pytorch-image-models
 pytorch-image-models copied to clipboard
pytorch-image-models copied to clipboard
hack ln implementation in convnext
See https://github.com/pytorch/pytorch/issues/71465 Slightly changes LayerNorm2d implementation,
- currently when ln2d is called on a contiguous tensor, it accidentally turns most of the network into channels last mode, line 114 undoes that. With that change, eager benchmark numbers in contiguous format on A100 are 573 img/s (
python benchmark.py --bench train --img-size 224 -b 64 --precision float16 --model convnext_base). Even though eager ln implementation would copy inputs to be contiguous (and back) it's still faster than alternative decomposition
Benchmarking in float16 precision. NCHW layout. torchscript disabled
Model convnext_base created, param count: 88591464
Running train benchmark on convnext_base for 40 steps w/ input size (3, 224, 224) and batch size 64.
Train [8/40]. 573.06 samples/sec. 111.680 ms/step.
Train [16/40]. 573.13 samples/sec. 111.668 ms/step.
Train [24/40]. 573.16 samples/sec. 111.662 ms/step.
Train [32/40]. 573.16 samples/sec. 111.662 ms/step.
Train [40/40]. 573.16 samples/sec. 111.663 ms/step.
- Where permute - ln - permute really improves things is channels last format (where permutations are free, and no
.contiguouscalls are needed), lines 115-121 enable that. The eager numbers are 619 img/s, the difference with channels-first is 8% give or take
Benchmarking in float16 precision. NHWC layout. torchscript disabled
Model convnext_base created, param count: 88591464
Running train benchmark on convnext_base for 40 steps w/ input size (3, 224, 224) and batch size 64.
Train [8/40]. 621.58 samples/sec. 102.964 ms/step.
Train [16/40]. 621.60 samples/sec. 102.961 ms/step.
Train [24/40]. 621.57 samples/sec. 102.965 ms/step.
Train [32/40]. 621.56 samples/sec. 102.968 ms/step.
Train [40/40]. 621.56 samples/sec. 102.967 ms/step.
- NVFuser + AOT autograd further improve this to 642 img/s (
python benchmark.py --bench train --img-size 224 -b 64 --precision float16 --model convnext_base --aot-autograd --fuser nvfuser --channels-last) - Finally, ln kernels in the core are not optimized for small normalization dimension encountered here (128-512), so tricking nvfuser to codegen normalization kernels (
* 1.) further improves perf to 667 img/s, at the cost of slight eager pessimization (it's 619 with this pointless multiplication)
So in this case channels last is clearly faster, and nominally doesn't require a new LayerNorm2d op in the core, because existing LayerNorm already performs the necessary computation. Although core could definitely be improved to handle smaller normalization dimensions, future hear is codegening the performant kernels, which nvfuser is doing, with some massaging which we should make easier in the future. Given this, @rwightman is it still high priority to add LayerNorm2d to core? In case of channels-last it would still be doing exactly what's done here and call LayerNorm underneath, so it would be limited by how optimized (or not) existing kernels are. Contiguous would improve by having dedicated kernels, but contiguous is slower to begin with. cc @csarofeen, @chillee, there are cases where single-op ln fusion is beneficial, so maybe aot should do that? (I think there also are cases where single-op ln is slightly faster in core, so it's not a clear cut decision, would be nice if it were).
@ngimel thanks for demonstrating this... it works, but like my prev impl, it is a hack. I actually just pulled my iscontiguous version out. It was causing too many problems, and like your new version, it slows things down on older pytorch versions (that I still need to support) and even slows down eager mode a bit in some cases. Also, thanks to torchsript limitations, I can't script the memory_format arg, I had an ugly workaround in mine, but with your impl checking both formats I don't know how it'd be possible to torchscript a model using it.
So I'm sticking with just F.layer_norm(x.permute(0, 2, 3, 1), self.normalized_shape, self.weight, self.bias, self.eps).permute(0, 3, 1, 2) for now and hoping for an efficient, native way to tackle this at some point.
Also, if the torch API is changed args or layers are added, it's usually pretty easy to check if an arg exists or a new layer/fn exists and use it if present. For hacks like this though, that have very lumpy performance across older PyTorch versions (and sometimes weird issues with older hardware), it can be very challenging to determine what is appropriate to use in what instance (ie I've found out the hard way it's safer just to use permute(), layer_norm(), permute() than try to use these hacks that can demonstrate performance is being left on the table, but worsen many scenarios....
