mdt_policy
 mdt_policy copied to clipboard
mdt_policy copied to clipboard
[RSS 2024] Code for "Multimodal Diffusion Transformer: Learning Versatile Behavior from Multimodal Goals" for CALVIN experiments with pre-trained weights
Multimodal Diffusion Transformer: Learning Versatile Behavior from Multimodal Goals
Moritz Reuss1, Ömer Erdinç Yağmurlu, Fabian Wenzel, Rudolf Lioutikov1
1Intuitive Robots Lab, Karlsruhe Institute of Technology
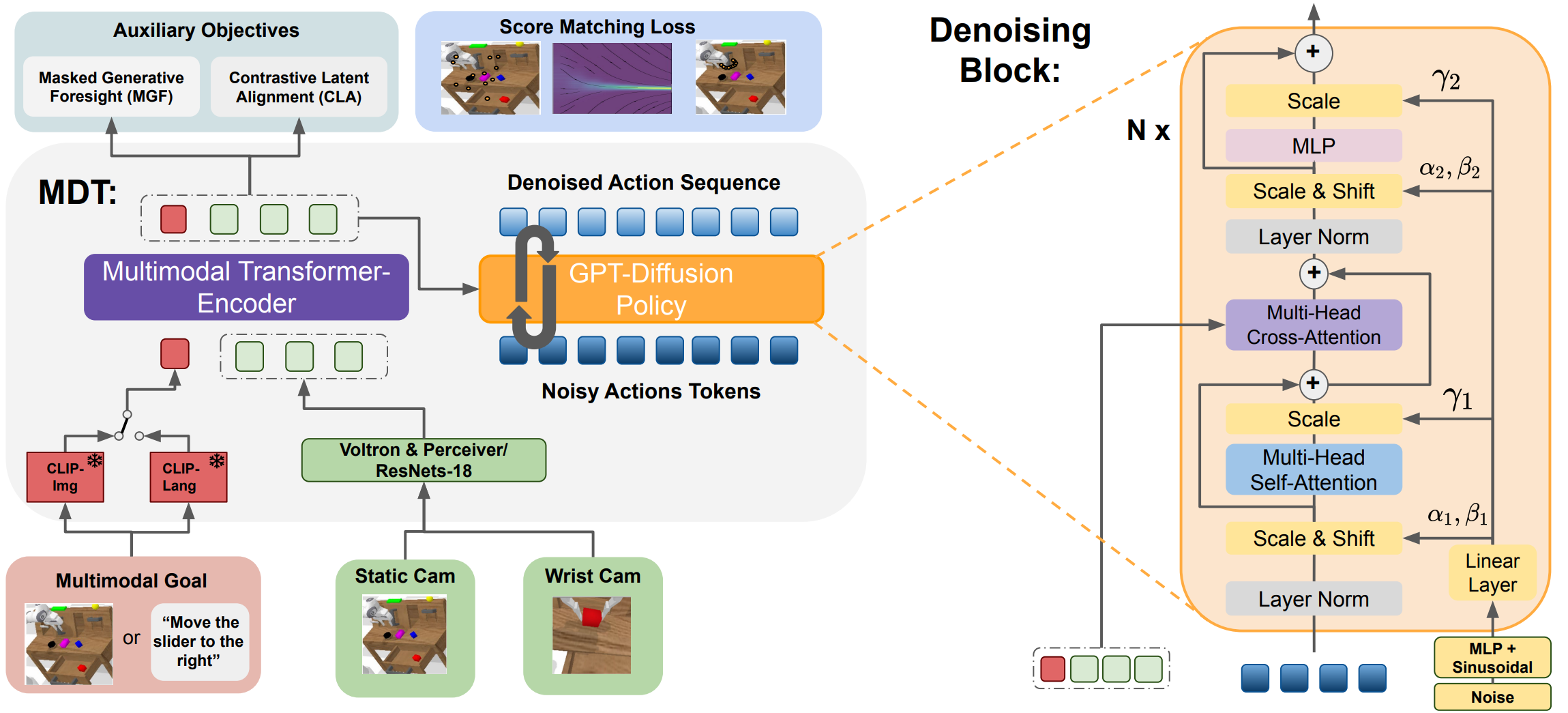
This is the official code repository for the paper Multimodal Diffusion Transformer: Learning Versatile Behavior from Multimodal Goals.
