproot,degraded /dev/sdc /mnt/BROKENEVERYTHING

Cant seem to get this to show in dmesg again, attempting to..... but I forgot the mount options I used. Anyway as you can see it is showing the original 3 missing UUIDs here and not including the added Bcache devices that are also missing, which it should. Almost as if the BTRFS filesystem is split into 2 different chunks or trees? I dunno I am not an expert, I am just making a good guess. I also noticed that the UUID of the bcache btrfs based drives had a different UUID instead of the same btrfs UUID. I think this might have something to do with some damage done here.

BTRFS RESTORE So I decided after that and a few more attempted RO mount options, it wasn't going to mount. So I moved onto the restore. I was able to recover about 40% of the data with this command, it seems as if most of the bigger files are the ones not able to recover. But i personally don't think I am using the recovery options to their full potential and I need to get this down, its very important to me and my line of work.
btrfs restore -i -v /dev/sdc /mnt/BROKENEVERYTHING Also attempted to run this with a few tree root backups I found in the dump-super -af. About half of them wouldn't even start the restore process but the other ones seem to give the same result as the standard restore command. I feel as if I am not using the recovery options to their full potential?
BTRFS Inspect
btrfs inspect-internal dump-super -af /dev/sdf
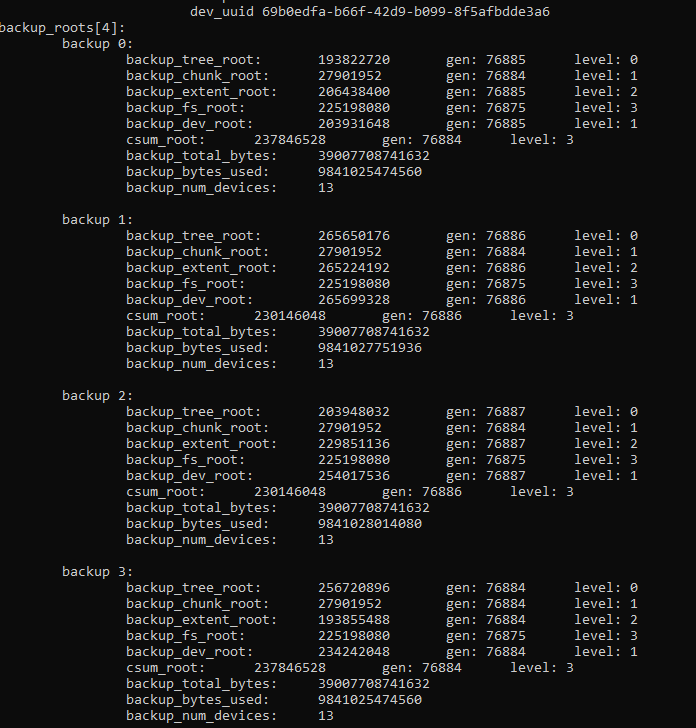
BRTFS FS CHECK, wasn't able to get the following running because of the bad block groups. chunk tree?
Also if you look here it is acting similar to the 1 mount option I cant seem to remember.
Basic check

Check with chunkroot backup 3, superblock 2. All the backup chunk root ids seem to be the same?
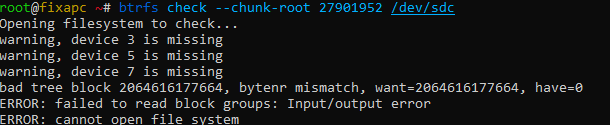
BRTFS RESCUE btrfs rescue chunk-recover /dev/sdc seems to run for a few hours than randomly stop and complain about something a block I think, but not sure I am running it again.
Anyway so I was wondering what else can I do with restore and check to see if I can get more data back? or if I am even using it correctly for a professional level restore? I did some Googling but it seems as if most of what I come up with is bad information.
I removed 2 drives by using parted / wipefs to remove the BTRFS partitions followed by a 5 sec shred command on 2 of the 3 drives just to make sure I killed the superblocks on those 2 removed BTRFS drives.
The story should end here. btrfs raid10 tolerates loss of at most one drive. It can sometimes work after that, if the drives that fail are empty, or the chunk allocator has never allocated anything but full-width chunks in the lifetime of the filesystem, but this is the exception rather than the rule. Loss of 2 or more drives in raid10 is expected to be fatal.
The device delete command was running for close to about 60 seconds before cancel.
That's fairly normal. It has to reach the end of the current block group before it can stop, which can take anywhere from one second to over a day depending on how fast the hardware is and how complex the reference structures are (e.g. lots of snapshots or dedupe).
I removed the drive and decided to my self I wanted to insert it and remove it correctly. So I inserted it again, after about 60-120ish seconds the drive was properly reinserted into the array while the other 2 drives where missing.
At this point there are now 2 drives missing, and a third was offline for some time while the filesystem was mounted? It's not clear exactly what happened here, but if my summary is right, I'm amazed it worked this long. I'd expect the filesystem to be already dead at this point.