The existing implementation (F.layer_norm(x.permute(0, 2, 3, 1), self.normalized_shape, self.weight, self.bias, self.eps).permute(0, 3, 1, 2)) accidentally puts the rest of the model in channels last format, which is bad for fp32/older arches, creates unfair channels-last/non-channels-last comparisons for fp16/newer arches, and also has the potential to tank the perf of model architectures that have both LayerNorm2d and grouped convolutions (or other layers that are known bad in channels last) - grouped convolutions are bad in channels last in many cases, and LayerNorm2d would force model to channels-last regardless of command-line arguments. This should be fixed IMO.
I understand that my impl is not scriptable due to memory format arg, but, well, there are ugly workarounds, and also script shouldn't be the way to speed-up models going forward, aot_autograd is increasingly becoming that thing.
We can add a not-very-performant LayerNorm2d that would hide implementation details, but going forward the way to get performance will be using codegen (and nvfuser already demonstrates that it can generate pretty good kernels), and not lots of precompiled kernels in the core that cover all the parameter space.
@ngimel a lot of people still use scripting for serving / export, not just performance. 'aot' vs 'torchcsript' on 1.12 is interesting, they are still quite different in some cases in terms of what the end result is performance-wise. And while forward is often a win, backward is frequently worse than eager.
I'll hack around with your ideas a bit more and see if there is a compromise. Given that codegen is not trivial to use at this point, is not a default, is not somethign most people aware of, and does not result in constinent improvements (especially for training) across a broad set of models, I'd still favour an impl that is best in the default scenario (most of the time). Also, the codegen, or the code needed for the codegen to work can't get in the way of efficient model export, etc.
cc @csarofeen for regressions in backward, my understanding was that (at least for not-channels-last) aot is a win.
@rwightman I agree with your points, and btw if TorchScript is important for users, we should make them fix is_contiguous with memory format arg, because it can be frequently encountered in the actual scripts.
We are working to make codegen more usable, so it can be relied upon for performance.
Re: ease-of-use, is there anything we could do to make aot experience better?
I will add though, per the original torch issue w/ LN + axis... regardless of performance, not having a native norm layer that covers this use case (C-dim), without needing a custom layer, seems like an API gap. It's becoming more popular and it's 'native' by default in TF / JAX
cc @csarofeen for regressions in backward, my understanding was that (at least for not-channels-last) aot is a win.
I haven't seen significant regressions in backwards except in channels last BatchNorm, but in that case forward also suffers. @rwightman do you have any specific model we could take a look at, or is it just the channels last perf we're still struggling with. We're still targeting BN channels last perf by 1.13 in codegen. One thing we've played around with is the idea to codegen more directly within eager mode in some cases, but we've been prioritizing the new codegen stack (i.e. with Dynamo/FuncTorch/AOTAutograd).
@csarofeen keep in mind, I'm likely working with something a bit older than you, I was doing some testing on 1.12 release (cuda 11.3) via torchscript and aot-autograd. If you're working with newer nightlies, etc, I'm behind. A number of models were looking slower for backwards, I hope to run a big set of them soon to generate some comparative outputs...
We explicitly tested on 1.12 release, CC @ptrblck and @kevinstephano in case we were testing something slightly different. Definitely keep us posted, we're highly motivated to get our codegen in the best shape for you. If we need something targeted to work better with something a bit more dated, we might be able to figure something out as well.
@ngimel @csarofeen I ran a whole lot of BM runs on both 3090 and v100. As you can see, it's messy, I feel really messy without a clear cut win (or lose) across all scenarios. https://gist.github.com/rwightman/8b2c72d3e02147f4be75bb8165a588a7
The best performance is with torchscript (this is all 1.12 so NVF by default) and the simple permute method. The _c variants with 1x1 convs enabled for the mlp blocks is actually more representative of some other models I'm working with (where there are larger sequence of 2D NCHW ops (kxk stride convs or avgpool), etc mixed in with the need for a LN over channels.