Pre-trained models are available here.
Performance
Results on the CALVIN benchmark (1000 chains):
| Train | Method | 1 | 2 | 3 | 4 | 5 | Avg. Len. |
|---|---|---|---|---|---|---|---|
| D | HULC | 82.5% | 66.8% | 52.0% | 39.3% | 27.5% | 2.68±(0.11) |
| LAD | 88.7% | 69.9% | 54.5% | 42.7% | 32.2% | 2.88±(0.19) | |
| Distill-D | 86.7% | 71.5% | 57.0% | 45.9% | 35.6% | 2.97±(0.04) | |
| MT-ACT | 88.4% | 72.2% | 57.2% | 44.9% | 35.3% | 2.98±(0.05) | |
| MDT (ours) | 93.3% | 82.4% | 71.5% | 60.9% | 51.1% | 3.59±(0.07) | |
| MDT-V (ours) | 93.9% | 83.8% | 73.5% | 63.9% | 54.9% | 3.70±(0.03)* | |
| ABCD | HULC | 88.9% | 73.3% | 58.7% | 47.5% | 38.3% | 3.06±(0.07) |
| Distill-D | 86.3% | 72.7% | 60.1% | 51.2% | 41.7% | 3.16±(0.06) | |
| MT-ACT | 87.1% | 69.8% | 53.4% | 40.0% | 29.3% | 2.80±(0.03) | |
| RoboFlamingo | 96.4% | 89.6% | 82.4% | 74.0% | 66.0% | 4.09±(0.00) | |
| MDT (ours) | 97.8% | 93.8% | 88.8% | 83.1% | 77.0% | 4.41±(0.03) | |
| MDT-V (ours) | 99.1% | 96.8% | 92.8% | 88.5% | 83.1% | 4.60±(0.05)* |
*: 3.72±(0.05) (D) and 4.52±(0.02) (ABCD) in the paper. Performance is higher than reported given some fixes in the camera-ready code version.
Installation
To begin, clone the repository locally:
git clone --recurse-submodules [email protected]:intuitive-robots/mdt_policy.git
export MDT_ROOT=$(pwd)/mdt_policy
Install the requirements: (Note we provided a changed verison of pyhash, given numerous problems when installing it manually)
cd $MDT_ROOT
conda create -n mdt_env python=3.8
conda activate mdt_env
cd calvin_env/tacto
pip install -e .
cd ..
pip install -e .
cd ..
pip install setuptools==57.5.0
cd pyhash-0.9.3
python setup.py build
python setup.py install
cd ..
Next we can install the rest of the missing packages:
pip install -r requirements.txt
Evaluation
Step 1 - Download CALVIN Datasets
If you want to train on the CALVIN dataset, choose a split with:
cd $MDT_ROOT/dataset
sh download_data.sh D | ABCD
(Optional) Preprocessing with CALVIN
Since MDT uses action chunking, it needs to load multiple (~10) episode_{}.npz files for each inference. In combination with batching, this results in a large disk bandwidth needed for each iteration (usually ~2000MB/iteration).
This has the potential of significantly reducing your GPU utilization rate during training depending on your hardware.
Therefore, you can use the script extract_by_key.py to extract the data into a single file, avoiding opening too many episode files when using the CALVIN dataset.
