Speech-enhancement
 Speech-enhancement copied to clipboard
Speech-enhancement copied to clipboard
MemoryError
I have the memory problem,
when I run
python main.py
it tells me : MemoryError
Ram :16G is not enough ? Win10
Maybe only one file in train/noisy/, train/clean/ So I think change the aug will be better, I just set the aug=20 in make_train_noisy.m But in matlab it ups: `错误使用 parallel.internal.pool.deserialize (line 27) 内存不足。请键入 HELP MEMORY 查看选项。
出错 distcomp.remoteparfor/getCompleteIntervals (line 257) results{i} = parallel.internal.pool.deserialize(data(2));
出错 make_train_noisy (line 34) parfor i = 1:1:size(temp_timit_list, 1)`
Help Me SOS
I am getting the following error when running python's main.py.
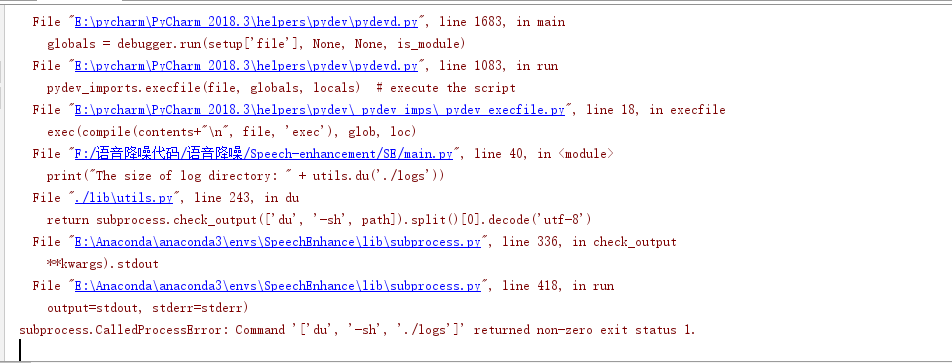
 I changed the value of aug in the make_train_noisy.m file from 1 to 30, and the computer configuration I used was 64G RAM.
I changed the value of aug in the make_train_noisy.m file from 1 to 30, and the computer configuration I used was 64G RAM.
1.shape= (1647829359,) 2.shape= (183092151,)
Traceback (most recent call last):
File "main.py", line 85, in
In the
feat_phase = np.concatenate((feat.reshape(-1), phase.reshape(-1)))
the first arg's shape (1647829359,),the second is (183092151,),
When I found the same shape args,
x=np.random.randn(1647829359)
y=np.random.randn(183092151)
z=np.concatenate(x,y)
It tells me
Traceback (most recent call last): File "<pyshell#10>", line 1, in <module> z=np.concatenate((x,y)) MemoryError
@MayMiao0923 其实raw文件大小一样,你的aug=30,那就是30个同样大的raw文件 你不妨先试试aug=1时能不能跑的通, 我都不知道内存是如何直接增加到这么大的。
我去试试看,我是借用学院的电脑跑的aug=30的,但是我的8G的内存是可以跑aug=15的 @ucasiggcas
卧槽,我16G的咋就不行啊, 告诉我内存出错, 一脸懵逼
也就是说 这里的Python程序 全部需要在Linux环境下运行么?
---Original--- From: "Lychee Tsu"[email protected] Date: Thu, Jun 20, 2019 12:09 PM To: "jtkim-kaist/Speech-enhancement"[email protected]; Cc: "MayMiao0923"[email protected];"Mention"[email protected]; Subject: Re: [jtkim-kaist/Speech-enhancement] MemoryError (#11)
给你提示下吧, 那个计算文件大小的函数只能下Linux下跑。
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub, or mute the thread.
In order to treat memory error you should reduce the length of training wav (.raw file). The default setting is for 64G ram setting.
 @ucasiggcas
@ucasiggcas
In order to treat memory error you should reduce the length of training wav (.raw file). The default setting is for 64G ram setting.
I have reduced the length,
but it tells me
Traceback (most recent call last): File "main.py", line 85, in <module> tr.main([prj_dir, logs_dir]) File "./lib\train.py", line 313, in main train_dr = dr.DataReader(train_input_path, train_output_path, norm_path, dist_num=config.dist_num, is_training=True, is_shuffle=False) File "./lib\datareader.py", line 66, in __init__ % (np.shape(self._inputs)[0], np.shape(self._outputs)[0])) AssertionError: # samples is not matched between input: 709660 and output: 1419319 files
How to solve the problem ?