Note the _c gets obliterated with @ngimel additions on V100 for some reason. The hacks often end up with an entry in the slowest for most of the model sizes. I think you can see why I decided to go back the the basic permute, it seems the safest and more often not the worst.
I weight not worsening pure eager performance pretty highly. I also would rather not need to need to use torchscript or aot for good performance (there are usually situations where it's trouble, large scale distributed libraries, other use cases). So I feel quite strongly that having an efficient torch layer (with a sensible name or axis api) that allows normalizating over C-dim (or allows arbitrary axis selection) would be far better than trying to navigate a maze of hacks and codegen quirks.
We explicitly tested on 1.12 release, CC @ptrblck and @kevinstephano in case we were testing something slightly different. Definitely keep us posted, we're highly motivated to get our codegen in the best shape for you. If we need something targeted to work better with something a bit more dated, we might be able to figure something out as well.
@csarofeen On this one, for the convnext, there is no clear trend relating to aot being slower than eager, with the exception of the 'base' reason (not clear why), most of them are slightly faster in train for aot, with quite a bit of noise due to the different LN impl.
One family of models that always seems to suffer in aot mode are vit models (and related). See https://gist.github.com/rwightman/6c37e408192f2a94d29023099445e13f ... both inference and train are worse for aot, and train is pretty much equal for torchscript (w/ nvf).
For cnn and cnn-attn hybrids it's more variable. aot seems to be a win for inference most of the time, torchscript almost always, but train has random exceptions where aot is slower (and also torchscript, but more rare), or just doesn't run. One other factor that may be contributing to the 'slower' is that aot is often causing higher memory consumption, so sometimes driving the batch size down in the auto-retry (at lower batch size).
There should probably be another location for 'nvfuser' + timm concerns, but will put this observation here for now
A number of torchscript + nvfuser failures are due to handling inplace activations. A number of models have inplace=True as default for activations, they're positioned such that they aren't a problem in eager (other buffers in the way), and weren't an issue for older torchscript backends, BUT with NVF as the torchscript backend, it appears to be optimizing such that the inplace ops violate grad rules a view of a leaf Variable that requires grad is being used in an in-place operation.
BUT with NVF as the torchscript backend, it appears to be optimizing such that the inplace ops violate grad rules
a view of a leaf Variable that requires grad is being used in an in-place operation.
Hmmm. that's surprising... nvfuser really are only applying optimization passes within autodiff region and shouldn't be causing any autograd errors. Maybe we introduced new aliases which violates the schema?! That sounds surprising, as we usually go in the other direction (making copies other than aliasing).
Would still like to take a look at that and appreciate if you can point me to the model/script that repros the error.
Let me open a new issue to review all ts/aot problems in 1.12 Edit: https://github.com/rwightman/pytorch-image-models/discussions/1350
@ngimel @csarofeen I spent a bit more time hacking around with this, as I keep getting frustrated by the lack of performance of non BN layers w/ PyTorch + GPU...
I ran some tests on a few familiar nets with PT XLA on TPU-v4. There things are more or less as expected, if I swap out the original nn.BatchNorm2d in say a ResNet or other well know archs with a custom '2D' C-dim LayerNorm or a GroupNorm implemented as individual ops, they're all comparable. Somewhere in the range of a 1% or two faster, to 10% slower depending on the shapes of the feature maps / channels down the net.
Now contrast that to using PyTorch on a GPU. Moving away from nn.BatchNorm2d is almost always a world of ouch.
Switching to nn.GroupNorm(groups=32), for channels last inference throughput from 3500 -> 1100, train from 1200 -> 440. Contiguous, 2950 -> 1400, train from 920 -> 510. I'm well aware that BN is not comparable to GN or LN in terms of inference, but I wouldn't expect this big of a hit even for the inference numbers, and certainly not the difference we see here in train.
In the NCHW LayerNorm hacking I haven't found a good option with or without codegen. Without any codegen (and using permute impl since it's most consistent w/o codegen), a ResNet again, with channels last 3500 -> 1500, train 1200 -> 520. For contiguous 3000 -> 1470, train 920 -> 505. So comparable to builtin GroupNorm. With or w/o codegen the memory use for LN is higher and we have to drop batch sizes down for training.
