neural-style
 neural-style copied to clipboard
neural-style copied to clipboard
Any ports to Python?
I'm struggling to get the Lua script to run on a Jupyter Notebook on Google Colab but can't get past this error. Only building the dependencies with Luarocks took me about an hour, but since I went offline the virtual machine was restarted and I'll have to start all over.
Does anyone know of a port to Python? ...or, maybe some transcompiler to convert the Lua script to Python?
I'm asking because both languages are very similar, also my guess is that all dependencies should be available for Python too, since it's kind of the de-facto programming language when working with those kind of things.
Keep up the good work!
There is no shortage of python implementations, and google finds most of them.
I personally like this http://pytorch.org/tutorials/advanced/neural_style_tutorial.html mainly because it is the clearest description of the process too.
I've heard that the various Python implementations don't seem to be on par with the Lua implementation yet.
I've heard that the various Python implementations don't seem to be on par with the Lua implementation yet.
I wonder what shortcomings there are then, if the actual process is the same. Missing features can be added if one knows python. Pytorch itself started as a port of torch to python, but has already developed beyond torch in terms of functionality. I see most new projects using either pytorch or tensorflow, and find myself already starting to forget lua and torch.
@htoyryla
Missing features can be added if one knows python.
You can also use Torch7's Lua modules in Pytorch.
I've been wanting to translate Neural-Style into PyTorch for a while now. But I am not as proficient in Python as I am in Lua.
I haven't been able to find any PyTorch versions of Neural-Style that had the same features as Neural-Style does already. Some of the examples like the one on the official PyTorch site, are very limited and they don't do things the same way as Neural-Style. For example, autograd seemingly causes differences in the Lua version if you compare szagoruyko's neural-style-autograd, and jcjohnson's neural-style. So I imagine PyTorch is no different with things like this.
For an accurate comparison between Torch7 and PyTorch, I'd like to keep things as similar as possible.
I have found https://github.com/anishathalye/neural-style to be a nice python port using tensorflow. most of the features translate in a similar way so I have been able to modify my bash scripts accordingly. The fine tuning is a little tricky, but I am getting there.
the main differences are in -init image is --initial (path to file) and the checkpoints for iterations need to be specified differently. --checkpoint-iterations 10 --checkpoint-output (filename)%s.jpg
On Sat, Feb 24, 2018 at 1:43 PM ProGamerGov [email protected] wrote:
@htoyryla https://github.com/htoyryla
Missing features can be added if one knows python.
You can also use Torch7's Lua modules in Pytorch.
I've been wanting to translate Neural-Style into PyTorch for a while now. But I am still learning Python.
I haven't been able to find any PyTorch versions of Neural-Style that had the same features as Neural-Style does already. Some of the examples like the one on the official PyTorch site, are very limited and they don't do things the same way as Neural-Style. For example, autograd seemingly causes differences in the Lua version if you compare szagoruyko's neural-style-autograd https://github.com/szagoruyko/neural-style-autograd, and jcjohnson's neural-style. So I imagine PyTorch is no different with things like this.
For an accurate comparison between Torch7 and PyTorch, I'd like to keep things as similar as possible.
— You are receiving this because you are subscribed to this thread. Reply to this email directly, view it on GitHub https://github.com/jcjohnson/neural-style/issues/450#issuecomment-368192564, or mute the thread https://github.com/notifications/unsubscribe-auth/ARL-abcfM16VlmUWPiwesBfgpKY_jOLOks5tX3dBgaJpZM4SLU6_ .
For Tensorflow, there is also neural-style-tf: https://github.com/cysmith/neural-style-tf
It does pretty much everything Neural-Style does along with masked style transfer and "Artistic style transfer for videos". But I was talking about the lack of options for PyTorch.
I've got a basic PyTorch style transfer script setup to try and copy neural_style.lua, but I am having issues trying to implement the normalization step that takes places during the backward step.
https://gist.github.com/ProGamerGov/1cef6405c822e10272535131ef70143e

I'm also not sure how to get the -style_scale working, seeing as the style and content images need to be the same size?
I could always use lutorpy, but I feel like that would result in it's own issues. But it could be useful to try and use loadcaffe in order to load the same caffemodels as neural_style.lua.
Looks like I should be using PyTorch's save_for_backward.
@htoyryla I've got the model setup stuff mostly working now, but it crashes when you try to run forward/updateOutput for the content loss capture step.
The error log: https://gist.github.com/ProGamerGov/67a638af58dec47c18815dab370ebf34
This line causes the error: https://gist.github.com/ProGamerGov/a19cf54e3c65f714fca03eb6b4c300ce#file-test2-py-L96
I'm not sure if I have hit a bug in PyTorch, or if the error is because of something I need to fix in my scripts.
I made post on the PyTorch Github page about this issue: https://github.com/pytorch/pytorch/issues/5607
I am sorry to say, but I fail to see the logic of this part https://gist.github.com/ProGamerGov/a19cf54e3c65f714fca03eb6b4c300ce#file-modelsetup-py-L26-L39 . It seems to me you are messing up the pretrained cnn model there. Making this too difficult.
In my view, one should simply
- create an empty sequential net
- take the pretrained cnn.features
- loop through the layers in cnn.features, adding them to net, one by one
- if the added layer is a content layer, add a content loss module immediately after it
- if the added layer is a style layer, add a style loss module immediately after it
Do not try to modify any existing layer, most likely you will lose the pretrained weights if you try. Any layer you extract from cnn is already a valid, working and pretrained pytorch layer, just use it. Only add the loss modules after the correct layers and that's it.
This is what how the model is set up in Justin's lua code, too (except for the modification of pooling layers if needed... that can be done as a pooling layer has no pretrained weights).
PS. Of course, using the layers from the pytorch pretrained VGG-19 will result in using real pytorch layers, not legacy ones, if that is a problem to you. If you insist on using nn.legacy, then you should not use the torchvision.models.vgg19 either (as the legacy module is for using legacy torch models).
If you want absolutely want to go that way, then I think it is possible, in lua torch, to save the caffemodel into to t7 file, and the in legacy pytorch to import the t7 file and save it as a pth file. I've done that a few times, I think. But I prefer to work in real pytorch by now, so much easier.
@htoyryla I ditched my idea of "replacing layers" because that basically broke the model. I've successfully setup the steps you described, for both the legacy and non legacy versions of PyTorch.
I have a legacy version of my code, which requires a .t7 model. The image processing and deprocessing are not working correctly, and I can't seem to get to output a stylized image (though it does output "changed images"): https://gist.github.com/ProGamerGov/360195eaa5ed480b5755285667a59975
To convert a caffemodel to a compatible .t7 format, I used this script: https://github.com/jcjohnson/cnn-benchmarks/blob/master/convert_model.lua. If you set it's backend parameter to cudnn, then PyTorch gives you an error.
For the vgg19 test model, I used this caffemodel which was stripped of it's FC Layers: https://style-transfer.s3-us-west-2.amazonaws.com/vgg19.caffemodel
Edit:
This script will handle downloading and converting the models: https://gist.github.com/ProGamerGov/41fd356be1673ab8bf92aa66fd31fd2d
This is a bunch of code from my legacy setup, that I've ported to regular PyTorch: https://gist.github.com/ProGamerGov/59136b1492ebeff89072927dcc6b7814
The error message that running it causes:
Traceback (most recent call last):
File "st.py", line 206, in <module>
optimizer.step(feval)
File "/usr/local/lib/python2.7/dist-packages/torch/optim/lbfgs.py", line 101, in step
orig_loss = closure()
File "st.py", line 197, in feval
mod.backward(img, dy.data)
File "/home/ubuntu/neural-style/LossModules.py", line 34, in backward
self.gradInput.add(gradOutput)
RuntimeError: inconsistent tensor size, expected r_ [], t [] and src [1 x 3 x 512 x 682] to have the same number of elements, but got 0, 0 and 1047552 elements respectively at /pytorch/torch/lib/TH/generic/THTensorMath.c:1021
For some reason input.nelement() is never equal to self.target.nelement(), in the ContentLoss backward function: https://gist.github.com/ProGamerGov/59136b1492ebeff89072927dcc6b7814#file-lossmodules-py-L29
I have a legacy version of my code, which requires a .t7 model. The image processing and deprocessing are not working correctly, and I can't seem to get to output a stylized image (though it does output "changed images")
Most likely there is a mismatch somewhere between the [0..1] and [0..255] value ranges. If you are using a t7 file converted from the caffemodel, then the model expects a [0..255] value range minus the mean. You need to debug the values from the point where you read them onwards.
For some reason input.nelement() is never equal to self.target.nelement(), in the ContentLoss backward function:
Most likely there is something wrong with the target. First you feed in an image and capture a target. Later on, when you feed in an image of the same size, you should get an input of the same size.
Only during the initial phase, when we also feed in the style image, does a content loss module ever get something of a different size. It should not matter, as the loss module should ignore it if the program logic is correct.
RuntimeError: inconsistent tensor size, expected r_ [], t [] and src [1 x 3 x 512 x 682] to have the same number of elements, but got 0, 0 and 1047552 elements respectively at /pytorch/torch/lib/TH/generic/THTensorMath.c:1021
1 x 3 x 512 x 682 is indeed equal to 1047552, so there is the right number of elements anyway, but the one is a 4-dimensional tensor (such as output from a layer) and the other has all elements in a single dimension. Somewhere a wrong view()?
@htoyryla I'm not sure if the variables are being shared correctly between the loss functions.
I added self.gradInput to the ContentLoss __init__ function: :https://gist.github.com/ProGamerGov/59136b1492ebeff89072927dcc6b7814#file-lossmodules-py-L12, in order to prevent an error. But I think that may have been a symptom of another problem.
For the legacy version, I think I might have fixed the image processing: https://gist.github.com/ProGamerGov/cd05080818dadd3a9eaafa086685a289
But this the current output:

This is the output with starry_night_crop.png:

Here's starry_night_crop.png with Adam:

This was an earlier failure before I arrived at the above outputs:

Edit:
The x value changes over time in the feval function, just like in Neural-Style (only it seems to start at a different value).
If the image processing is ok, then it may have something to due with the gram matrix code:
Neural-Style uses:
self.gradInput:resize(C, H * W):mm(gradOutput, x_flat)
But I used:
self.gradInput.resize_(C, H * W
self.gradInput = torch.mm(gradOutput, x_flat)
When I tested the Python code setup back in Neural-Style, every still worked ok:
self.gradInput:resize(C, H * W)
self.gradInput = torch.mm(gradOutput, x_flat)
I've also ruled out gradient normalization as the cause.
Maybe these messages when running the optimization, hint at the cause?
Running optimization with ADAM
/usr/local/lib/python2.7/dist-packages/torch/legacy/optim/adam.py:65: UserWarning: tensor1 is not broadcastable to self, but they have the same number of elements. Falling back to deprecated pointwise behavior.
x.addcdiv_(-stepSize, state['m'], state['denom'])
Running optimization with L-BFGS
('<optim.lbfgs>', 'creating recyclable direction/step/history buffers')
/usr/local/lib/python2.7/dist-packages/torch/legacy/optim/lbfgs.py:197: UserWarning: other is not broadcastable to self, but they have the same number of elements. Falling back to deprecated pointwise behavior.
x.add_(t, d)
Second Edit:
Setting -content_weight to 0 with -opimtizer lbfgs, and only using conv layers instead of relu layers, results in the first style layer becoming a NAN:
Iteration: 50 / 1000
Content: nn.ContentLoss loss: 0.0
Style: nn.StyleLoss loss: nan
Style: nn.StyleLoss loss: 2.26559419861e+23
Style: nn.StyleLoss loss: 8.66893296314e+22
Style: nn.StyleLoss loss: 2.16423312435e+23
Style: nn.StyleLoss loss: 1.38950169927e+19
Total loss nan
B
As for the non legacy version:
This was the result of this: https://gist.github.com/ProGamerGov/f94d1ba5defad7725781537de6812c99



I then tried things a bit differently with this: https://gist.github.com/ProGamerGov/9b17315bbbee72e8116c456fc622a5f1

And then some general messing around with these: https://gist.github.com/ProGamerGov/a5283af593cd50b4a33b8fc26ec705bc
That ended up an empty variable:
Traceback (most recent call last):
File "st.py", line 234, in <module>
optimizer.step(feval)
File "/usr/local/lib/python3.5/dist-packages/torch/optim/lbfgs.py", line 101, in step
orig_loss = closure()
File "st.py", line 228, in feval
mod.backward(input, gradOutput)
File "/home/ubuntu/neural-style/LossModules.py", line 111, in backward
self.gradInput = self.gram.backward(input, dG) # Gram Backward
File "/home/ubuntu/neural-style/LossModules.py", line 61, in backward
assert input.dim() == 3 and input.size(0)
AssertionError
@htoyryla Have you done any experimentation involving trying to replicate Neural-Style's abilities in PyTorch?
@ProGamerGov @htoyryla I worked on a PyTorch port for a while last year; I got the basic algorithm working but didn't have time to get it up to feature parity with the Lua version.
I had a really hard time getting good style transfer results with the version of the VGG network provided in the PyTorch model zoo, but it did work once I ported the original caffe version of the VGG network to PyTorch: https://github.com/jcjohnson/pytorch-vgg
@jcjohnson Thanks for the tip regarding the models, my scripts seem to produce "stylized" results now, with the VGG models from pytorch-vgg!
I was able to achieve some sort of DeepDream style transfer:



Though these results are using a slightly modified version of the PyTorch style transfer tutorial loss modules, so they lack features from the original Neural-Style.
I got the basic algorithm working but didn't have time to get it up to feature parity with the Lua version.
@jcjohnson Did you come up with a way to implement gradient normalization and dividing by n twice in StyleLoss, which only takes place in Neural-Style's backwards pass? I've been trying to replicate Neural-Style's backwards loss functions (complete with the backwards criterion pass), but I have a feeling that it may be easier to play to PyTorch's strengths.
I've been trying to debug an issue with my backwards gram pass, and I can't seem to pinpoint the exact cause. For simplicity, both input images used in each test, were 64x64 in size.
This is the error message:
Traceback (most recent call last):
File "st.py", line 258, in <module>
optimizer.step(feval)
File "/usr/local/lib/python2.7/dist-packages/torch/optim/lbfgs.py", line 101, in step
orig_loss = closure()
File "st.py", line 253, in feval
mod.backward(img, dy)
File "/home/ubuntu/PyTorch_NS/LossModules2.py", line 104, in backward
self.gradInput = self.gram.backward(input, dG.grad)
File "/home/ubuntu/PyTorch_NS/LossModules2.py", line 61, in backward
self.gradInput = torch.mm(gradOutput, x_flat)
RuntimeError: size mismatch, m1: [64 x 64], m2: [3 x 4096] at /pytorch/torch/lib/TH/generic/THTensorMath.c:1434
This is my PyTorch code's output:
ubuntu@ubuntu-VirtualBox:~/PyTorch_NS$ python st.py -content_image content_64.jpg -style_image style_64.png -image_size 64
(1L, 3L, 64L, 64L)
(1L, 3L, 64L, 64L)
vgg19
Setting up style layer 1: relu1_1
Setting up style layer 2: relu2_1
Setting up style layer 3: relu3_1
Setting up style layer 4: relu4_1
Setting up content layer 1: relu4_2
Setting up style layer 5: relu5_1
input - gram - forward torch.Size([1, 64, 64, 64])
x_flat - gram - forward torch.Size([64, 4096])
input - gram - forward torch.Size([1, 128, 32, 32])
x_flat - gram - forward torch.Size([128, 1024])
input - gram - forward torch.Size([1, 256, 16, 16])
x_flat - gram - forward torch.Size([256, 256])
input - gram - forward torch.Size([1, 512, 8, 8])
x_flat - gram - forward torch.Size([512, 64])
input - gram - forward torch.Size([1, 512, 4, 4])
x_flat - gram - forward torch.Size([512, 16])
Capturing content targets
input - gram - forward torch.Size([1, 64, 64, 64])
x_flat - gram - forward torch.Size([64, 4096])
input - gram - forward torch.Size([1, 128, 32, 32])
x_flat - gram - forward torch.Size([128, 1024])
input - gram - forward torch.Size([1, 256, 16, 16])
x_flat - gram - forward torch.Size([256, 256])
input - gram - forward torch.Size([1, 512, 8, 8])
x_flat - gram - forward torch.Size([512, 64])
input - gram - forward torch.Size([1, 512, 4, 4])
x_flat - gram - forward torch.Size([512, 16])
Running optimization with L-BFGS
input - gram - forward torch.Size([1, 64, 64, 64])
x_flat - gram - forward torch.Size([64, 4096])
input - gram - forward torch.Size([1, 128, 32, 32])
x_flat - gram - forward torch.Size([128, 1024])
input - gram - forward torch.Size([1, 256, 16, 16])
x_flat - gram - forward torch.Size([256, 256])
input - gram - forward torch.Size([1, 512, 8, 8])
x_flat - gram - forward torch.Size([512, 64])
input - gram - forward torch.Size([1, 512, 4, 4])
x_flat - gram - forward torch.Size([512, 16])
input - gram - forward torch.Size([1, 64, 64, 64])
x_flat - gram - forward torch.Size([64, 4096])
input - gram - forward torch.Size([1, 128, 32, 32])
x_flat - gram - forward torch.Size([128, 1024])
input - gram - forward torch.Size([1, 256, 16, 16])
x_flat - gram - forward torch.Size([256, 256])
input - gram - forward torch.Size([1, 512, 8, 8])
x_flat - gram - forward torch.Size([512, 64])
input - gram - forward torch.Size([1, 512, 4, 4])
x_flat - gram - forward torch.Size([512, 16])
input - gram - backward torch.Size([1, 3, 64, 64])
gradOutput - gram - backward torch.Size([64, 64])
x_flat - gram - backward torch.Size([3, 4096])
(64L, 64L)
(3L, 4096L)
This is what Neural-Style does (modified to print the same values as my PyTorch code:
3
64
64
[torch.LongStorage of size 3]
Setting up style layer 2 : relu1_1
Setting up style layer 7 : relu2_1
Setting up style layer 12 : relu3_1
Setting up style layer 21 : relu4_1
Setting up content layer 23 : relu4_2
Setting up style layer 30 : relu5_1
Capturing content targets
input:size - gram - forward 64
64
64
[torch.LongStorage of size 3]
x_flat:size - gram - forward 64
4096
[torch.LongStorage of size 2]
input:size - gram - forward 128
32
32
[torch.LongStorage of size 3]
x_flat:size - gram - forward 128
1024
[torch.LongStorage of size 2]
input:size - gram - forward 256
16
16
[torch.LongStorage of size 3]
x_flat:size - gram - forward 256
256
[torch.LongStorage of size 2]
input:size - gram - forward 512
8
8
[torch.LongStorage of size 3]
x_flat:size - gram - forward 512
64
[torch.LongStorage of size 2]
input:size - gram - forward 512
4
4
[torch.LongStorage of size 3]
x_flat:size - gram - forward 512
16
[torch.LongStorage of size 2]
Capturing style target 1
input:size - gram - forward 64
64
64
[torch.LongStorage of size 3]
x_flat:size - gram - forward 64
4096
[torch.LongStorage of size 2]
input:size - gram - forward 128
32
32
[torch.LongStorage of size 3]
x_flat:size - gram - forward 128
1024
[torch.LongStorage of size 2]
input:size - gram - forward 256
16
16
[torch.LongStorage of size 3]
x_flat:size - gram - forward 256
256
[torch.LongStorage of size 2]
input:size - gram - forward 512
8
8
[torch.LongStorage of size 3]
x_flat:size - gram - forward 512
64
[torch.LongStorage of size 2]
input:size - gram - forward 512
4
4
[torch.LongStorage of size 3]
x_flat:size - gram - forward 512
16
[torch.LongStorage of size 2]
input:size - gram - forward 64
64
64
[torch.LongStorage of size 3]
x_flat:size - gram - forward 64
4096
[torch.LongStorage of size 2]
input:size - gram - forward 128
32
32
[torch.LongStorage of size 3]
x_flat:size - gram - forward 128
1024
[torch.LongStorage of size 2]
input:size - gram - forward 256
16
16
[torch.LongStorage of size 3]
x_flat:size - gram - forward 256
256
[torch.LongStorage of size 2]
input:size - gram - forward 512
8
8
[torch.LongStorage of size 3]
x_flat:size - gram - forward 512
64
[torch.LongStorage of size 2]
input:size - gram - forward 512
4
4
[torch.LongStorage of size 3]
x_flat:size - gram - forward 512
16
[torch.LongStorage of size 2]
Running optimization with L-BFGS
input:size - gram - forward 64
64
64
[torch.LongStorage of size 3]
x_flat:size - gram - forward 64
4096
[torch.LongStorage of size 2]
input:size - gram - forward 128
32
32
[torch.LongStorage of size 3]
x_flat:size - gram - forward 128
1024
[torch.LongStorage of size 2]
input:size - gram - forward 256
16
16
[torch.LongStorage of size 3]
x_flat:size - gram - forward 256
256
[torch.LongStorage of size 2]
input:size - gram - forward 512
8
8
[torch.LongStorage of size 3]
x_flat:size - gram - forward 512
64
[torch.LongStorage of size 2]
input:size - gram - forward 512
4
4
[torch.LongStorage of size 3]
x_flat:size - gram - forward 512
16
[torch.LongStorage of size 2]
input:size - gram - backward 512
4
4
[torch.LongStorage of size 3]
x_flat:size - gram - backward 512
16
[torch.LongStorage of size 2]
gradOutput:size - gram - backward 512
512
[torch.LongStorage of size 2]
input:size - gram - backward 512
8
8
This is the PyTorch code I was using: https://gist.github.com/ProGamerGov/21e958010d96280d8e0914efcb9269d1
And this is the modified neural_style.lua code that I was using: https://gist.github.com/ProGamerGov/b9d8fa1f65d70af0618010f3075bba94
At a quick glance, this is how it looks to me.
You get this error for an mm operation:
> File "/home/ubuntu/PyTorch_NS/LossModules2.py", line 61, in backward
self.gradInput = torch.mm(gradOutput, x_flat)
RuntimeError: size mismatch, m1: [64 x 64], m2: [3 x 4096]
MM requires that the dimensions of the two matrices are like m x p and p x n, and the result will have dimension m x n. Your error happens in gram:backward where the gradoutput dimensions should be C x C and the input dimensions C x H x W. Obviously, here C is the common dimension. The mm operation can then project the C x C gradient into the input dimensions C x HW.
Now when the error occurs, C = 3, but there is no conv layer having 3 channels at the output, correspondingly there should not be any Gram matrix having input of dimensions 3 x H X W. Perhaps you have the layers mixed up somehow.
This is just a quick comment. Don't have the time to delve deep into this. It is just that it is strange that there should be 3 x H x W input to a gram matrix.
Perhaps you have the layers mixed up somehow.
I have checked the layers, and they are setup correctly as far as I can tell.
So the input to the gram matrix's backwards pass, is the img variable in the feval() function, which is supposed to be the same as neural-style's x variable inside it's feval() function.
Using the format: B, C, H, W = .size(),
At the start of the feval() function, img.size() is:
B: 1 C: 3 H: 64 W: 64
And at the start of neural_style.lua's feval() function, it's pretty much the same for x:size() :
C: 3 H: 64 W: 64
And it get's sent to the StyleLoss and GramMatrix functions, via: local grad = net:updateGradInput(x, dy). But unlike my code:
for mod in style_losses:
mod.backward(img, dy)
for mod in content_losses:
mod.backward(img, dy)
...local grad = net:updateGradInput(x, dy) seems to change x before giving it to StyleLoss::updateGradInput:
C: 512 H: 4 W: 4
Edit:
The forward style loss function in my PyTorch code has it's input.size() correctly changed:
B: 1 C: 64 H: 64 W: 64
Neural-Style's forward style loss function has the same input:size() minus the batch size:
C: 64 H: 64 W: 64
In my StyleLoss backward function input.size() is:
B: 1 C: 3 H: 64 W: 64
For my PyTorch Backward StyleLoss code's, I create dG (which become the gram matrix's gradOutput variable) with:
#dG = Variable(self.G.data, requires_grad=True) #This works?
#dG.backward(self.target.data) #This works?
dG = Variable(self.target.data, requires_grad=True) #This works?
dG.backward(self.G.data) #This works?
But I don't do anything with StyleLoss's input variable before sending it to the gram matrix. And the input variable is basically just img from my feval() function.
So the input to the gram matrix's backwards pass, is the img variable in the feval() function, which is supposed to be the same as neural-style's x variable inside it's feval() function.
Makes no sense to me. You seem to assume that the x use see in feval is an x you have in the loss modules. Feval handles the model level. The loss modules reside inside the model, getting input from the layer below, not directly from the image.
Specifically, the gram matrix gets an input of C x H x W from the ReLU below and outputs a C x C matrix as a representation of the style. In the backward pass of the gram matrix, the difference between the current gram output and the target gram output is run backwards to give the gradients at the gram matrix input, i.e. the output of the ReLU to which the loss module has been added.
In Justin's code, this is quite clear. During the forward pass the style loss module stores the gram matrix output (input is the input to the style loss module from the conv/relu layer).
self.G = self.gram:forward(input)
self.G:div(input:nElement())
then, in the backward pass the difference to the target (dG) is given to gram.backward
local dG = self.crit:backward(self.G, self.target)
dG:div(input:nElement())
self.gradInput = self.gram:backward(input, dG)
So, at the gram matrix output, as therefore also in the backward pass, we always should have C x C matrices. At the input we have C x H x W, the size of the layer to which the loss module has been added.
But I don't do anything with StyleLoss's input variable before sending it to the gram matrix. And the input variable is basically just img from my feval() function.
Then something is wrong. Feval does not, or should not, call the style modules. Feval handles the whole module, and the style modules, being layers inside the model, then get called with the proper input from the correct layer.
You seem to assume that the x use see in feval is an x you have in the loss modules.
I was thinking that the x and dy in net:updateGradInput(x, dy), were being passed into the loss modules.
Then something is wrong. Feval does not, or should not, call the style modules. Feval handles the whole module, and the style modules, being layers inside the model, then get called with the proper input from the correct layer.
This is probably why my backwards pass is not working correctly, as the inputs are incorrect.
So I should probably be using backwards hooks for the backwards style and content loss functions, and then only collecting the loss in the feval function? Because PyTorch (non legacy) doesn't have a .updateGradInput or .backward for nn.sequential objects, and I don't see a way that I can do this without them (unless I am missing something) or backwards hooks (which was suggested to me for editing things inside the backwards pass).
I previous tried to use register_backward_hook() in the model setup portion of my script, but I couldn't make that work (I was following an official PyTorch tutorial from here). I guess then I should somehow be using register_backward_hook() inside the StyleLoss and ContentLoss initialization or forward functions.
So I tried using hooks, and I can change the output image, but I can't seem to make it work: https://gist.github.com/ProGamerGov/d8c5a4e9384ef670ab11549393221d00. The output ends up looking like a bunch of black and white blobs.
I also tried using Gatys' model setup definition idea that let's you grab the outputs from any layer. But his method is highly inefficient when compared to Lua/Torch with neural_style.lua.
Gatys' comment, "800 #works for 8GB GPU, make larger if you have 12GB or more" makes this setup method seem like a dead end, when compared to Neural-Style.
This was my attempt at replicating Gatys' idea with a dynamic custom VGG class: https://gist.github.com/ProGamerGov/17a99ebab50e4fe7079ebc1c40c889a3
So I tried using hooks, and I can change the output image, but I can't seem to make it work
I must say I did not really grasp the need for hooks, but had no time to really try either. One does a backward() and then feval reads the losses from the loss modules. But I have not really worked on neural-style in pytorch, mainly with GANSs, VAEs and some natural language processing. I do realize that using a VGG converted from a caffemodel might place some constrains.
Anyway, the current way of working in pytorch seems to be:
Instead of nn.Sequential, the model is just built in code like this. First define the layers:
self.relu = nn.ReLU()
self.conv1 = nn.Conv2d(1, 64, (5, 5), (1, 1), (2, 2))
self.conv2 = nn.Conv2d(64, 64, (3, 3), (1, 1), (1, 1))
self.conv3 = nn.Conv2d(64, 32, (3, 3), (1, 1), (1, 1))
and in forward() chain them like this:
def forward(self, x):
x = self.relu(self.conv1(x))
x = self.relu(self.conv2(x))
x = self.relu(self.conv3(x))
return x
One doesn't do a backward() on the model, but rather on the loss so that autograd follows the gradients wherever they might lead to.
Neural-style is not, however, a typical model with loss at the output and a backward pass to train the weights. Here, we introduce losses at multiple levels inside the network, do not train the model weights but use the gradient to develop the input image.
It is not self evident to me what this entails. Looking at the pytorch neural-style tutorial, though:
They are using nn.Sequential to build the model. So with luck one could load in the VGG that was converted from the caffemodel.
They are implementing backward() in the loss modules, by first defining self.loss in the forward(), e.g. in the Style loss module:
self.loss = self.criterion(self.G, self.target)
and the calling backward on it in the backward() function:
def backward(self, retain_graph=True):
self.loss.backward(retain_graph=retain_graph)
return self.loss
Looks clear and simple to me. We don't need to do a backward on the whole model, because nothing interesting happens at the model output. Everything depends on the losses measured by the loss modules inside the model.
But wait a minute... if there is no model.backward() how do the loss.backward():s ever get called? In the tutorial they do this in a closure, which corresponds with the feval:
for sl in style_losses:
style_score += sl.backward()
for cl in content_losses:
content_score += cl.backward()
I remember you were calling loss modules from feval, and I did not understand why. Now it makes sense, first one does a model.forward to evaluate losses, and then calls backward() of each loss_module to take care of the gradients. This is because backward is done for the losses, each of which is a kind of an output from the model.
Sounds reasonable, but I am still a bit uneasy about this. Running backward() from multiple points would seem to lead to including the gradients from some loss modules several times. This is because I am thinking that the loss modules are part of the Sequential, so that the gradient from an upper loss module will, during backward, pass thru the lower loss modules, being added to them. Like it happens in the lua/torch code.
It must be, then, that in pytorch, the loss modules are not feedthrough layers but really endpoints of a graph, like outputs. Then we can do a backward on each loss module, so that the gradients will propagate through the model (without passing through other loss modules like in lua/torch neural-style) and only added together in feval (closure). This is clearly a different architecture and leads to different code in the loss modules and feval/closure.
I finally have a working solution which doesn't try to anything on the backwards pass. It follows PyTorch's strengths, and I have gotten many of neural_style.lua's features working in it: https://gist.github.com/ProGamerGov/3731931b00b5cc9dd999e75c129941a2
I had multiple style images working at one point, but I broke it and have yet to fix it.
I also feel like the lack of scaling the style loss to layer, and the lack of gradient normalization, is contributing to some lower quality results when compared to neural_style.lua. Adam also doesn't seem to work properly, but that's probably just a matter of finding the right parameters for it. There are also appear to be some major spikes in GPU usage, that may be somewhat comparable to Neural-Style during the capturing steps.
-image_size 512, -num_iterations 1000:

-image_size 1024, -num_iterations 50:

-image_size 512, -num_iterations 1000:

-image_size 1024, -num_iterations 50:

I also feel like the lack of scaling the style loss to layer
You already have that on this line. In the gram matrix function you divide the gram matrix by B * C * H * W: https://gist.github.com/ProGamerGov/3731931b00b5cc9dd999e75c129941a2#file-lossmodulesnew-py-L33
Therefore this line would divide the gram matrix once more with the same number: https://gist.github.com/ProGamerGov/3731931b00b5cc9dd999e75c129941a2#file-lossmodulesnew-py-L53
That is because the input to style loss forward (being the output from the selected layer) is passed to Gram to calculate the Gram matrix, so input is the same in both functions, of dimensions B * C * H * W which is the same as the number of elements in input.
You could experiment with alternative scaling, like C * C instead of C * H * W. Basically that would change the weight of different style layers, and I think we have experimented on this before.
As to gradient normalization, I would look into torch.nn.utils.clip_grad_norm, see discussion here https://discuss.pytorch.org/t/proper-way-to-do-gradient-clipping/191 . It is just not clear to me how to use it, when optim is calling feval (as opposed to a simple iteration loop where one can modify the gradients before calling optimizer.step().
So previously, I wasn't doing any sort of pre-processing like converting to and from BGR or subtracting/adding the mean pixel values. I also wasn't rescaling from [0, 1] to [0, 255], even though the pytorch-vgg models expect a range of 0 to 255.
I tried to add total variance loss, but I can't seem to get the same effects as the TVLoss module in Neural-Style with the code I was testing out.
Content and style weights are still not working like neural_style.lua. For example, there is almost no difference between a style weight of 1000 and a style weight of 5000. In Neural-Style, there would be a major difference between the two values. I've tried various things to "resolve" this issue, but I haven't been able to solve it thus far.
I tried using torch.nn.utils.clip_grad_norm as per the link you provided, but I was unable to effect things in a noticeable way. Maybe it's because I don't fully understand how neural_style.lua's normalization, is similar to clamping in PyTorch?
Adding proper pre-proccessing and de-processing made a major difference in terms of output image quality:


The Adam optimizer also seems to work now:

There may also be some sort of padding related problem? For example, comparing iteration 150 (left) and iteration 450 (right), after previously stylizing the image at a lower resolution, has a noticeably growing artifact on the right hand side:


Here's the updated code: https://gist.github.com/ProGamerGov/0a4624bd5c06fe72bf7995bcec03b67e
So previously, I wasn't doing any sort of pre-processing like converting to and from BGR or subtracting/adding the mean pixel values. I also wasn't rescaling from [0, 1] to [0, 255], even though the pytorch-vgg models expect a range of 0 to 255.
So it is actually a wonder you got so decent results earlier. The model needs proper value range and channel order to respond as expected.
Content and style weights are still not working like neural_style.lua.
At least now you are doing it different from th epytorch tutorial, where the weight is applied to the input respective gram matrix being passed to the criteria, not to the returned loss:
self.loss = self.criterion(input * self.weight, self.target)
and
self.G = self.gram(input)
self.G.mul_(self.weight)
self.loss = self.criterion(self.G, self.target)
I tried using torch.nn.utils.clip_grad_norm as per the link you provided, but I was unable to effect things in a noticeable way. Maybe it's because I don't fully understand how neural_style.lua's normalization, is similar to clamping in PyTorch?
Clamping is of course not the same as normalization. It just seemed to me that clip_grad_norm was also doing normalization, but maybe I looked too quickly.
Maybe you should simply try, in contentLoss:
def forward(self, input):
if self.mode == 'capture':
self.target = input.detach() * self.strength
elif self.mode == 'loss':
self.loss = self.crit(input * self.strength, self.target)
self.loss.div_(self.loss.norm(0) + 1e-8)
self.output = input
return self.output
Notice also how input in multiplied by strength both in capture and loss, so that they are comparable in the crit function. If you multiply the target but not input in the loss mode, you are comparing blueberries with watermelons.
I am not fully sure if my line above to get the norm is correct, and don't have the time to test. Just note that the indexing in lua starts form 1 but in python from 0.
So it is actually a wonder you got so decent results earlier. The model needs proper value range and channel order to respond as expected.
Yea, I'm surprised that I was even getting a stylized result without any sort of pre-processing. But there were some issues with the sky, which were visible with the Starry Night style image.
At least now you are doing it different from the pytorch tutorial, where the weight is applied to the input respective gram matrix being passed to the criteria, not to the returned loss:
The same issue was occurring with the PyTorch tutorial's way of applying the weights.
Yea, I'm surprised that I was even getting a stylized result without any sort of pre-processing. But there were some issues with the sky, which were visible with the Starry Night style image
If there is BGR/RGB confusion, then the model sees the sky as red, which can make a difference.
This line results in:
self.loss.div_(self.loss.norm(0) + 1e-8)
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation
I think the fix is adding .clone(), but I am not entirely sure if that's the right solution:
self.loss.div_(self.loss.clone().norm(0) + 1e-8)
Cloning like that does not solve this, because the inline division is still there.
If the inline operation is not allowed, have you tried the normal assignment?
self.loss = self.loss.div(self.loss.norm(0) + 1e-8)
Google finds much discussion on this issue, for instance https://discuss.pytorch.org/t/encounter-the-runtimeerror-one-of-the-variables-needed-for-gradient-computation-has-been-modified-by-an-inplace-operation/836
I get the impression that even the above might result in an inplace division, then I would try cloning. That is, calculate the new loss using a clone and put the result in self.loss.
self.loss = self.loss.clone().div(self.loss.norm(0) + 1e-8)
For the content/style weight issue, it seems as though there is some sort of limit that scales higher weights to match the maximum allowed weight value. I've messed around with every possible combination of multiplying by the content/style weights that I can think of, yet nothing seems to make a difference. The output only changes in a way similar to changing the -seed value.
For example, one of the outputs below was created with a normal self.strength multiplication, while the other used self.strength * self.strength:


- For the above examples, I used:
-content_weight 5and-style_weight 15000, and are from iteration 150.
For comparison, this is what -content_weight 5 and -style_weight 15000 looks like with neural_style.lua, at iteration 150:

The other thing is that the output doesn't seem to change over time in a similar way to neural_style.lua. It just continues to look like a slightly more stylized version of an output from the first couple hundred iterations of neural_style.lua, if that makes sense?
For the style scale feature, I have tested values of: 0.425, 0.5, 0.625, 0.75, 0.875, 1, 2, 3, 4, and 4.01. They all seem to work ok, but they also seem to have the same issue I described above (possibly to different extents, depending on the value). Occasionally, even when a seed value is specified, the output image will end up being all black. If you run the code again with the same parameters, it seems to work. No idea what is causing this random all black image (loss values don't change) thing.
Edit:
It seems that the code works pretty much exactly like Neural-Style, if I use an -image_size of 256:
neural_style.lua with -normalize_gradients:


neural_style.lua without -normalize_gradients:


My PyTorch code without your normalize gradients code:


My PyTorch code with your normalize gradients code:


Both the Neural-Style and PyTorch tests used a -content_weight of 5, and a -style_weight of 15000. A two step multiscale resolution setup was used with -image_size 256, and then -image_size 512.
Using the PyTorch doe with a -content_weight of 5, and a -style_weight of 1000:


I should also add that for the first iteration, the content loss is normally zero, and then for the next 1-2 iterations, it's an extremely low value. Then after that, it acts normally like the style loss values.
For the content/style weight issue, it seems as though there is some sort of limit that scales higher weights to match the maximum allowed weight value.
I wonder if some gradient clamping mechanism is at work there.
I should also add that for the first iteration, the content loss is normally zero, and then for the next 1-2 iterations, it's an extremely low value. Then after that, it acts normally like the style loss values.
That is to be expected if you start from the content image rather than noise. From the gist (which is not up to date I realise) I see you have the param init, with default 'random' but here https://gist.github.com/ProGamerGov/0a4624bd5c06fe72bf7995bcec03b67e#file-sts2_4-py-L285 you always start with the content image.
This is the result of -init random. Different content and style weights have the same issue with -init random. I think it may have been working a bit differently before, but even then it still didn't seem to show anything from the content image:


Multiscale resolution with -init_image works, but seems to suffer from the same content/style weight issue to a certain extent:



Here's the updated code with -init_image, and -init random working: https://gist.github.com/ProGamerGov/4cbd29112c9c4e44c13918246df618fb
I wonder if some gradient clamping mechanism is at work there.
I wonder if there is some sort of intentional or unintentional difference between Torch and PyTorch which is causing this "clamping", or if it's due to some sort of bug in my code or in PyTorch? I have been trying to figure this issue out for a while, but I have gotten nowhere.
It may prove useful to construct some sort of simple script which replicates the issue, so that we can more easily track what is happening. This would also allow us to more easily report a potential bug.
I also tried to go use backwards hooks again, to solve the content/style weight problem, with this: https://gist.github.com/ProGamerGov/1c76fb86bea5c113cd974dffa6bc1b0d, and while the hooks did result in some possibly better looking outputs, they didn't seem to solve the issue.
This is the result of -init random. Different content and style weights have the same issue with -init random. I think it may have been working a bit differently before, but even then it still didn't seem to show anything from the content image:
Sounds like the content target might be captured from noise and not the content image. Could be something else also. There are many more ways to go wrong than right.
I wonder if there is some sort of intentional or unintentional difference between Torch and PyTorch which is causing this "clamping", or if it's due to some sort of bug in my code or in PyTorch?
I had in mind, for instance, how the pytorch neural-style tutorial clamps the values between 0 and 1 to keep the pixel values in range, if something like that would have sneaked into your code.
I had in mind, for instance, how the pytorch neural-style tutorial clamps the values between 0 and 1 to keep the pixel values in range, if something like that would have sneaked into your code.
I don't think that's the issue, as clamping only occurs is in the save function here, and (unavoidably) in the image loader here, with this line:
Loader = transforms.Compose([transforms.Resize(image_size), transforms.ToTensor()]) # resize and convert to tensor
However I correct the input tensor values immediately after using transforms.ToTensor(), with:
tensor = Loader(image) * 255
I ran some tests to track the img value inside the feval function of both neural_style.lua, and my PyTorch code. It looks like Neural-Style has negative values while my PyTorch code doesn't, which could mean the "clamping" is related to how my PyTorch code treats negative and positive values.
Neural-Style:

PyTorch:

I don't see any clamping happening here, just image resize and conversion to Tensor (which does not change pixel values):
Loader = transforms.Compose([transforms.Resize(image_size), transforms.ToTensor()]) # resize and convert to tensor
However this line is suspect:
Normalize = transforms.Compose([transforms.Normalize(mean=[-103.939, -116.779, -123.68], std=[1,1,1]) ]) # Subtract BGR
This means that, in addition to subtracting the mean, the deviation of values is compressed which should not be done for the original VGG model.
BTW, it is not obvious what your curves mean. You say it is the image value, but an image is a 3D tensor, so what does the curve show.
BTW, I downloaded your gist and jcjohnson's VGG19 port, which you are also using at least judging from the default model name, but got an _pickle.UnpicklingError: unpickling stack underflow when the code was loading the model. Didn't have the time to investigate.
@htoyryla I haven't seen a pickle error in relation to the script before. I've been using the pip version of PyTorch via pip:
pip install http://download.pytorch.org/whl/cu90/torch-0.3.1-cp27-cp27mu-linux_x86_64.whl
pip install torchvision
If the issue was caused by the model issue with jcjohnson's VGG19 port, then this script will fix the issues in addition to downloading the models: https://gist.github.com/ProGamerGov/8fba74ed24062641bfa263954397c599
Thanks for this info... will try it. Now the problem is not in the model, however, because the model is not even getting unpickled. Looks very much like the file would be truncated... will try again tomorrow. Perhaps directly with this fix script.
BTW, it is not obvious what your curves mean. You say it is the image value, but an image is a 3D tensor, so what does the curve show.
Sorry, I should have labeled the graphs properly. The torch.sum() function was used on the 3D img tensors in order to turn them into a single value.
For example in Python:
print("img - feval: " + str(torch.sum(img.clone().data)))`
In Lua/Torch it looks like this:
a = "img - feval: "
a = a .. torch.sum(img)
print(a)
The x-axis is the number of iterations, and y-axis is the sum of the img tensor.
Edit:
However this line is suspect:
Normalize = transforms.Compose([transforms.Normalize(mean=[-103.939, -116.779, -123.68], std=[1,1,1]) ]) # Subtract BGR
This means that, in addition to subtracting the mean, the deviation of values is compressed which should not be done for the original VGG model.
I know that the Caffe VGG models didn't have and standard deviation pre-processing, but transforms.Normalize requires std values. However looking at how transforms.Normalize works, a value of 1 for the std seems like it work do nothing:
input[channel] = (input[channel] - mean[channel]) / std[channel]
Source: http://pytorch.org/docs/master/torchvision/transforms.html#transforms-on-torch-tensor
Second Edit:
Subtracting the mean pixel in neural_style.lua makes the torch.sum of img in the preprocess function, negative:
img:add(-1, mean_pixel)
But the values inside the tensor remain between -255 and 255.
Following after leongatys's PytorchNeuralStyleTransfer, I tried to use this to replicate Neural-Style's preprocessing:
Normalize = transforms.Compose([transforms.Normalize(mean=[-103.939, -116.779, -123.68], std=[1,1,1]) ]) # Subtract BGR
tensor = Normalize(tensor
But that results in in values of 0 to 255+, and not -255 to 255 like in neural_style.lua.
Also, this line in neural_style.lua, produces tensor values with decimals, while converting the [0-1] values inside the tensor, into [0-255] values:
img = img:index(1, perm):mul(256.0)
Multiplying by 255 in Pytorch does not produce any decimals, just [0-255] values:
tensor = tensor * 255
But multiplying by 256 does produce negative values like in neural_style.lua.
Third Edit:
I think I had my pre-processing and de-processing transforms.Normalize values mixed up. The output image results are looking a lot better now. The torch.sum values in the feval function now match neural_style.lua.
It also appears that there is an improvement now with the content/style weight issue. Changing the style/content weight now results in different outputs in the later iterations.
The torch.sum() function was used on the 3D img tensors in order to turn them into a single value.
OK. I usually use mean and std, or min and max, to monitor how the values in tensors behave.
Yes, I think I had the pytorch normalize transform mixed up, I was thinking that the std params specify the target std instead of the current std (to get a normalized std). Good you found a way forward, anyway.
Comparing my latest PyTorch code with neural_style.lua, shows that the same level of stylization is achieved, in both scripts when the same content and style weights are used:


- Neural-Style is on the left, and the PyTorch code is on the right.
The Neural-Style command used:
th neural_style.lua -image_size 512 -content_image examples/inputs/tubingen.jpg -style_image examples/inputs/starry_night_google.jpg -gpu 0 -content_layers relu4_2 -style_layers relu1_1,relu2_1,relu3_1,relu4_1,relu5_1 -save_iter 50 -print_iter 25 -content_weight 5 -style_weight 15000 -seed 876 -tv_weight 0 -init image
The PyTorch command used:
python sts2_4.py -image_size 384 -content_image examples/inputs/tubingen.jpg -style_image examples/inputs/starry_night_google.jpg -gpu 0 -content_layers relu4_2 -style_layers relu1_1,relu2_1,relu3_1,relu4_1,relu5_1 -save_iter 50 -print_iter 25 -content_weight 5 -style_weight 15000 -seed 876 -tv_weight 0 -init image
However the gradient normalization in the PyTorch code is not working, and the total variance denoising is working, but it's not the same as neural_style.lua's TV weight.
Here's the updated code: https://gist.github.com/ProGamerGov/89973941721107f0bf713edfcfb467cf
For the total variation denoising, the current implementation's results in some color related issues.
-tv_weight 0.1:


- Neural-Style's output is on the left, and the PyTorch code's output is on the right.
-tv_weight 1:


- Neural-Style's output is on the left, and the PyTorch code's output is on the right.
As for gradient normalization this is what is looks like in Neural-Style:
The control test is on the left, and the test with -normalize_gradients is on the right


This command was used to generate the above examples (with/without -normalize_gradients):
th neural_style.lua -image_size 512 -content_image examples/inputs/tubingen.jpg -style_image examples/inputs/starry_night_google.jpg -gpu 0 -content_layers relu4_2 -style_layers relu1_1,relu2_1,relu3_1,relu4_1,relu5_1 -save_iter 50 -print_iter 25 -content_weight 5 -style_weight 15000 -seed 876 -tv_weight 0 -init image
Thus far, our attempts at gradient normalization haven't been able to replicate the "color outside the lines" effect that Neural-Style's gradient normalization has. So I don't have anything to compare these Neural-Style results with yet.
I had a look at your tvloss. If the input is c x h x w which I think is correct, your matrix slices here look strange:
input = input.view(C, H, W) self.x_diff = input[1:,:,:] - input[:-1,:,:] self.y_diff = input[:,1:,:] - input[:,:-1,:]
I think the ones and minus ones should be in the h and w dimensions, so that one compares adjadent pixels. Now the x_diff measures how different the R, G and B values are from each other. I guess you have copied some python code where an image is stored as h x w x c.
I guess you have copied some python code where an image is stored as h x w x c.
This particular implementation had been used in many different PyTorch and Tensorflow projects, and it seems to be popular (I think someone even added it to Tensorflow in the form of tf.image.total_variation. I have also seen people posting really "smooth"/clean DeepDream images, which I assume are the result of this total variation denoising setup.
PyTorch doesn't support the negative indices at the moment, so I can't use anything like this (translated from neural_style.lua's TVLoss function):
input[:, [1,-2], [1,-2]]
This particular implementation had been used in many different PyTorch and Tensorflow projects, and it seems to be popular (I think someone even added it to Tensorflow in the form of tf.image.total_variation. I have also seen people posting really "smooth"/clean DeepDream images, which I assume are the result of this total variation denoising setup.
So what? Still, it does not work in your code and produces color changes. It is common in Python to store images as H x W x C. Tensorflow documentation, for instance, says:
If 3-D, the shape is [height, width, channels], and the Tensor represents one image. If 4-D, the shape is [batch_size, height, width, channels], and the Tensor represents batch_size images.
Your image is C x H x W so it is no wonder if something odd happens to color. Denoising should be done in the H and W dimensions. Think of it: there is a strong similarity between adjacent pixels, unless there is noise. But there is no dependence at all between the R, G and B channels of a pixel. A pixel which has R, G and B equal or close to equal is grey.
Like this, I think.
self.x_diff = input[:,1:,:] - input[:,:-1,:] self.y_diff = input[:,:,1:] - input[:,:,:-1]
That is, take two slices of the tensor, one pixel apart, and subtract them, you get a tensor containing the difference between adjacent pixels in x and y dimensions.
input[:, [1,-2], [1,-2]]
I think you should look into a tutorial how python indexing works. Looks like you are mixing up how indexing works in torch/lua and in python. Lua does not support using an index range inside an array, therefore torch has added an index operator to select an index range, for instance {2,4}. Python does support index ranges for lists, e.g. 1:3 and pytorch follows that. Remember also that lua indices start from 1, python indices from 0. Python indeed supports negative indices, for instance a[-1] is the last element of a and a[:-1] gives array a without the last element.
I've gotten multiple style images, style blend weights and printing layer specific loss values working now: https://gist.github.com/ProGamerGov/89973941721107f0bf713edfcfb467cf
Known issues:
-
Using
-init randomproduces a grey output image. But I think this might be because I am still using the PyTorch tutorial's way of producing a random image, and not Neural-Style's way of doing it. -
The pooling parameter doesn't reach the model class (probably an easy fix, but I haven't looked into it.). Using average pooling resulted in all black output images last time I tried it.
I've also not been able to get gradient normalization working, and I haven't even been able to achieve any sort of effect like Neural-Style's gradient normalization.
Works here now, also got the model sorted out. Only that there's a wrong indentation in one of your files.
With the defaults I get, after 200 iterations (looks good to me)

and at 1000 iterations

From the code I understand this should be using random init, yet I see no problem?
As to the gradient norm thing, I have no idea what kind of effect to expect. I've never really used it in lua torch either, as far as I remember.
I hadn't tested -init random since some of the major fixes, so I guess it was only broken because something else was broken. Average pooling also works now.
I've also converted the NIN ImageNet model to PyTorch (or at least I think that I converted it properly):

The code I used to convert the NIN model can be found here: https://gist.github.com/ProGamerGov/12766364202640e3f14e95316a4c926f
And I used this project's conversion tool: https://github.com/clcarwin/convert_torch_to_pytorch
I have fixed the pooling parameter issue, removed some useless/unneeded code, added the NIN model to the download_models.py script, and I have tried to clean up the code:
https://gist.github.com/ProGamerGov/89973941721107f0bf713edfcfb467cf
I've also gotten some better NIN model examples:
-tv_weight 0.0001 (left) versus -tv_weight 0 (right):


