JoltPhysics
 JoltPhysics copied to clipboard
JoltPhysics copied to clipboard
MeshShape integration issues / data ingress
I'm trying to integrate mesh shapes into an existing code base and I ran into performance regressions with MeshShape, and I had a few thoughts about the interface.
Right now you fill a MeshShapeSettings, which has std::vector<>s for vertices and indices, and pass that to the MeshShape constructor. Bullet, on the other hand, provides an interface through which the caller can expose read-only views into vertex and index data, which is a much better interface: https://github.com/bulletphysics/bullet3/blob/master/src/BulletCollision/CollisionShapes/btStridingMeshInterface.h#L53
- With MeshShape, I need to create, fill, and destroy STL containers, even though I might have the data right here in memory from a decompressed file on disk usually
- Bullet lets me specify vertex stride, supporting packed formats and alignment padding
- Bullet allows u16 and u32 indices, while MeshShapeSettings use the latter, so small meshes (and custom collision meshes) which are the majority need a processing step. Bullet handles existing index format via PHY_* types.
- Bullet supports multi-part meshes which are common in some scenarios esp in editor
What's a good path to enable MeshShape to directly access existing data and avoid copies / etc?
Just for reference, I asked a couple of related questions in #52, those may be of interest to you, too.
In regards to this specific question:
Jolt preprocesses your mesh data and puts it into its own internal, optimized format. As long as you go through the MeshSettings object to begin with, you are already wasting performance, because all that work has to be done. The additional copy of data is probably the least you should worry about. The simple fact is, you are doing the "cooking" / "baking" (however you want to call it) at runtime.
What you should do instead, is to set up your MeshSettings object, then create a shape from it (this is the slow / inefficient part) and then use Jolts functionality to serialize the final shape state to disk. At this point, the result is literally just an array of bytes to you.
My code for this can be found here: https://github.com/ezEngine/ezEngine/blob/9f8dc34f11b91db72dc2c6314a951dca87f99268/Code/EnginePlugins/JoltCooking/JoltCooking.cpp#L107
At runtime, once you need that collision shape, you just feed that piece of memory to JPH::Shape::sRestoreFromBinaryState to create the shape. This uses a JPH::StreamIn object, so you can store the data in any container you like.
See an example here: https://github.com/ezEngine/ezEngine/blob/9f8dc34f11b91db72dc2c6314a951dca87f99268/Code/EnginePlugins/JoltPlugin/Resources/JoltMeshResource.cpp#L384
I found this to be the most efficient way, as I can now move the baking process out of the runtime. You can also share the same mesh shape across many bodies, which is quite interesting for convex shapes. Here I ran into the problem that I couldn't reuse the same shape with different user data and different materials and density. Jorrit suggested to wedge a custom Decorated shape in between for this, which works really nicely for me. Sample code here: https://github.com/ezEngine/ezEngine/blob/dev/Code/EnginePlugins/JoltPlugin/Shapes/Implementation/JoltCustomShapeInfo.h
Hope that helps.
I'm not sure our use cases are similar, I don't have a shipping title where I can pre-bake things - this is a content creation tool and the user can (and does) change the tri mesh geometry in-app or via changing linked files on disk.
wrt cooking, isn't this just kicking the can down the road? Cooking would also be faster if I can decompress / load mesh to sysmem then feed it to Jolt's bvh builder without the memcpy. Slower cooking times mean lower iteration rate, so even in a scenario like yours with pre-processed fixed assets, it'd still be a win.
If your use case requires in-app cooking, then yes, you are correct that the interface currently doesn't allow you to pass the data along as efficiently as possible.
As jankrassnigg said, the MeshShapeSettings struct is indeed meant for offline cooking. The structure is serializable, which is why it needs its own copy of the data. I think if you profile the copying of data to the MeshShapeSettings struct you'll find that it is a small portion of the total build time, so I don't think it's worth it to try to optimize this.
W.r.t. multi part meshes, I'd recommend sticking the mesh parts in a StaticCompoundShape. Construction of a StaticCompoundShape should be fast and, if you provide a temp allocator, not do any extra allocations beyond what is needed to store the shape.