Using codegen (norm layer only) for the LN I can get inference into 1900 range with the ResNet, but train throughput drops down to 400-300 :(
With Natalia's codegen hack and full model aot, we can get the resnet to 2700 im/sec inference and 640 train in channels_last. That's something, but non CL is still quite slow. But then, that's not apples to apples. If we compare the native BN model with full model codegen ... 5000 im/sec inf, 1200 train for aot, for torchscript 4300 inf, 1000 train (an instance where torchscript slows train, although known for CL?).
BatchNorm has many downsides, and I'm seeing more and more image models in the research space move away from it. But the state of PyTorch on GPU for as long as I can rember, there is no way of using alternate norm layers without a significant penalty. I don't believe this should be the case, as the differences in operations and flops between this norm layers isn't THAT significant relative to the other operations in the models, in some cases (for train at least), they should be less.
Codegen is improving, but it's still a long way from closing the gap (especially when you compare custom norm with model-level codegen to BN with codegen). I've been trying to train more non BN models (GN, 1-group GN, NCHW LN, EvoNorm, etc) and have ended up doing most of these non-BN experiments TPU w/ PT XLA because it's just too slow otherwise.
If it makes sense, can post this in https://github.com/pytorch/pytorch/issues/71465 ... the norm concerns due extend beyond just this one LN case though, as shown GN also seems much slower than it should be. And ops like EvoNorm, and other weight-standardization techniques, etc could benefit from a set of fast norm kernels that allowed arbitrary reduction vs affine axis.
Thanks for the data, Ross! I'm really surprised that channels-last LN is so slow - after all, it's just calling existing layer norm kernels directly, and it shouldn't be using more memory because it doesn't need copies internally to call those kernels. One hypothesis I have is that existing ln kernels do best for 1024+ features, whereas many layers in Resnet (and other image networks) are smaller than that, but even then I'd expect smaller difference, especially for inference, and I'd expect codegen to fully recover the difference. I'll take a look at what's going on (and @csarofeen I'd appreciate if someone on NVFuser team took a look at those case also). Now, what are realistic ways forward? Norms (especially norms with arbitrary dimensions for parameters and normalizations) are pretty finicky, and writing kernels that would be good for wide parameter ranges is hard/requires a lot of kernels to handle different parameters, see that existing ln kernel in core that does pretty good on language models with 1024+ features, but falls on its face in image models with 128, and that's even before we start thinking about normalizations in the different dimensions (like GN, 1-group GN), or different kinds of norms, like RMS norm. XLA is solving this problem with codegen, and I was hoping that pytorch would have a more usable codegen state too, but unfortunately that hasn't happened yet. So, short-ish term we can add mediocre-perf LayerNorm2d and somewhat improve its perf for smaller number of features, but a sustainable solution for this problem requires robust codegen, there's no way around it that I can see.
I did a sweep of LayerNorm FWD and BWD on the sizes I generally use for my "TIMM micro benchmarks": Product of: N [8, 16, 32, 64, 128, 256] C [24, 40, 48, 56, 72, 152, 184, 200, 368] H==W [7, 14, 28, 56, 112] and product of : N [128, 256, 512, 1024, 2048] C [24, 40, 48, 56, 72, 152] H==W [7, 14, 28, 56]
For simple testing I just did a 2D tensor, as contiguous NHWC shouldn't be any different (we can try to validate this from python). I believe what's going on (please correct me if I'm wrong), is we're just normalizing across C or the innermost dimension.