It's unclear from the description, but if a device was offline for a while while the filesystem was mounted, and metadata was written at that time, and btrfs wasn't notified that the device was offline, then there might be dropped metadata writes in the filesystem with a later superblock update. This is only recoverable with current tools if there was an online mirror device that received the dropped writes successfully, but this array was already far beyond degraded at the time, so recovery is likely not possible.
I did all of the worst moves without going below 6 drives out of 10 disk array
raid10 tolerates 1 disk failure. Definitely not 4.
I notice that https://btrfs.readthedocs.io/en/latest/mkfs.btrfs.html does not describe the raid10 layout (where it would be clear that in the normal case only one failing drive is recoverable), and the table of redundancy/parity doesn't list the maximum number of failed drives for each profile. That would explain why people keep running into it...
On device-level RAID10, the devices are usually laid out in pairs, and half of the disks can fail as long as the other half contain a complete copy of the data. The entire device is laid out the same way, like the "stripe 100" row in the table below, so there are no devices which are mirror 1 in some sectors and mirror 2 in other sectors.
btrfs does raid at the chunk level, where each individual chunk decides which devices are mirrors and which position the devices have in the stripe array. Different chunks can assign different parts of a device to different raid stripe/mirror positions, so you could have this chunk/stripe/mirror layout:
btrfs device: 1 2 3 4
Chunk 100: s0m1 s0m2 s1m1 s1m2 stripe 0 mirror 1, stripe 0 mirror 2, stripe 1 mirror 1, ...
Chunk 101: s0m2 s1m1 s1m2 s0m1
Chunk 102: s1m1 s0m1 s1m2 s0m2
resulting in this table of chunks that fail when 2 drives are lost:
1 2 3 4 <- second failing disk
1 none - - - OK, 1 disk failed, all stripes recoverable with surviving mirror
2 101 none - - Chunk 101 is unrecoverable, both mirrors of stripe 0 lost
3 102 101 none - Chunk 102 is unrecoverable, both mirrors of stripe 1 lost
4 101 102 100 none Chunk 100 is unrecoverable, both mirrors of stripe 1 lost
^ 1st failing disk
In this example, all possible combinations of 2 failing drives cause unrecoverable loss, and no single drive failure causes unrecoverable loss.
In special cases (e.g. even number of devices, all the same size, no allocator quirks in the filesystem history), all the chunks have the same device assignments, because the chunk allocator is mostly deterministic (e.g. it assigns devices in ID order, and with equal-sized devices it would have no reason to stagger the first device ID in the chunk), so removing 2 devices will happen to work; however, as soon as an odd number of devices appears in the system, a new and different set of device assignments may appear, reducing the failure tolerance to exactly one device.
But i personally don't think I am using the recovery options to their full potential
The potential of the current recovery options is very limited, and you have already exceeded their capability. Currently if the root nodes or interior nodes are lost, the only option is to work on better recovery tools. The missing tool is a brute force scan of the devices for metadata pages to rebuild interior nodes of the on-disk trees. Without the interior nodes, everything in the filesystem that is stored behind a missing node is inaccessible.
About half of them wouldn't even start the restore process but the other ones seem to give the same result as the standard restore command.
That's also normal. Only the last two roots are guaranteed to be accessible, and the pages from deleted roots get recycled pretty quickly.
So what your saying is regardless of the drive count on the raid 10 array you are only able to withstand a 1 device failure?
This is generally not how the average raid 10 works. I feel this statement is made more of a safety precaution and are directed to the consumer end user. The reason i say this is because i have already had instances with drive failures of more than 2 on larger raid 10 systems and i was still able to restore not just the data but the mounting functionality as well.
Just taking a guess but if the meta data was pinned to drives outside of the failure would this make it easier to recover data? the reason I am guessing it might is because if the meta data was still in perfect condition wouldn't it make it easier for the file system to cover data on the broken array?
How much of the meta data is used for the recovery process it self anyway?
If anyone needs me to get some debugging info for them let me know.
This is generally not how the average raid 10 works.
All raid10 implementations tolerate 1 to N/2 failures at random, depending on which devices fail, but the maximum guaranteed recoverable number of failures is always 1. In btrfs the probability distribution is skewed closer to 1 than to N/2.
have already had instances with drive failures of more than 2 on larger raid 10 systems and i was still able to restore not just the data but the mounting functionality as well.
Yes, it works if you constrain the allocator in exactly the right way and you are lucky enough that both failures affect separate failure domains, but enforcing that in btrfs would prevent the possibility of profile conversion, mixed-sized arrays, different metadata + data profiles, or odd numbers of disks, without guaranteeing that 2 disk failures can be tolerated in all cases.
If you want to reliably survive 2 disk failures, you need raid6, raid1c3, or raid1c4 (which tolerates up to 3 failures).
Just taking a guess but if the meta data was pinned to drives outside of the failure would this make it easier to recover data?
In general if there are surviving mirrors of the metadata then btrfs can recover from any individual device (or sector) failure. It doesn't matter where those mirrors are--btrfs will try to read each of them, and if successful, try to correct the failed ones (i.e. if the drive is online but has a bad sector or corruption).