I currently don't have access to a computer with multiple GPUs, so I can't try and get the multi-GPU feature working.
Works here now, also got the model sorted out. Only that there's a wrong indentation in one of your files.
@htoyryla Does this issue still exist my updated code? And if the issue still exists, can you please show me where it is, as I don't get any error messages?
File "sts2_4.py", line 18, in <module>
from CVGG import vgg19, vgg16
File "/home/hannu/neural/pgg/CVGG.py", line 8
self.features = features
^
TabError: inconsistent use of tabs and spaces in indentation
You should check by downloading from github and testing with that.
@htoyryla I have been downloading and using the code I upload here, in order to make sure that it works. But for whatever reason, I wasn't getting an error for that single usage of tab.
So in Neural-Style, the gradient is run through all the lower loss modules, regardless of whether or not they are style or content modules? Your old comment seems to imply this.
Because I am wondering if this might be contributing to the difference between the output images that my code produces, and the output images that Neural-Style uses.
So in Neural-Style, the gradient is run through all the lower loss modules, regardless of whether or not they are style or content modules?
That is how gradient descent works. You evaluate loss at the output, and backprogate the gradient downwards through the whole model. In a sequential model, this is like going down a ladder, from a layer to the one below.
This is why the loss modules add the gradOutput (the gradient at its output, being the gradient of the nearest upper layer) to gradInput (its own contribution to the gradient): https://github.com/jcjohnson/neural-style/blob/master/neural_style.lua#L559
Note that also the other layers (conv, rely etc) contribute to the gradient.
The same happens in the pytorch version, there is no way the gradient from the loss modules could affect the image other that by descending through all modules down to the bottom where the image is.
Still, you might be right anyway. In original neural-style backwards is called once for the whole model; in the pytorch version once for each loss module. Now I have not looked into how the pytorch version accumulates the total gradient for the image. In neural-style it is clear, each loss module adds its contribution when the gradient passes through it on its way downwards.
So it might happen that the effect of some loss modules is added several times. Actually, I already wrote about this question in my comment you referred to. If you model is sequential, like a ladder, then calling backward on each loss module is really different from original neural-style. If my speculation about the pytorch approach is correct, that is.
Perhaps you should test calling backward only on the very highest loss module, only one, whether it is content or style, and look at the output then. You will not get loss values gathered from the modules, but look at what happens to the image.
I tried using a single backward() and compared that with the current backward() setup, and there was very little change.
Using this in the feval function while commenting out the content and tv loss parts:
i = 0
for mod in style_losses:
if i == 4:
loss = mod.backward()
styleLoss += loss
i+=1
Using if i == 0::

Using if i == 1: (left), and if i == 2: (right):


Using if i == 3: (left), and if i == 4: (right):


Just running backward on the content loss module (with the style and tv feval modules commented out):

-content_layers relu4_2 -style_layers relu1_1,relu2_1,relu3_1,relu4_1,relu5_1
python neural_style.py -seed 876 -content_image examples/inputs/tubingen.jpg -style_image examples/inputs/starry_night_google.jpg -image_size 384 -backend cudnn -gpu 0 -save_iter 500 -print_iter 25 -content_weight 10 -style_weight 500 -init image -tv_weight 0
The above parameters used with the default Neural-Style (left) and my unmodified PyTorch code (right):


Using -content_layers relu2_1,relu3_1,relu4_2 -style_layers relu1_1,relu2_1,relu3_1,relu4_1,relu5_1, and only doing backward() on a the desired style layer:
Using if i == 1: (left), and if i == 2: (right):


Using if i == 3: (left), and if i == 4: (right):


Really interesting. Calling mod.backward of style modules produces a style-transferred image with also content preserved. (That the content is preserved would imply that content loss modules get used, if you had used -init random, but if you used -init image, then that explains the content.)
Style change when you change i appears to imply that lower style layers do not contribute to the gradient as they would in a sequential structure like neural-style has.
Now, one should take a thorough look into how your model is really built and how the gradient is accumulated before it is applied to the image. Understanding that is essential. Would be extremely interesting to do but I have deadlines to meet.
Anyhow, based on these results, my gut feeling is that with this code of yours, one needs to call backward for each loss module to get the combined effect in like neural-style. If the results differ from neural-style, there is some other explanation to that.
I am also having issues recreating the results from Neural-Style's multires.sh example script:
The control test with Neural-Style is on the left, and the results of my PyTorch code are on the right:


I am not sure if there is an issue somewhere with my code, or if the parameters need to be changed in order to match Neural-Style's results. I have tried changing the parameters I use with my code, but I can't get anything like the results from Neural-Style.
The -init_image parameter also may not be working correctly? Because this was supposed to be step 2, but it doesn't look right (it actually became less "stylized" over time as the iterations progressed):

This is what step 2 looks like in Neural-Style:

Because the code already works well (minus a few things), perhaps it may be wise to publish it as a new Github project in order to attract more eyes to it (for solving the gradient related issues). I have all of the example outputs made, except for the multires script output image. I was thinking of calling it "neural-style-pt", but I was wondering what your thoughts were on the name?
I also rebuilt the modified version of Convis in PyTorch from one of our earlier discussions, to see if that showed any issues with the models. The results proved to be pretty much identical to the Lua version.
Because the code already works well (minus a few things), perhaps it may be wise to publish it as a new Github project in order to attract more eyes to it (for solving the gradient related issues). I have all of the example outputs made, except for the multires script output image. I was thinking of calling it "neural-style-pt", but I was wondering what your thoughts were on the name?
Sounds good to publish it. Name does not matter to me. It is your project, I have not contributed to the code, just offered some insight at some critical points.
So I noticed that I still had the content and style layers set to their pre-layer fix values, so I changed them to the defaults in Neural-Style. Now it seems like the -init_image issue is fixed, and the Multires script is working like Neural-Style.
Here's step 3 with the correct content and style layers:

I don't have access to the computing power required for using L-BFGS at output image sizes of 2048, and 3620. But I can get to 2289x1205 with Adam.
PyTorch's transforms.Resize() resizes images in a way that makes the smallest side is equal to the specified image size. Neural-Style uses the Image library with the scale function, which resizes images in a way that makes the largest side equal to the specified image size. transforms.Resize() can also take two size values, and will resize images exactly to those specified dimensions.
I've tried to calculate the same sizes that the image library will, with this:
from PIL import Image
# Get the bilinear resizing values for height and width
def BilinearResize(image, image_size):
image = Image.open(image).convert('RGB')
width, height = image.size
changePercent = 0
if height > width:
if height == image_size:
changePercent = 1
else:
changePercent = image_size / float(height)
elif height < width:
if width == image_size:
changePercent = 1
else:
changePercent = image_size / float(width)
elif height == width:
changePercent = image_size / float(width)
NewHeight = height * changePercent
NewWidth = width * changePercent
return (int(NewHeight), int(NewWidth))
Does the above code look right for replicating the Image library's scale function?
It may well be right, but too complex for me.
Something like
mult = float(image_size) / max(image.size)
That is, we take the larger side and find out how much it needs to change. Note that mult gets smaller when the new image has to be smaller, so it should be correct.
And then I was thinking of simply:
newsize = mult * image.size
but python does not allow this, so one could now:
newsize = (int(mult * image.size[0]), int(mult*image.size[1]))
but this is more python-like and clearer once you learn to read it:
newsize = tuple([int(mult*x) for x in image.size])
That is, we make a list by looping through image.size, multiplying by mult and taking an integer of the result, and then convert it to a tuple.
I would also recommend using less confusing names. Your function gives a size, it does not resize anything. Your changePercent is a ratio or a multiplier, not a percentage.
I had guess that my code for finding the resize dimensions, was horribly inefficient, but I wasn't quiet sure how to condense it because I forgot about Python's max function. Though there is one minor issue with your code: PIL.Image.size outputs WxH, while transforms.Resize takes HxW.
Using image.height and image.width seems to let me easily correct for this:
if type(image_size) is not tuple:
image_size = tuple([int((float(image_size) / max(image.size))*x) for x in (image.height, image.width)])
https://gist.github.com/ProGamerGov/89973941721107f0bf713edfcfb467cf#file-neural_style-py-L75-L76
PIL.Image.size outputs WxH, while transforms.Resize takes HxW.
Good point. Exactly the kind of thing to be alert for when mixing different libraries and approaches.
So I tried to clean up the code, improve readability and remove unnecessary things. If the new code setup is better than the current one, I'll replace the current code with it. The new code more closely matches Neural-Style's setup, with a similar main function, and a similar code/function order.
The new code: https://gist.github.com/ProGamerGov/4fbb4a8340ae654a3ae460ccddb7757c
The current code: https://gist.github.com/ProGamerGov/89973941721107f0bf713edfcfb467cf
Is the new code setup better for Python and for readability? Or I am I going in the wrong direction?
Doing a code review is a bit too much, I'm busy with other things. Just publish I would say. I think the value of your code is in duplicating the original neural-style functionality very closely. Other people may then comment if they think it can be improved.
I made some GPU usage and speed comparisons, using a Tesla K80:
| Project | CUDA/cuDNN | Basic Command | Optimized Command |
|---|---|---|---|
| Neural-Style | CUDA 9.0, cuDNN v7 | 3742MiB |
1763MiB |
| Neural-Style-PT | CUDA 9.0, cuDNN v7 | 2204MiB |
1532MiB |
| Neural-Style | CUDA 8.0, cuDNN v5 | 2940MiB |
1095MiB |
| Neural-Style-PT | CUDA 8.0, cuDNN v5 | 2203MiB |
1531MiB |
The basic command:
th neural_style.lua -gpu 0
python neural_style.py -gpu 0
The optimized command:
th neural_style.lua -gpu 0 -backend cudnn -cudnn_autotune -optimizer adam
python neural_style.py -gpu 0 -backend cudnn -cudnn_autotune -optimizer adam
Speed tests using time.time() (Python 2.7.12) and torch.Timer() (Lua/Torch7):
Neural-Style with CUDA 8.0, and cuDNN v5:
-backend nn -optimizer lbfgs: 137.36946702003 seconds-backend nn -optimizer adam: 124.8309879303 seconds-backend cudnn -optimizer lbfgs: 132.90000200272 seconds-backend cudnn -optimizer adam: 120.14643216133 seconds-backend cudnn -cudnn_autotune -optimizer lbfgs: 135.52075195312 seconds-backend cudnn -cudnn_autotune -optimizer adam: 120.78998494148 seconds
Neural-Style-PT with CUDA 8.0, and cuDNN v5:
-backend nn -optimizer lbfgs: 388.481142044 seconds-backend nn -optimizer adam: 375.758505106 seconds-backend cudnn -optimizer lbfgs: 389.669136047 seconds-backend cudnn -optimizer adam: 375.155197144 seconds-backend cudnn -cudnn_autotune -optimizer lbfgs: 307.17031908 seconds-backend cudnn -cudnn_autotune -optimizer adam: 294.428309917 seconds
Neural-Style with CUDA 9.0, and cuDNN v7:
-backend nn -optimizer lbfgs: 128.88787198067 seconds-backend nn -optimizer adam: 115.48763203621 seconds-backend cudnn -optimizer lbfgs: 171.14045906067 seconds-backend cudnn -optimizer adam: 119.24845004082 seconds-backend cudnn -cudnn_autotune -optimizer lbfgs: 115.76553916931 seconds-backend cudnn -cudnn_autotune -optimizer adam: 103.37868523598 seconds
Neural-Style-PT with CUDA 9.0, and cuDNN v7:
-backend nn -optimizer lbfgs: 408.812216043 seconds-backend nn -optimizer adam: 393.100239038 seconds-backend cudnn -optimizer lbfgs: 405.673749924 seconds-backend cudnn -optimizer adam: 393.661305189 seconds-backend cudnn -cudnn_autotune -optimizer lbfgs: 325.299500942 seconds-backend cudnn -cudnn_autotune -optimizer adam: 313.671709061 seconds
th neural_style.lua -gpu 0 -num_iterations 500
python neural_style.py -gpu 0 -num_iterations 500
Using (CUDA 9.0, cuDNN v7):
th neural_style.lua -gpu 0 -backend cudnn -cudnn_autotune -num_iterations 500 -optimizer adam
python neural_style.py -gpu 0 -backend cudnn -cudnn_autotune -num_iterations 500 -optimizer adam
The average time it takes from the start of running the script, to reach the feval function:
-
Neural-Style: 16.042811870575 seconds
-
Neural-Style-PT: 13.4434280396 seconds
The average time it takes for one iteration:
-
Neural-Style: 0.18768 seconds
-
Neural-Style-PT: 0.639904 seconds
-
Neural-Style-PT (single
backward()): 0.301149 seconds
It seems that the almost 3x increase in time with Neural-Style-PT, is the result of slightly slower iterations (0.452224 seconds). Only using backward() once each iteration, lowers the difference to 0.113469 seconds, and basically doubles the speed.
When using a single backward(), I don't think that I need to use retain_graph=True, and that frees up a tiny bit of memory, and speeds things up ever so slightly to 0.300517 seconds per iteration.
But if I only do a single backward(), I can't get the layer and module specific loss values for printing.
Using these parameters:
python neural_style.py -gpu 0 -backend cudnn -cudnn_autotune -num_iterations 500 -optimizer adam
I think that I can get the correct loss values while preserving the increased speed that using a single backward() allows for, with this:
def feval():
num_calls[0] += 1
optimizer.zero_grad()
net(img)
totalLoss = 0
contentLossList, styleLossList = [], []
for mod in content_losses:
totalLoss += mod.loss
for mod in style_losses:
totalLoss += mod.loss
if params.tv_weight > 0:
for mod in tv_losses:
totalLoss += mod.loss
totalLoss.backward(retain_graph=True)
for mod in content_losses:
contentLossList.append(mod.loss.data[0])
for mod in style_losses:
styleLossList.append(mod.loss.data[0])
maybe_save(num_calls[0])
maybe_print(num_calls[0], contentLossList, styleLossList)
return totalLoss
optimizer.step(feval)
With the above code in the feval function, I can get an iteration speed of: 0.307481
If I remove the retain_graph=True, the iteration speed goes down to: 0.295994 seconds, but the printed loss values aren't correct.
With the above code, I am still about 0.1 seconds slower than Neural-Style.
This is the current feval code I am using (without the above modifications): https://gist.github.com/ProGamerGov/4fbb4a8340ae654a3ae460ccddb7757c#file-neural_style-py-L222-L248
I wonder whether the difference is due to autograd, as opposed to manually coded gradient calculation? Anyway, the strengths of pytorch are in research and development, not in deployment.
The PyTorch site says that PyTorch is still in "early-release Beta", and the latest pip version is v0.3.1. I'm pretty sure that Torch7 has been in development for a longer period of time, and isn't still in an early access beta. I would expect/hope that subsequent PyTorch updates to improve the speed and memory usage. Hopefully then that final 0.1 second difference would disappear.
As for now, I think that the results from using my above modifications to the feval function, are probably the fastest that I can get iterations at the moment. For the double set of "for mod in" loops, I wonder if I can make that better looking.
Nevertheless, pytorch is much more flexible and that may well impose a performance penalty. We will see.
There is also 0.4 version out there somewhere. I needed it for trying out some new software from github, and it took some effort to find how to get it.
I think that you can get version 0.4 by installing directly from the source: https://github.com/pytorch/pytorch#from-source
It also occurs to me that I have Torch7 installed from the source, while I installed PyTorch via pip. So maybe installing from the source would make PyTorch faster?
So my PyTorch code currently will do an extra 20 iterations past the -num_iterations value for L-BFGS, and a single extra iteration for Adam.
I think that I should be able to fix this by replacing params.num_iterations in the code below, with a value which is determined while setting up the optimizer:
num_calls = [0]
while num_calls[0] <= loopVal:
def feval():
For -optimizer lbfgs, loopVal would be equal to 1.
For -optimizer adam, loopVal would be equal to params.num_iterations - 1.
This seems to work, but during earlier testing (not with the current code), I did experience times where iterations would suddenly stop with no warning at a seemingly random iteration number with L-BFGS. That might have just been caused by errors in my old code, but I am wondering if I should be worried about this for the latest code?
Was this an issue with Neural-Style? And was this the fix?
tolX=-1,
tolFun=-1,
Edit:
It would seem that this is an issue with my code as well.
Using these parameters for L-BFGS seems to fix the issue:
tolerance_change = -1, tolerance_grad = -1
Here are the stats for using CUDA 9.0, cuDNN v7 with the faster feval code:
Neural-Style-PT (one backward()) with CUDA 9.0, cuDNN v7, and PyTorch v0.3.1:
-backend nn -optimizer lbfgs: 199.663722038 seconds-backend nn -optimizer adam: 184.649815083 seconds-backend cudnn -optimizer lbfgs: 196.787035942 seconds-backend cudnn -optimizer adam: 184.82763505 seconds-backend cudnn -cudnn_autotune -optimizer lbfgs: 173.454026937 seconds-backend cudnn -cudnn_autotune -optimizer adam: 160.867530107 seconds
Neural-Style-PT (one backward()) with CUDA 9.0, cuDNN v7, and PyTorch v0.4 (Installed from source):
-backend nn -optimizer lbfgs: 193.417675972 seconds-backend nn -optimizer adam: 176.872451067 seconds-backend cudnn -optimizer lbfgs: 193.381013155 seconds-backend cudnn -optimizer adam: 178.107871056 seconds-backend cudnn -cudnn_autotune -optimizer lbfgs: 152.441287041 seconds-backend cudnn -cudnn_autotune -optimizer adam: 134.995646 seconds
th neural_style.lua -gpu 0 -num_iterations 500
python neural_style.py -gpu 0 -num_iterations 500
GPU usage seems to have slightly increased, when testing the following command:
python neural_style.py -gpu 0 -backend cudnn -optimizer adam
Going from 1217MiB with PyTorch v0.3.1, to 1235MiB with PyTorch v0.4 (installed from source).
PyTorch v0.4 (installed from source) seems to shave off about 0.05 seconds per iteration, which brings the difference with Neural-Style down to about 0.06 seconds. For -backend nn -optimizer lbfgs, it only shaves off about 0.012 seconds.
My code is now fully compatible with both Python 2, and Python 3. It is also now fully compatible with Pytorch v0.4, in addition to v0.3.1. I have also replaced almost all of the loop counters with enumerate, and I have removed a lot of unnecessary lines of code. My "loadcaffe" script will also now print the same things that the Lua loadcaffe package does, when loading a model.
https://gist.github.com/ProGamerGov/4fbb4a8340ae654a3ae460ccddb7757c
Interestingly, the sum of all the content and style loss values, is not equal to the loss variable.
If I add up the loss values by doing:
def maybe_print(t, loss):
if params.print_iter > 0 and t % params.print_iter == 0:
print("Iteration: " + str(t) + " / "+ str(params.num_iterations))
totalLoss = 0
for i, loss_module in enumerate(content_losses):
print(" Content " + str(i+1) + " loss: " + str(float(loss_module.loss.data)))
totalLoss += float(loss_module.loss.data)
for i, loss_module in enumerate(style_losses):
print(" Style " + str(i+1) + " loss: " + str(float(loss_module.loss.data)))
totalLoss += float(loss_module.loss.data)
print(" C/S Total loss: " + str(float(totalLoss)))
print(" Total loss: " + str(float(loss.data)))
The variable used in print(" Total loss: " + str(float(loss.data))), comes directly from the feval function, like Neural-Style.
I get two slightly different values:
C/S Total loss: 8088995.81122
Total loss: 8088996.0
C/S Total loss: 3512584.05008
Total loss: 3512584.25
C/S Total loss: 1081956.37198
Total loss: 1081956.375
C/S Total loss: 1028641.08926
Total loss: 1028641.0625
With a -tv_weight of 0, I would think that both of these values should be the exact same. The difference between these two loss totals gradually becomes less and less as more iterations pass.
When I conduct the same experiment with neural_style.lua, both loss totals are equal to each other.
Edit:
I have tested PyTorch v0.3.1, and v0.4, but the issue remains. Using multiple backward()s, and changing any of the parameters, also doesn't seem to resolve the issue.
On the subject of total variance denoising, I think this code replicates the behavior of Neural-Style's Backward TVLoss function:
self.gradInput = input.clone().zero_()
self.x_diff = input[:,:,:-1,:-1] - input[:,:,:-1,1:]
self.y_diff = input[:,:,:-1,:-1] - input[:,:,1:,:-1]
self.gradInput[:,:,:-1,:-1] = self.x_diff + self.y_diff
self.gradInput[:,:,:-1,1:] = self.gradInput[:,:,:-1,1:] - self.x_diff
self.gradInput[:,:,1:,:-1] = self.gradInput[:,:,1:,:-1] - self.y_diff
However, I can't seem to make it to work properly with the rest of my code.
As for gradient normalization, I think that normalizing the loss variable is a dead end.
I created these two functions to replicate the terminal outputs for loadcaffe, and printing a sequential net in Torch7:
# Print like Lua/loadcaffe
def print_loadcaffe(cnn, layerList):
c = 0
for l in list(cnn):
if "Conv2d" in str(l):
in_c, out_c, ks = str(l.in_channels), str(l.out_channels), str(l.kernel_size)
print(layerList['C'][c] +": " + (out_c + " " + in_c + " " + ks).replace(")",'').replace("(",'').replace(",",'') )
c+=1
if c == len(layerList['C']):
break
# Print like Lua/Torch7
def print_torch(net):
simplelist = ""
for i, layer in enumerate(net, 1):
simplelist = simplelist + "(" + str(i) + ") -> "
print("nn.Sequential ( \n [input -> " + simplelist + "output]")
def strip(x):
return str(x).replace(", ",',').replace("(",'').replace(")",'') + ", "
for i, l in enumerate(net):
is_2d = True if "2d" in str(l) else False
is_conv = True if "Conv2d" in str(l) else False
if is_2d:
ks, st, pd = strip(l.kernel_size), strip(l.stride), strip(l.padding)
if is_conv:
in_c, out_c = str(l.in_channels), str(l.out_channels)
print(" (" + str(i+1) + "): " + "nn.Conv2d(" + in_c + " -> " + out_c + ", " + (ks).replace(",",'x', 1) + st + pd.replace(", ",')'))
else:
print(" (" + str(i+1) + "): " + "nn." + str(l).split("(", 1)[0] + "(" + ((ks).replace(",",'x' + ks, 1) + st.replace(" ",' ') + st.replace(", ",')')).replace(", ",',') )
else:
print(" (" + str(i+1) + "): " + "nn." + str(l).split("(", 1)[0])
print(")")
I've tried to simplify them as much as possible, but it may be possible to reduce the amount of code even more.
I'm not sure if this is an issue, but while using L-BFGS, the memory usage seems to increase over time (at about 10-15 iterations between each increase):
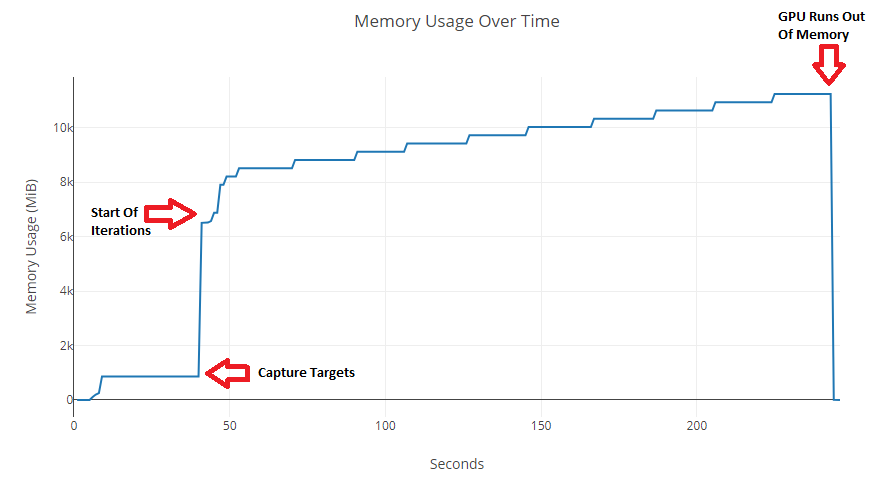
Using -lbfgs_num_correction 95 just barely worked for what would only use up 8-9 GB of memory with Neural-Style. The L-BFGS algorithm appears like it is a bit different in PyTorch, when compared to Torch7's implementation of L-BFGS. But unless Neural-Style uses the line search function, then I can't see why they behave differently.
This is the current project code: https://gist.github.com/ProGamerGov/4fbb4a8340ae654a3ae460ccddb7757c
I rebuilt the style image directory/image sorting function (which let you specify one or more directories, along with separate images, for the -style image parameter):
style_image_input = params.style_image.split(',')
style_image_list, ext = [], [".jpg",".png"]
for image in style_image_input:
if os.path.isdir(image):
images = (image + "/" + file for file in os.listdir(image)
if os.path.splitext(file)[1].lower() in ext)
style_image_list.extend(images)
else:
style_image_list.append(image)
@htoyryla I was also able to recreate your neural_bestchannels.lua and neural-equalchannels.lua scripts: https://gist.github.com/ProGamerGov/45400c5d0d58ddb0d400a8d5ea8fb4b0
In addition to the scripts, I've updated my port of your Convis project, with the latest PyTorch code from Neural-Style-PT: https://github.com/ProGamerGov/pytorch-convis
So I discovered that this in-place operation:
self.G.div_(input.nelement())
Uses a lot more memory compared to it's non in-place counterpart:
self.G = self.G.div(input.nelement())
This makes sense according the PyTorch Docs. In-place operations are less efficient than their non in-place counterparts.
I also noticed that I don't need every layer in the network to have requires_grad be equal to True:
# Freeze the network in order to prevent
# unnecessary gradient calculations
for param in net.parameters():
param.requires_grad = False
Running the above code just after setting the content and style loss modules to loss mode, saves a bunch of memory as well. There is no change in the output image from doing this.
# Freeze the network in order to prevent
# unnecessary gradient calculations
for param in net.parameters():
param.requires_grad = False
Oh yes, in neural-style we are not training the network, don't want the weights to change, so they don't need gradients.
In neural_style.lua, I don't think that these two lines of code in the StyleLoss function are needed:
if self.blend_weight == nil then
self.target:resizeAs(self.G):copy(self.G)
These lines here always make sure that style_blend_weights has a value:
-- Handle style blending weights for multiple style inputs
local style_blend_weights = nil
if params.style_blend_weights == 'nil' then
-- Style blending not specified, so use equal weighting
style_blend_weights = {}
for i = 1, #style_image_list do
table.insert(style_blend_weights, 1.0)
end
Also in my testing, I discovered that the last part of the content and style loss backward functions seems to never be used:
else
self.gradInput = gradOutput
end
else
self.gradInput:resizeAs(gradOutput):copy(gradOutput)
end
The content and style loss functions are never run backwards when their mode is not set to loss.
I assume that these unused lines of code are from an earlier version of Neural-Style, and that they were never removed after they were no longer needed?
The content and style loss functions are never run backwards when their mode is not set to loss.
I assume that these unused lines of code are from an earlier version of Neural-Style, and that they were never removed after they were no longer needed?
I guess you are right.
On the other hand, there is value in keeping modules like these general purpose, which here means that a loss module simply passes the gradient from output to input unchanged if mode is not set to loss. Makes sense to me.
@htoyryla Are these lines in the forward content and style loss modules really needed?
self.output = input
return self.output
https://github.com/jcjohnson/neural-style/blob/master/neural_style.lua#L468-L469 https://github.com/jcjohnson/neural-style/blob/master/neural_style.lua#L546-L547
self.output just seems to just end up occupying GPU memory without serving any obvious purpose.
And in my code's gram matrix, I think that self.output is also not actually needed, and just wastes GPU memory as well:
def forward(self, input):
B, C, H, W = input.size()
x_flat = input.view(C, H * W)
self.output = torch.mm(x_flat, x_flat.t())
return self.output
Instead of using self.output, I can just do this:
return torch.mm(x_flat, x_flat.t())
I don't see any obvious downsides to these changes.
Are these lines in the forward content and style loss modules really needed?
self.output = input return self.output
It looks like torch nn development guide specifies that an nn module shall have an output variable in which the output is stored during forward(). See http://torch.ch/docs/developer-docs.html
It may be that here there is no problem if that is not done, but in general, doing a backward() on the loss module would not work correctly unless output has been stored.
I removed self.output and the resulting output image was the exact same as with self.output. I also can't find any mention of anything similar to self.output being required in PyTorch. So I assume that while Torch7 required self.output, PyTorch does not require it.
Using a Tesla K80, I these are the results I get from the default tests:
| Command | Initial Memory Spike | Memory Stabilizes At | Time |
|---|---|---|---|
| LBFGS nn | No Spike | 3744 MiB | 117 seconds |
| LBFGS cudnn | No Spike | 1259-1260 MiB | 124 seconds |
| LBFGS cudnn autotune | 2520-9473 MiB | 1207 MiB | 109 seconds |
| Adam nn | No Spike | 3744 MiB | 100 seconds |
| Adam cudnn | No Spike | 1007-1008 MiB | 107 seconds |
| Adam cudnn autotune | 2520-9266 MiB | 791 MiB | 91 seconds |
And for comparison, here are the results for Neural-Style:
| Command | Initial Memory Spike | Memory Stabilizes At | Time |
|---|---|---|---|
| LBFGS nn | No Spike | 3753 MiB | 132 seconds |
| LBFGS cudnn | No Spike | 1755 MiB | 136 seconds |
| LBFGS cudnn autotune | 10257 MiB | 1774 MiB | 119 seconds |
| Adam nn | No Spike | 3753 MiB | 120 seconds |
| Adam cudnn | No Spike | 1755 MiB | 123 seconds |
| Adam cudnn autotune | 2880 MiB | 1774 MiB | 106 seconds |
Even with self.output my code was already faster and more efficient than Neural-Style, according to my memory usage and speed tests.
So I assume that while Torch7 required self.output, PyTorch does not require it.
The pytorch nn documentation confirms this: "State is no longer held in the module, but in the network graph". The diagrams in https://pytorch.org/tutorials/beginner/former_torchies/nn_tutorial.html make it clear that output and gradInput are stored in the graph instead of modules as in Torch.
I have 2 new sets of GPU benchmarks:
GRID K520:
| Command | Time |
|---|---|
| LBFGS nn | 236 seconds |
| LBFGS cudnn | 226 seconds |
| LBFGS cudnn autotune | 226 seconds |
| Adam nn | 209 seconds |
| Adam cudnn | 200 seconds |
| Adam cudnn autotune | 200 seconds |
-
The GRID K520 is used by AWS's G2 (g2.2xlarge, g2.8xlarge) instances.
-
Cuda 9.1 was used.
GTX 1080:
| Command | Time |
|---|---|
| LBFGS nn | 56 seconds |
| LBFGS cudnn | 38 seconds |
| LBFGS cudnn autotune | 40 seconds |
| Adam nn | 40 seconds |
| Adam cudnn | 23 seconds |
| Adam cudnn autotune | 24 seconds |
- Cuda 8.0 was used along with PyTorch v0.4.
My old GTX 660 graphics card died, which forced me to get a new one. Now I can finally do tests involving CUDA/cuDNN on my own computer.
The GRID K520 tests used PyTorch installed from source. I wasn't able to get PyTorch to install from source on my PC, so I just used the Python 2.7 pip PyTorch install. I suspect that with a newer version of Cuda/cuDNN and PyTorch installed from source, my 1080 should be able to beat Neural-Style's speed test results for the Pascal Titan X.
The code used to conduct the speed tests/benchmarks, can be found here: https://gist.github.com/ProGamerGov/e5e94f8735c1f7991a3e4ad2289e0d01
The latest version of Neural-Style-PT can be found here: https://gist.github.com/ProGamerGov/089a082c2a000d1e1cc034fc75ff5931
I recreated the color-independent style transfer function, using only Python's PIL/Pillow library:
# Combine the Y channel of the generated image and the UV/CbCr channels of the
# content image to perform color-independent style transfer.
def original_colors(content, generated):
content_channels = list(content.convert('YCbCr').split())
generated_channels = list(generated.convert('YCbCr').split())
content_channels[0] = generated_channels[0]
return Image.merge('YCbCr', content_channels).convert('RGB')
I have published the Neural-Style-PT code as it's own project now:
https://github.com/ProGamerGov/neural-style-pt
-
It's been tested with both Python 2 and 3.
-
PyTorch v0.4 or later is required.
I was not able to get gradient normalization or multi-gpu support working at this time, but every other feature from Neural-Style has been implemented. There is also a different total variance denoising function, as I could not get Neural-Style's total variance denoising setup working in PyTorch.
Neural-Style-PT is faster, and more memory efficient than Neural-Style. The PyTorch implementation of the Adam optimizer uses better parameters than it's Torch7 counterpart, and the L-BFGS optimizer is significantly more memory efficient than it's Torch7 counterpart. The output quality of Neural-Style-PT is the same as Neural-Style.
Thank you to everyone who helped me with this project!