Sweeping these cases I get plots of just LN and LN BWD of:
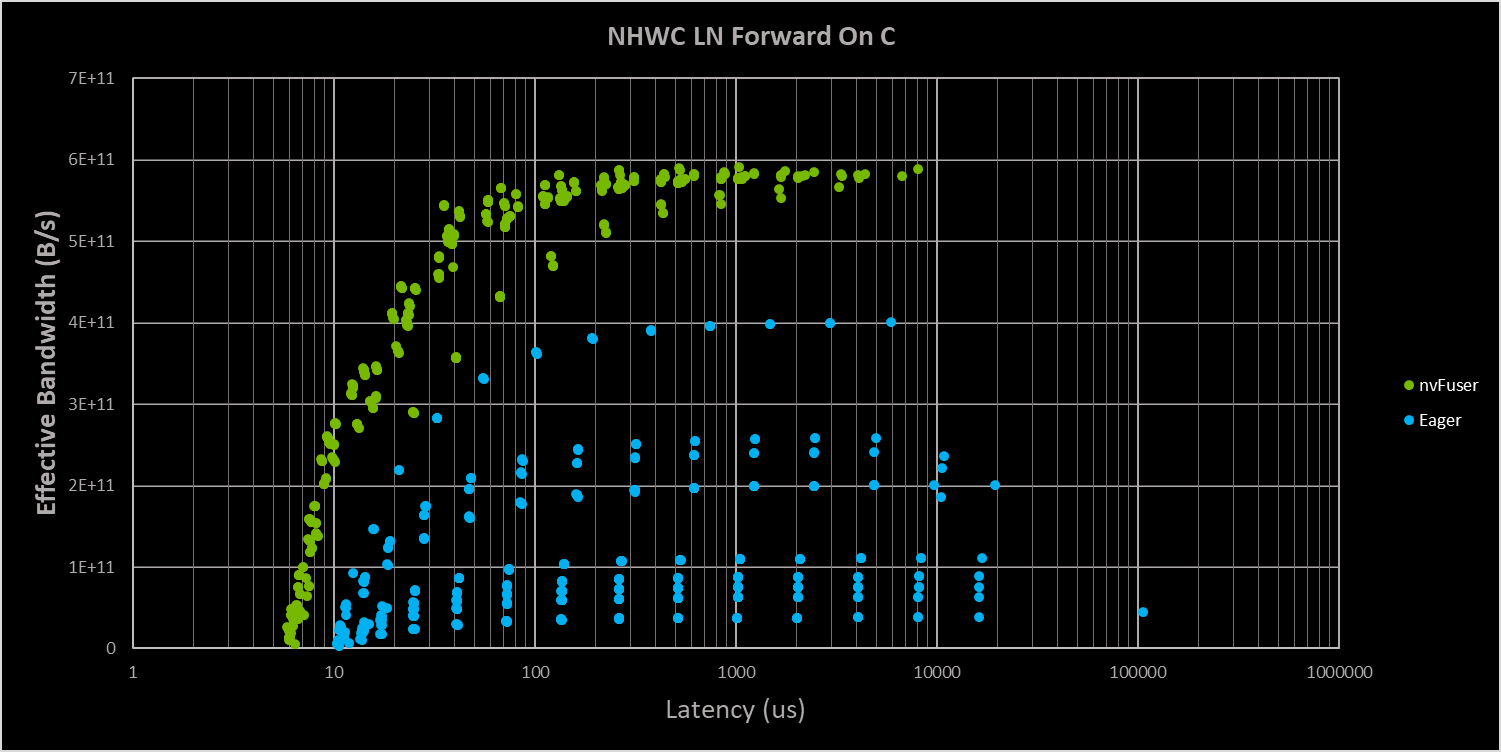
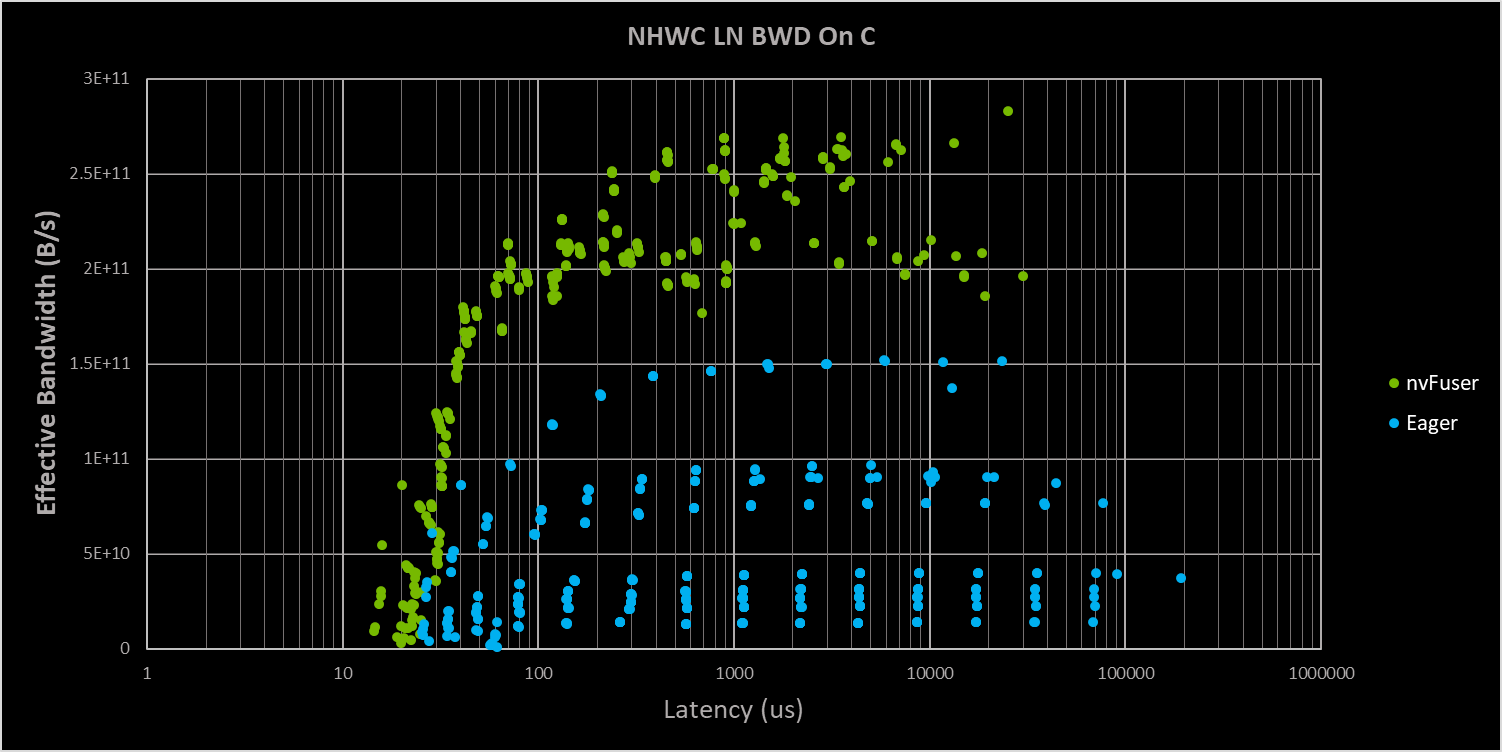
So it does look like nvFuser is getting performance around what I would expect, and there seems like little room for improvement on the forward. The backwards clearly has much lower performance, and for LayerNorm this is because in backwards you have two orthogonal directions the reduction goes across. You'll have a reduction in backwards on C as well as on NHW. There is a fast LayerNorm in Apex that is capable of doing most of the two directions in a single kernel, with a small cleanup kernel, which should be able to get better performance in backwards. Short of this very aggressive optimization, I don't see a lot of room for improvement.
I'd be pretty surprised if XLA was capable of this optimization, and one thing I'm curious about is if XLA is really getting great performance here, or if there's just overall better performance on the other parts of the network.
We are planning to target this backwards LN optimization at some point, but I don't have a concrete plan for it, and it could even be after the end of this calendar year (sometime early next year is my best guess). This optimization doesn't work with all input sizes, as you have to hold the entire input in registers, so it's a fairly targeted optimization and roughly speaking your NHW*C (in fp16) needs to be < 64 * 1024 * SM count (108 for A100) so something like 7 million total elements in the input. This size could be increased by the total amount of shared memory on the GPU if we extended nvFuser to using a combination of SMEM and registers for this optimization, that would get us another 164KB per SM on A100 (minus some temporary buffers) providing a total count closer to 15 million elements.
This is far from impossible, but definitely takes some solid engineering work to do right/well.
Benchmark changes for what it's worth: https://github.com/csarofeen/pytorch/pull/1833
@csarofeen yes we're normalizing across C in the NCHW tensor. Thanks for the insight. From a high level, it was hard for me to fathom how the end results could be so different in performance (other than the lack of any op fusion in the eager case).
Would the Apex LN provide any benfits here if combined with the needed permute to/from NHWC?
With XLA, often a bit surprised how well it does, but it certainly has some quirks, esp re shapes. Having talked to some XLA / TPU people when working through EvoNorm it was highly recommended to use the (x * x).mean() - (u * u)) form of var calc as it allows ops to be scheduled with fewer dependencies across various execution units. For the simple ResNet case LN was having a bit of trouble, but only down 10% for train throughput vs BN and GN (which were roughly on par).
