fastllm
 fastllm copied to clipboard
fastllm copied to clipboard
Published
20 hours ago •
 ztxz16
ztxz16
batch_response() 耗时和prompt list长度成线性关系
st=time.time()
prompts=[text]
config = pyfastllm.GenerationConfig()
res=model.batch_response(prompts, None, config)
one_time=time.time()-st
print(one_time)
multi_st=time.time()
prompts=[text,text,text,text]
config = pyfastllm.GenerationConfig()
res=model.batch_response(prompts, None, config)
multi_time=time.time()-multi_st
print(multi_time)
multi_time 差不多是one_time的四倍?请教一下是有参数配置的不合理导致的嘛
看了一下源码,Forwardbatch里面是for循环调用的Forward?这样是不是没有任何加速效果
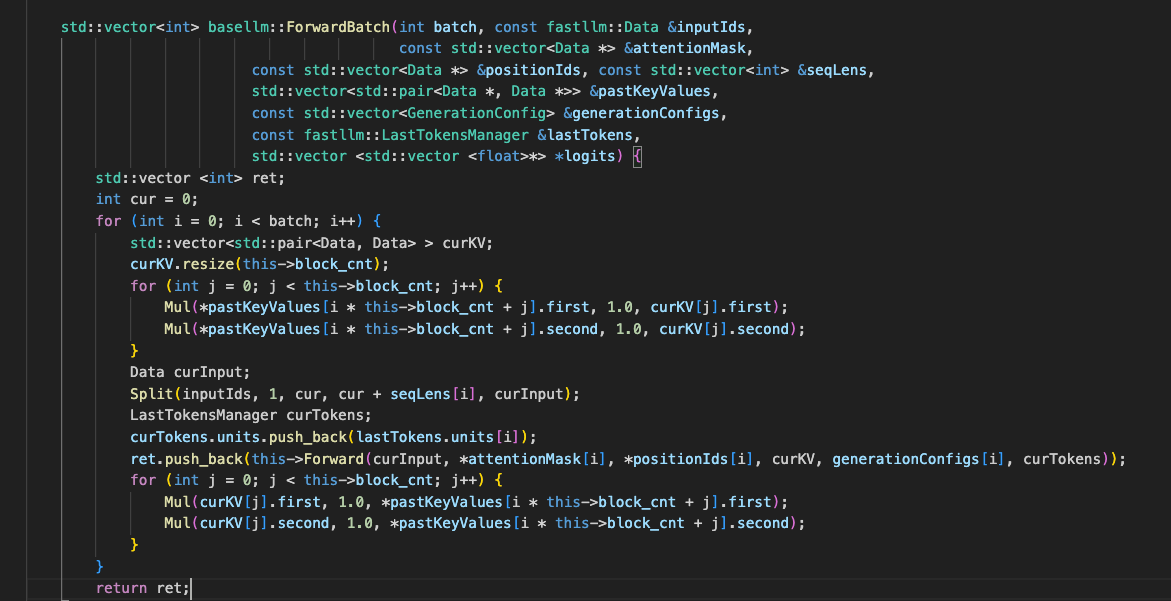
这个是基类的函数,具体的模型(chatglm.cpp, llama.cpp这些)里面的batch不是一个一个跑的
@ztxz16 哦哦,看到了,但是耗时线性增长会啥原因呀,chatglm2模型,直接用demo里面的web_api 中的/api/batch_chat接口测试也是和list长度呈线性关系
@Lzhang-hub hello 我看llm.py里面没有定义batch_response()这个函数呀 能问下这个函数在哪里吗?
@ztxz16 能帮忙指导一下如何使用batch_response()吗?
这种方式测试的是prefill阶段,建议测试decode阶段。
@wildkid1024 我理解这种直接采用web api部署的测试方式应该是更符合实际的模型部署场景,现在我们有一个batch推理的生产需求,只测试decode阶段是不是不能满足实际推理场景呀