Edited: The first have solved !
and
2.
if I reduce the length of raw,
should I modify the norm mat coming from
prj_dir/SE/get_norm.py
Thx @jtkim-kaist
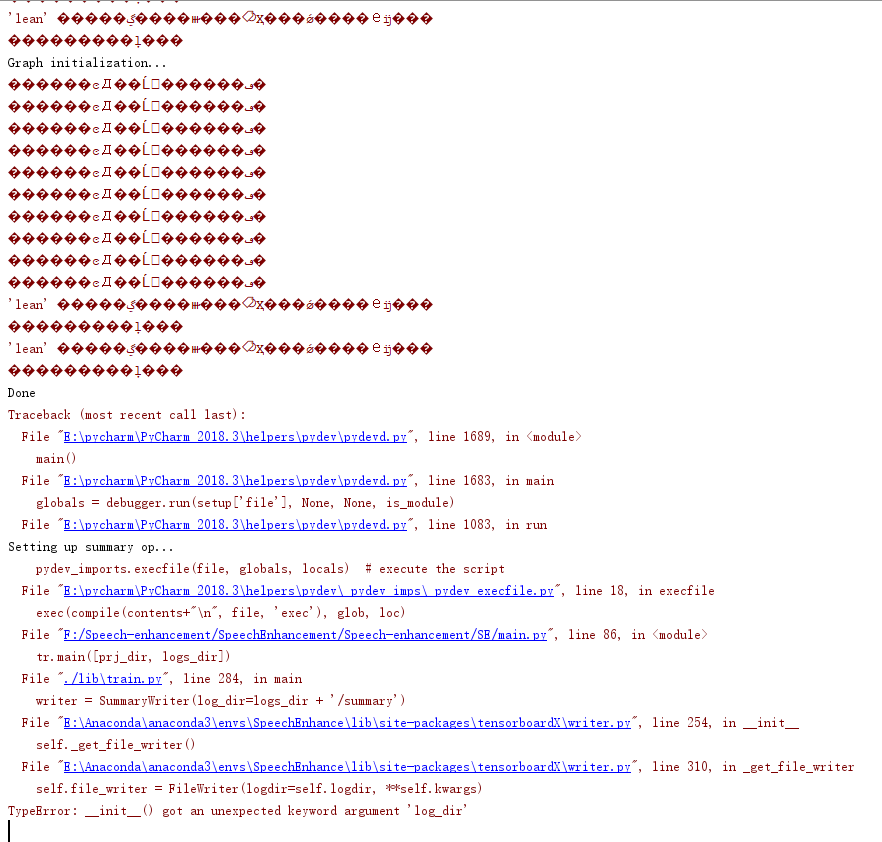
那一个版本 一脸懵
---Original--- From: "Lychee Tsu"[email protected] Date: Thu, Jun 20, 2019 18:28 PM To: "jtkim-kaist/Speech-enhancement"[email protected]; Cc: "MayMiao0923"[email protected];"Mention"[email protected]; Subject: Re: [jtkim-kaist/Speech-enhancement] MemoryError (#11)
大佬,你有没有跑过其他语言方面的项目给我介绍下
你的这个很明显是版本问题 你help下这个函数即可解决。
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub, or mute the thread.
Other questions
Traceback (most recent call last): File "main.py", line 85, in <module> tr.main([prj_dir, logs_dir]) File "./lib\train.py", line 313, in main train_dr = dr.DataReader(train_input_path, train_output_path, norm_path, dist_num=config.dist_num, is_training=True, is_shuffle=False) File "./lib\datareader.py", line 62, in __init__ self._outputs, self._output_phase = self._read_output() # (batch_size, freq) File "./lib\datareader.py", line 329, in _read_output return np.squeeze(feat), phase UnboundLocalError: local variable 'feat' referenced before assignment
`Traceback (most recent call last): File "D:\python\lib\site-packages\PIL\Image.py", line 2460, in fromarray mode, rawmode = _fromarray_typemap[typekey] KeyError: ((1, 1, 129), '|u1')
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "main.py", line 85, in
And
It's really not easy to reproduce the project.
Memory manage, no queue or stack 2. Structure py files more, model not clear and feature either 3. More dependencies For a deep learning project, I think there are no more than 5 files
- data feature extraction include preprocess, data input
- model for NN
- training include queue or stack for feature input , and model save
- test the model
只训练了1000次就出现了第4个错误,升级PIL都不能解决,不知道哪里有问题。
这个枕头库其实没必要,在Summary中怎么需要画图,更何况shape=(1, 1, 129)的数据真不知道怎么画图,要么RGB图(M* N* 3),要么灰度图-纯二维数据图,(M*N),
1* 1* 129你让我如何画图?如何reshape ? 不明所以。 如果不是在这里修改,而是其他地方有错导致这个地方出差错,那么我真不知道怎么修改了, 代码这么复杂,一点都不简便,复杂的是结构,不是代码本身。
不知道作者怎么就没有出现这个错误, 不能否认,总有人一帆风顺,而我诸事不易。
I think it is because lack of explanation about code structure.
As you said,
1 : data feature extraction include preprocess, data input : datareader.py 2 : model for NN : trnmodel.py 3 : training include queue or stack for feature input , and model save : train.py 4 : test the model : test_full.py
Other py files are just for utility.
Also, memory management problem is my fault.
If you run my code successfully, let me know.
About your question,
-
Just use your previous produced norm file (not very sensitive to new dataset)
-
I have not met that error before plz compare original code.
-
that error can be fixed: link