I think it would perform marginal gains, but yeah, I'm trying to think what XLA is doing that's so amazing, or what are we doing that's so bad that nvFuser perf isn't good.
Do you have "the" network you want fast? I don't think we can pick out a bunch of networks, but if you have a network of "this is unreasonably fast on XLA, and unreasonably slow on PyT". I would like to look through it with the team and see what it seems like we're missing.
The general concern I would have, is if what we really need is convolution - normalization fusions, or matmul - normalization fusions. These are on our radar, but we have some distance to cover before we're there. If it's short of advanced conv/matmul fusions I would think we should be able to get something on the same order of XLA, without the shape cliffs.
Would the Apex LN provide any benfits here if combined with the needed permute to/from NHWC?
Just to be clear, for channels last inputs permutation is a very fast op on tensor metadata (no data movement) that makes tensor contiguous, and then existing (or generated) layer norm kernels operating on the last dimension can be called, followed by another fast permutation with no data movement. For normal NCHW tensor this permute operation leads to a non-contiguous tensor, so in core a copy kernel is first called to make it contiguous (that's extra overhead, copy kernel is slow), and codegen might have a bit of trouble with it because it's non-contiguous. So, bottom line, for channels last, permutation is not a problem and shouldn't affect perf
(x * x).mean() - (u * u)) People are fond of this approximation and it is indeed very easy to compute, but it's also much less accurate than two-pass or Welford approach, which might or might not be ok, but very hard to say in advance without doing full training. For inference it's almost always fine, but it can lead to large differences in gradient. If it indeed turns out to be perf-critical it needs to be kept behind some flag so people are able to turn it on/off
@ngimel @csarofeen so, quick check of apex LN in the ResNet50 case (which is quite a bit worse for my measurements than in many of the hybrid cnn-transformer models). It's way faster. Numbers below are for eager.
contiguous: apex -> 2700 im/sec infer, 940 train torch -> 1470 im/sec infer, 470 train
channels_last: apex -> 2800 im/sec infer, 960 train torch -> 1410 im/sec infer, 510 train
So, I think that's 'good enough' for me to stop spending any more time on this. If we could get the apex performance as a default in torch I'd be pretty happy. I might try to work the current apex layer into timm so I can use it for training right now, unfortunately, the apex fn isn't useable with torchscript so I can't make it the default when apex is installed... I did try with apex LN + aot-autograd, it manged to run fwd (5000 im/sec for CL), but blew up with a 'Invalid Node' error manipulating the graph for bwd.
I'll try it on some of the other models I actually use NCHW LN with. ResNet was just a familiar and worst case performance difference. I'd never actually want to use LN with it :)
EDIT: yeah, convnext numbers are looking better too, with Apex LN eager throughputs for train are at or better than the best (full model) codegen that you see in the extensive gist comparison I shared...
To be clear, I'm comparing:
class LayerNorm2d(nn.LayerNorm):
def __init__(self, num_channels, eps=1e-6, affine=True):
super().__init__(num_channels, eps=eps, elementwise_affine=affine)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return fused_layer_norm_affine(
x.permute(0, 2, 3, 1), self.weight, self.bias, self.normalized_shape, self.eps).permute(0, 3, 1, 2)
instead of
class LayerNorm2d(nn.LayerNorm):
def __init__(self, num_channels, eps=1e-6, affine=True):
super().__init__(num_channels, eps=eps, elementwise_affine=affine)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return F.layer_norm(
x.permute(0, 2, 3, 1), self.normalized_shape, self.weight, self.bias, self.eps).permute(0, 3, 1, 2)
FY my resnet50 test case for ln was a quick hack in resnet.py
@register_model
def resnet50_ln(pretrained=False, **kwargs):
from .layers.norm import LayerNormExp2d, LayerNormExpNg2d, LayerNorm2d # different LN experiments
model_args = dict(block=Bottleneck, layers=[3, 4, 6, 3], **kwargs)
return _create_resnet('resnet50_ln', pretrained, norm_layer=LayerNorm2d, **model_args)
If Apex LN is working for you go for it, it's disappointing because it's highly unlikely the big perf difference is because of the code generated but the integration in the stack. I'm happy you're unblocked, and we'll keep cranking away with these issues :-(
A difference this big ins't adding up. And also Natalia's promising fusion codegen tests being done in float16, all of mine in AMP (since that's how I train). And looking at the apex fused LN impl, it's disabling torch native autocast and casting itself, so possibly differences due to casting (or lack of in some cases).