If you use raid1c3 profile for metadata then the metadata is replicated on 3 drives, and can survive 2 failures. If you combined raid10 data with raid1c3 metadata and lost 2 devices storing copies of the same stripe, you'd be able to keep up to half of the files under 64K. btrfs would be read-only at that point (num_tolerated_failures for raid10 is 1), so you can recover the remaining data, but still have to rebuild the filesystem.
If you use allocation_preference patches, you could place the metadata on more durable devices if you have some way to know which devices will fail in advance. e.g. you have some new NAS-grade NVMe and a whole lot of crappy old desktop spinners, you can make a frankenstein machine that would keep the filesystem metadata alive on the NVMe while the data crumbles to dust on the spinners. It's not a recommended way to build a storage box, but it might be able to squeeze another year or two out of hardware that otherwise would be in the recycle bin. If the NVMe devices fail anyway, then you still have to use a metadata profile that can tolerate the number of devices that fail.
How much of the meta data is used for the recovery process it self anyway?
btrfs normally requires all of the metadata. It is organized into a pseudo-Merkle tree that can detect losses of a single bit, and in most cases will force read-only mode when a single-bit loss is detected. It relies on the raid profiles to keep multiple copies of the entire metadata at all times to survive failures ranging from single bit flips to total loss of a device.
Metadata is organized into trees. The leaf pages contain the filesystem, while the root and interior node pages contain pointers to the leaves. The leaf pages can be located anywhere (copy-on-write metadata requires this), so the filesystem relies heavily on the root and interior node pages to be able to find anything on the device. Most of the tools (even restore and repair) assume the root and interior nodes are intact, and can't access leaf pages at all if there is damage to the roots or interior nodes.
More than 99% of the metadata is in the leaf pages, but none of the leaf pages can be accessed if the remaining less-than-1% of interior node and root pages are lost. Even a small number of damaged metadata pages is equivalent to the loss of the entire device. dup metadata is the default on single-device filesystems, so that metadata can be recovered if there's a bad sector or silent corruption. Without an extra copy, 1% of single-bit errors in the metadata would break the filesystem. Even the other 99% require btrfs check --repair or btrfs restore as the kernel will refuse to read corrupt metadata.
In theory a tool could be developed to brute-force scan the device for metadata leaf pages and build a new filesystem containing their items, which would allow recovery even when the root and interior nodes of the tree are lost. There have been some experiments in this direction but nothing that is ready for general use yet.
Not all of the trees need to be intact for repair, e.g. the extent tree can be rebuilt from the subvol trees, the free space tree can be rebuilt from the extent tree, the csum tree can be built by rereading all of the file data (which requires subvol trees), the chunk tree can be rebuilt by brute-force scan of the device, and the log tree can be trivially discarded; however, if there's lost pages in subvol, root, or chunk trees, then the existing tools can't recover.
[edit: subvol, root, or chunk trees. The device items are in the chunk tree]
The server on the bottom that is on top of the HP storage enclosures is what I am currently working with.

Ok there we go, now your speaking my language a bit better I am starting to get a better grasp. So you say i could do a brute scan of the leaf data and and use it to rebuild the meta data? So lets say i wanted to run some last ditch efforts with the check --repair. Can you point me in the correct direction. Or better yet, do you know of any scripts that are in development, for example that use leaf data to rebuild the meta data. I got hardware to use and data to burn, let me in the club to those secret files you got in the back there.
Anyway it is good you replied because i have a much better understanding of the meta data and how important it is in recovering data. It sounds like if you keep the metadata away from the failing devices it helps with the basic data redundancy of the raid array that is basically data only and no metadata.
do you know of any scripts that are in development, for example that use leaf data to rebuild the meta data
Development at https://lore.kernel.org/linux-btrfs/[email protected]/ has been going on since March and still hasn't recovered a filesystem yet. It is highly experimental, and you'll need the developer's help to use it (assuming he has the bandwidth for more users at this point). It's the only serious attempt to build a recovery tool that I have seen in public.
if you keep the metadata away from the failing devices it helps with the basic data redundancy of the raid array that is basically data only and no metadata.
It's not really helping, it just puts the metadata in a different place, and hoping that place is better. If you have bad luck choosing SSD models, and the ones you pick are lemons that all break on the same day, then it's worse than mixing random drives together and having failures at the average random rate. Allocation preferences don't normally help with resilience except if you can predict the future, or you expect failure rates much higher than normal for some reason.
The key point is to respect the number of tolerated failures in the profiles you are using, and fully recover from degraded mode as quickly as possible, to avoid exceeding the tolerated failure limit. Dropping two disks at a time from a raid10 array is not the way to achieve that.
My question is, is that possible to make two same metadata (Single disk or single partition or RAID 0 has two same metadata) if one of 2 is broken but last one survives to recover possible data? (Idea: Broken metadata is easily repaired or overwritten which is the same as healthy metadata.)
I think two same metadata like twins give you a good chance to recover data when using single partition or disk, and make mount more stable without failure of mount with partition.
Are there new problems when using two identical metadata? Performance issue? implementation problem?