BELLE
 BELLE copied to clipboard
BELLE copied to clipboard
Published
20 hours ago •
 LianjiaTech
LianjiaTech
为什么BELLE经过GPTQ量化(8bit/4bit)后,模型的推理速度变慢了很多呢
BELLE-7B(bloom)量化后,推理速度显著降低。 BELLE-7B(LLaMA)量化后,推理速度也下降了一部分。
代码:
import time
import torch
import torch.nn as nn
from gptq import *
from modelutils import *
from quant import *
from transformers import AutoTokenizer
from random import choice
from statistics import mean
import numpy as np
DEV = torch.device('cuda:0')
def get_bloom(model):
import torch
def skip(*args, **kwargs):
pass
torch.nn.init.kaiming_uniform_ = skip
torch.nn.init.uniform_ = skip
torch.nn.init.normal_ = skip
from transformers import BloomForCausalLM
model = BloomForCausalLM.from_pretrained(model, torch_dtype='auto')
model.seqlen = 2048
return model
def load_quant(model, checkpoint, wbits, groupsize):
from transformers import BloomConfig, BloomForCausalLM
config = BloomConfig.from_pretrained(model)
def noop(*args, **kwargs):
pass
torch.nn.init.kaiming_uniform_ = noop
torch.nn.init.uniform_ = noop
torch.nn.init.normal_ = noop
torch.set_default_dtype(torch.half)
transformers.modeling_utils._init_weights = False
torch.set_default_dtype(torch.half)
model = BloomForCausalLM(config)
torch.set_default_dtype(torch.float)
model = model.eval()
layers = find_layers(model)
for name in ['lm_head']:
if name in layers:
del layers[name]
make_quant(model, layers, wbits, groupsize)
print('Loading model ...')
if checkpoint.endswith('.safetensors'):
from safetensors.torch import load_file as safe_load
model.load_state_dict(safe_load(checkpoint))
else:
model.load_state_dict(torch.load(checkpoint))
model.seqlen = 2048
print('Done.')
return model
inputs = ["使用python写一个二分查找的代码",
"今天天气怎么样,把这句话翻译成英语",
"怎么让自己精力充沛,列5点建议",
"小明的爸爸有三个孩子,老大叫王一,老二叫王二,老三叫什么?",
"明天就假期结束了,有点抗拒上班,应该什么办?",
"父母都姓李,取一些男宝宝和女宝宝的名字",
"推荐几本金庸的武侠小说",
"写一篇英文散文诗,主题是春雨,想象自己是春雨,和英国古代诗人莎士比亚交流"]
if __name__ == '__main__':
import argparse
from datautils import *
parser = argparse.ArgumentParser()
parser.add_argument(
'model', type=str,
help='llama model to load'
)
parser.add_argument(
'--wbits', type=int, default=16, choices=[2, 3, 4, 8, 16],
help='#bits to use for quantization; use 16 for evaluating base model.'
)
parser.add_argument(
'--groupsize', type=int, default=-1,
help='Groupsize to use for quantization; default uses full row.'
)
parser.add_argument(
'--load', type=str, default='',
help='Load quantized model.'
)
parser.add_argument(
'--text', type=str,
help='hello'
)
parser.add_argument(
'--min_length', type=int, default=10,
help='The minimum length of the sequence to be generated.'
)
parser.add_argument(
'--max_length', type=int, default=1024,
help='The maximum length of the sequence to be generated.'
)
parser.add_argument(
'--top_p', type=float , default=0.95,
help='If set to float < 1, only the smallest set of most probable tokens with probabilities that add up to top_p or higher are kept for generation.'
)
parser.add_argument(
'--temperature', type=float, default=0.8,
help='The value used to module the next token probabilities.'