Without AMP (infer / train throughputs): float16 - apex - 2710 / 950 float16 - torch - 2600 / 790 float32 - apex - 1370 / 450 float32 - torch - 1310 / 410
So apex still better, but more realistically so.
EDIT: so now the question, what's going on in mixed-precision. Is casting being handled differently, is one casting incorrectly? Is LN cast differently than BN?
Yes, layer_norm is force-cast to fp32 by amp (tbh, I don't know if it's strictly necessary or is it out of abundance of caution, I've heard some stories where it indeed prevents convergence, but also other stories of people casting model whole-sale with ln to fp16 and still converging), whereas batch_norm is left in whatever precision the inputs come in. Same is true for group_norm, it's force-cast. Layer norm in core is marginally more accurate than layer norm in apex (it's guaranteed to produce the same results as layer norm for inputs cast to fp32, whereas apex does some intermediate truncations in the final computations), but perf difference with force casting of course will be huge in eager, so probably we should have a mechanism to adjust amp cast lists.
Yes, layer_norm is force-cast to fp32 by amp (tbh, I don't know if it's strictly necessary or is it out of abundance of caution, I've heard some stories where it indeed prevents convergence, but also other stories of people casting model whole-sale with ln to fp16 and still converging), whereas batch_norm is left in whatever precision the inputs come in. Same is true for group_norm, it's force-cast. Layer norm in core is marginally more accurate than layer norm in apex (it's guaranteed to produce the same results as layer norm for inputs cast to fp32, whereas apex does some intermediate truncations in the final computations), but perf difference with force casting of course will be huge in eager, so probably we should have a mechanism to adjust amp cast lists.
@ngimel Yeah, that's the conclusion I ended up coming to here, I think I even remember discovering that re group_norm some time ago, and then had it pushed out of my brain other things... fun spending that much time rediscovering it. I wonder if past reported instabilities re layernorm without the force-cast were due to use in larger scale transformer training, hmm.
It's my understanding that regardless of the cast, the reductions would still accumulate in float32, it's the dtype of input, affine parms, output etc that would differ in terms of float32 vs float16. So, yeah, seems likely that it may not be an issue to change the cast behaviour.
So, I'm creating my own 'fast' path (off by default) to experiment with this, it'll look something like below (doing similar to what apex is doing for the torch case). The ability to modify the torch cast lists would be quite useful though. There is an open issue on that, but no recent progress.
def fast_torch_layer_norm(
input: torch.Tensor,
normalized_shape: List[int],
weight: Optional[torch.Tensor] = None,
bias: Optional[torch.Tensor] = None,
eps: float = 1e-5
):
args = _cast_if_autocast_enabled(input, normalized_shape, weight, bias, eps)
with torch.cuda.amp.autocast(enabled=False):
return F.layer_norm(*args)
class LayerNorm2d(nn.LayerNorm):
""" LayerNorm for channels of '2D' spatial NCHW tensors """
def __init__(self, num_channels, eps=1e-6, affine=True):
super().__init__(num_channels, eps=eps, elementwise_affine=affine)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = x.permute(0, 2, 3, 1)
if _ENABLE_FAST_NORM:
if has_apex:
x = fused_layer_norm_affine(
x,
self.weight,
self.bias,
self.normalized_shape,
self.eps)
else:
x = fast_torch_layer_norm(
x,
self.normalized_shape,
self.weight,
self.bias,
self.eps)
else:
x = F.layer_norm(
x,
self.normalized_shape,
self.weight,
self.bias,
self.eps)
x = x.permute(0, 3, 1, 2)
return x
Sorry, wouldn't _cast_if_autocast_enabled cast all inputs to fp32? I couldn't find this function.
Sorry, wouldn't
_cast_if_autocast_enabledcast all inputs to fp32? I couldn't find this function.
@ngimel it casts the args to get_autocast_gpu_dtype()