B.t.w. How much slower is building a mesh shape than before? The builder code was originally written to allow testing as many different tree types as possible (see https://github.com/jrouwe/RayCastTest) and I'm sure I can make it a lot faster if I make it specific for the mesh shape (it does a ton of allocations for example and copies the results in a separate pass).
I did a bit of profiling with the following test code (converts a heightfield mesh 100 times):
const int n = 100;
const float cell_size = GetWorldScale() * 1.0f;
const float max_height = GetWorldScale() * 3.0f;
// Create heights
float heights[n + 1][n + 1];
for (int x = 0; x <= n; ++x)
for (int z = 0; z <= n; ++z)
heights[x][z] = max_height * PerlinNoise3(float(x) * 8.0f / n, 0, float(z) * 8.0f / n, 256, 256, 256);
// Create regular grid of triangles
TriangleList triangles;
triangles.reserve(2 * n * n);
for (int x = 0; x < n; ++x)
for (int z = 0; z < n; ++z)
{
float center = n * cell_size / 2;
float x1 = cell_size * x - center;
float z1 = cell_size * z - center;
float x2 = x1 + cell_size;
float z2 = z1 + cell_size;
Float3 v1 = Float3(x1, heights[x][z], z1);
Float3 v2 = Float3(x2, heights[x + 1][z], z1);
Float3 v3 = Float3(x1, heights[x][z + 1], z2);
Float3 v4 = Float3(x2, heights[x + 1][z + 1], z2);
triangles.push_back(Triangle(v1, v3, v4));
triangles.push_back(Triangle(v1, v4, v2));
}
//VertexList vertices;
//IndexedTriangleList indexed_triangles;
//Indexify(triangles, vertices, indexed_triangles);
uint64 time = GetProcessorTickCount();
vector<ShapeRefC> shapes;
const int num_shapes = 100;
shapes.reserve(num_shapes);
for (int i = 0; i < num_shapes; ++i)
{
MeshShapeSettings settings(triangles);
//MeshShapeSettings settings(vertices, indexed_triangles);
shapes.push_back(settings.Create().Get());
}
uint64 delta = GetProcessorTickCount() - time;
// Calculate hash to check we didn't change the output of the algorithm
stringstream str;
StreamOutWrapper stream_out(str);
shapes.front()->SaveBinaryState(stream_out);
size_t h = 0;
while (!str.eof())
{
char c;
str >> c;
hash_combine(h, c);
}
// Trace timing / hash
Trace("%.2f %ld", double(delta) / GetProcessorTicksPerSecond(), h);
The profile looks like this:
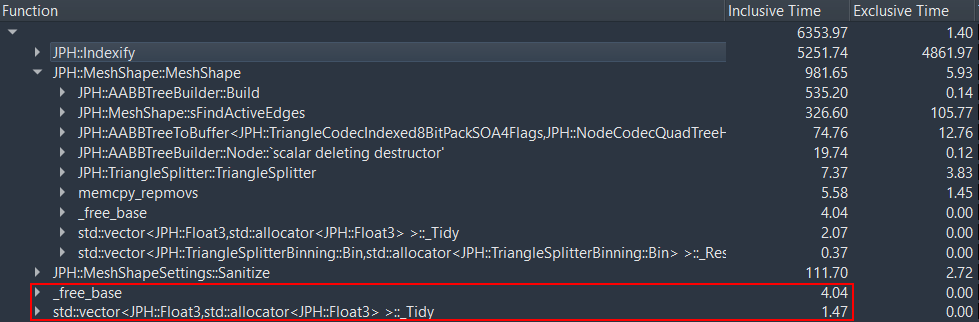
So the allocations / memcpy's you're worried about (red border) are lost in the noise.
I've optimized the MeshShape constructor and made it approximately 30% faster in #147. It spends most of its time now in actual calculations and not in allocations. The main culprit is the Indexify function (it's a very naive O(N^2) implementation to convert a triangle list to a vertex list + indexed triangle list). I'm not sure if you're already passing indexed triangles to the MeshShapeSettings object or not, but if you are providing a triangle list then that will be your bottleneck.
I quickly searched the internet for a better algorithm but didn't immediately find something. I can come up with something, but if you know of an algorithm please let me know.