)
args = parser.parse_args()
if type(args.load) is not str:
args.load = args.load.as_posix()
if args.load:
model = load_quant(args.model, args.load, args.wbits, args.groupsize)
else:
model = get_bloom(args.model)
model.eval()
model.to(DEV)
tokenizer = AutoTokenizer.from_pretrained(args.model)
"""
print("Human:")
line = input()
while line:
inputs = 'Human: ' + line.strip() + '\n\nAssistant:'
input_ids = tokenizer.encode(inputs, return_tensors="pt").to(DEV)
with torch.no_grad():
generated_ids = model.generate(
input_ids,
do_sample=True,
min_length=args.min_length,
max_length=args.max_length,
top_p=args.top_p,
temperature=args.temperature,
)
print("Assistant:\n")
print(tokenizer.decode([el.item() for el in generated_ids[0]]))
print("\n-------------------------------\n")
line = input()
"""
time_list = []
for i in range(1000):
start = time.perf_counter()
input_str = str(choice(inputs))
input_str = 'Human: ' + input_str.strip() + '\n\nAssistant:'
print(input_str)
input_ids = tokenizer(input_str, return_tensors="pt").input_ids.to(DEV)
with torch.no_grad():
outputs = model.generate(
input_ids,
do_sample=True,
min_length=args.min_length,
max_length=args.max_length,
top_p=args.top_p,
temperature=args.temperature,
)
print(tokenizer.decode([el.item() for el in outputs[0]]))
#with torch.no_grad():
# outputs = model.generate(input_ids, max_new_tokens=500, do_sample = True, top_k = 30, top_p = 0.85, temperature = 0.5, repetition_penalty=1., eos_token_id=2, bos_token_id=1, pad_token_id=0)
#rets = tokenizer.batch_decode(outputs, skip_special_tokens=True, clean_up_tokenization_spaces=False)
#print("\n" + rets[0].strip().replace(input_str, ""))
end = time.perf_counter()
runTime = end - start
runTime_ms = runTime * 1000
print("运行时间:", round(runTime_ms, 2), "毫秒")
time_list.append(round(runTime_ms, 2))
print("\n-------------------------------\n")
print(time_list)
result = mean(time_list)
print("均值:", round(result, 2))
print("最大值:", round(max(time_list), 2))
print("最小值:", round(min(time_list), 2))
print("TP50:", np.percentile(np.array(time_list), 50))
print("TP90:", np.percentile(np.array(time_list), 90))
print("TP99:", np.percentile(np.array(time_list), 99))
运行命令:
CUDA_VISIBLE_DEVICES=1 python bloom_inference_benchmark.py /data/nfs/guodong.li/pretrain/belle/belle-bloom-7b --wbits 8 --groupsize 128 --load /data/nfs/guodong.li/pretrain/belle/belle-bloom-gptq-7b/bloom7b-2m-8bit-128g.pt
统计结果:
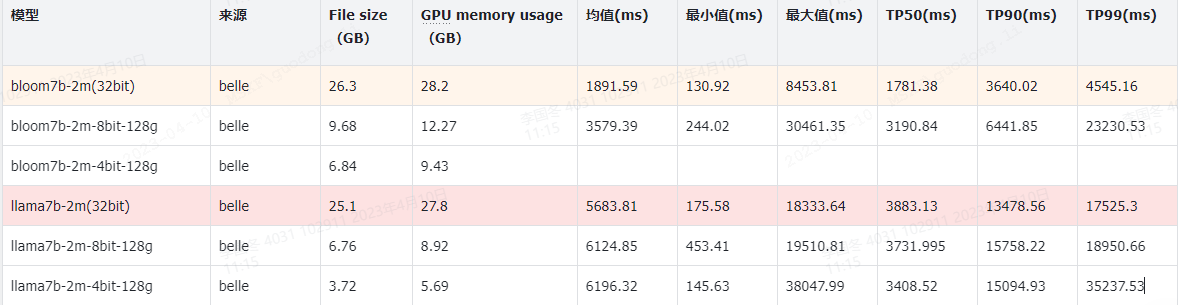
请问量化后速度变慢的原因有找到么,我这边对比量化前后的速度,同等环境下量化后的速度反而更慢一些了
同样发现了,不知道原因
可能是量化后插入的节点没法调用cuda的kernel导致的吧
BELLE-7B(bloom)量化后,推理速度显著降低。 BELLE-7B(LLaMA)量化后,推理速度也下降了一部分。
代码:
import time import torch import torch.nn as nn from gptq import * from modelutils import * from quant import * from transformers import AutoTokenizer from random import choice from statistics import mean import numpy as np DEV = torch.device('cuda:0') def get_bloom(model): import torch def skip(*args, **kwargs): pass torch.nn.init.kaiming_uniform_ = skip torch.nn.init.uniform_ = skip torch.nn.init.normal_ = skip from transformers import BloomForCausalLM model = BloomForCausalLM.from_pretrained(model, torch_dtype='auto') model.seqlen = 2048 return model def load_quant(model, checkpoint, wbits, groupsize): from transformers import BloomConfig, BloomForCausalLM config = BloomConfig.from_pretrained(model) def noop(*args, **kwargs): pass torch.nn.init.kaiming_uniform_ = noop torch.nn.init.uniform_ = noop torch.nn.init.normal_ = noop torch.set_default_dtype(torch.half) transformers.modeling_utils._init_weights = False torch.set_default_dtype(torch.half) model = BloomForCausalLM(config) torch.set_default_dtype(torch.float) model = model.eval() layers = find_layers(model) for name in ['lm_head']: if name in layers: del layers[name] make_quant(model, layers, wbits, groupsize) print('Loading model ...') if checkpoint.endswith('.safetensors'): from safetensors.torch import load_file as safe_load model.load_state_dict(safe_load(checkpoint)) else: model.load_state_dict(torch.load(checkpoint)) model.seqlen = 2048 print('Done.') return model inputs = ["使用python写一个二分查找的代码", "今天天气怎么样,把这句话翻译成英语", "怎么让自己精力充沛,列5点建议", "小明的爸爸有三个孩子,老大叫王一,老二叫王二,老三叫什么?", "明天就假期结束了,有点抗拒上班,应该什么办?", "父母都姓李,取一些男宝宝和女宝宝的名字", "推荐几本金庸的武侠小说", "写一篇英文散文诗,主题是春雨,想象自己是春雨,和英国古代诗人莎士比亚交流"] if __name__ == '__main__': import argparse from datautils import * parser = argparse.ArgumentParser() parser.add_argument( 'model', type=str, help='llama model to load' ) parser.add_argument( '--wbits', type=int, default=16, choices=[2, 3, 4, 8, 16], help='#bits to use for quantization; use 16 for evaluating base model.' ) parser.add_argument( '--groupsize', type=int, default=-1, help='Groupsize to use for quantization; default uses full row.' ) parser.add_argument( '--load', type=str, default='', help='Load quantized model.' ) parser.add_argument( '--text', type=str, help='hello' ) parser.add_argument( '--min_length', type=int, default=10, help='The minimum length of the sequence to be generated.' ) parser.add_argument( '--max_length', type=int, default=1024, help='The maximum length of the sequence to be generated.' ) parser.add_argument( '--top_p', type=float , default=0.95, help='If set to float < 1, only the smallest set of most probable tokens with probabilities that add up to top_p or higher are kept for generation.' ) parser.add_argument( '--temperature', type=float, default=0.8, help='The value used to module the next token probabilities.' ) args = parser.parse_args() if type(args.load) is not str: args.load = args.load.as_posix() if args.load: model = load_quant(args.model, args.load, args.wbits, args.groupsize) else: model = get_bloom(args.model) model.eval() model.to(DEV) tokenizer = AutoTokenizer.from_pretrained(args.model) """ print("Human:") line = input() while line: inputs = 'Human: ' + line.strip() + '\n\nAssistant:' input_ids = tokenizer.encode(inputs, return_tensors="pt").to(DEV) with torch.no_grad(): generated_ids = model.generate( input_ids, do_sample=True, min_length=args.min_length, max_length=args.max_length, top_p=args.top_p, temperature=args.temperature, ) print("Assistant:\n") print(tokenizer.decode([el.item() for el in generated_ids[0]])) print("\n-------------------------------\n") line = input() """ time_list = [] for i in range(1000): start = time.perf_counter() input_str = str(choice(inputs)) input_str = 'Human: ' + input_str.strip() + '\n\nAssistant:' print(input_str) input_ids = tokenizer(input_str, return_tensors="pt").input_ids.to(DEV) with torch.no_grad(): outputs = model.generate( input_ids, do_sample=True, min_length=args.min_length, max_length=args.max_length, top_p=args.top_p, temperature=args.temperature, ) print(tokenizer.decode([el.item() for el in outputs[0]])) #with torch.no_grad(): # outputs = model.generate(input_ids, max_new_tokens=500, do_sample = True, top_k = 30, top_p = 0.85, temperature = 0.5, repetition_penalty=1., eos_token_id=2, bos_token_id=1, pad_token_id=0) #rets = tokenizer.batch_decode(outputs, skip_special_tokens=True, clean_up_tokenization_spaces=False) #print("\n" + rets[0].strip().replace(input_str, "")) end = time.perf_counter() runTime = end - start runTime_ms = runTime * 1000 print("运行时间:", round(runTime_ms, 2), "毫秒") time_list.append(round(runTime_ms, 2)) print("\n-------------------------------\n") print(time_list) result = mean(time_list) print("均值:", round(result, 2)) print("最大值:", round(max(time_list), 2)) print("最小值:", round(min(time_list), 2)) print("TP50:", np.percentile(np.array(time_list), 50)) print("TP90:", np.percentile(np.array(time_list), 90)) print("TP99:", np.percentile(np.array(time_list), 99))运行命令:
CUDA_VISIBLE_DEVICES=1 python bloom_inference_benchmark.py /data/nfs/guodong.li/pretrain/belle/belle-bloom-7b --wbits 8 --groupsize 128 --load /data/nfs/guodong.li/pretrain/belle/belle-bloom-gptq-7b/bloom7b-2m-8bit-128g.pt统计结果:
是V100的架构吗?还是用的A100这种amphere架构?V100的好像架构不太支持,这个量化方案源自https://github.com/IST-DASLab/gptq,本质上作者手写了一些cuda 算子,用来支持低bit数据运算的。 https://github.com/LianjiaTech/BELLE/issues/406