Usage example:
python preprocess/extract_by_key.py -i /YOUR/PATH/TO/CALVIN/ \
--in_task all
Params:
Run this command to see more detailed information:
python preprocess/extract_by_key.py -h
Important params:
--in_root:/YOUR/PATH/TO/CALVIN/, e.g/data3/geyuan/datasets/CALVIN/--extract_key: A key ofdict(episode_xxx.npz), default is 'rel_actions', the saved file name depends on this (i.eep_{extract_key}.npy)
Optional params:
--in_task: default is 'all', meaning all task folders (e.gtask_ABCD_D/) of CALVIN--in_split: default is 'all', meaning bothtraining/andvalidation/--out_dir: optional, default is 'None', and will be converted to{in_root}/{in_task}/{in_split}/extracted/--force: whether to overwrite existing extracted data
Thanks to @ygtxr1997 for debugging the GPU utilization and providing a merge request.
Step 2 - Download Pre-trained Models
| Name | Split | 1 | 2 | 3 | 4 | 5 | Avg. Len. | Model | Seed | eval: sigma-min |
|---|---|---|---|---|---|---|---|---|---|---|
| mdtv-1-abcd | ABCD -> D | 99.6% | 97.5% | 94.0% | 90.2% | 84.7% | 4.66 | MDT-V | 142 | 1.000 |
| mdtv-2-abcd | ABCD -> D | 99.0% | 96.2% | 92.4% | 88.3% | 82.5% | 4.58 | MDT-V | 242 | 1.000 |
| mdtv-3-abcd | ABCD -> D | 98.9% | 96.7% | 92.1% | 87.1% | 82.1% | 4.57 | MDT-V | 42 | 1.000 |
| mdtv-1-d | D -> D | 93.8% | 83.4% | 72.6% | 63.2% | 54.4% | 3.67 | MDT-V | 142 | 0.001 |
| mdtv-2-d | D -> D | 94.0% | 84.0% | 73.3% | 63.5% | 54.2% | 3.69 | MDT-V | 242 | 0.001 |
| mdtv-3-d | D -> D | 93.9% | 84.0% | 74.6% | 65.0% | 56.3% | 3.74 | MDT-V | 42 | 1.000 |
You can find all of the aforementioned models under here.
Step 3 - Run
Adjust conf/mdt_evaluate.conf according to the model you downloaded. Important keys are:
voltron_cache: set a rw path in order to avoid downloading Voltron from huggingface each run.num_videos:nfirst rollouts of the model will be recorded as a gif.dataset_pathandtrain_folder: location of the downloaded files.sigma_min: use the values in the table for best results with a given model.
Then run:
python mdt/evaluation/mdt_evaluate.py
Training
To train the MDT model with the maximum amount of available GPUS, run:
python mdt/training.py
For replication of the originial training results I recommend to use 4 GPUs with a batch_size of 128 and train them for 30 (20) epochs for ABCD (D only). You can find the exact configuration used for each of our pretrained models in .hydra/config.yaml under the respective model's folder.
Acknowledgements
This work is only possible because of the code from the following open-source projects and datasets:
CALVIN
Original: https://github.com/mees/calvin License: MIT
BESO
Original: https://github.com/intuitive-robots/beso License: MIT
Voltron
Original: https://github.com/siddk/voltron-robotics License: MIT
OpenAI CLIP
Original: https://github.com/openai/CLIP License: MIT
HULC
Original: https://github.com/lukashermann/hulc License: MIT
Citation
If you found the code usefull, please cite our work:
@inproceedings{
reuss2024multimodal,
title={Multimodal Diffusion Transformer: Learning Versatile Behavior from Multimodal Goals},
author={Moritz Reuss and {\"O}mer Erdin{\c{c}} Ya{\u{g}}murlu and Fabian Wenzel and Rudolf Lioutikov},
booktitle={Robotics: Science and Systems},
year={2024}
}
Metadata
Owner
Metadata
[RSS 2024] Code for "Multimodal Diffusion Transformer: Learning Versatile Behavior from Multimodal Goals" for CALVIN experiments with pre-trained weights