papernotes
 papernotes copied to clipboard
papernotes copied to clipboard
Neural Baby Talk
Metadata
- Authors: Jiasen Lu, Jianwei Yang, Dhruv Batra, Devi Parikh
- Organization: Georgia Institute of Technology & Facebook AI Research
- Conference: CVPR 2018
- Paper: https://arxiv.org/pdf/1803.09845.pdf
- Code: https://github.com/jiasenlu/NeuralBabyTalk
Summary
- Novel framework for image captioning that can produce natural language explicitly grounded in entities that object detectors find in the image.
- Two step approach: First generate natural language with slots (i.e., template) and then fills in the slots with text by recognizing the content in the corresponding image region.
- Propose zero-shot image captioning task (i.e., seen object combination in training but unseen object combination in testing) for benchmarking.
- State-of-the-art performance on COCO and Flickr30k datasets on the standard image captioning task, and significantly outperforms existing approaches on the zero-shot image captioning and novel object captioning task.
Problems

- Current models lack of visual grounding (i.e., do not associate named concepts to pixels in the image).
- They often tend to ‘look’ at different regions than humans would and tend to copy captions from training data.
- Today's neural captioning models tend to produce generic plausible captions based on the language model that match a first-glance gist of the scene. (Learns correlations from training data and fails to generalize novel combinations of object from testing data).
- The language generated by current neural image captioning model is much more natural but tends to be much less grounded in image while classical approach that used a slot filling to talk about the objects and attributes found in the scene via a templated caption is unnatural but the caption is very much grounded in what model sees in the image.
- State-of-the-art neural models use attention regions to 'ground' generated words. In practice, these attention regions tend to be quite blurry, and rarely correspond to semantically meaningful individual entities (e.g., objects instances) in the image.
Method

Slotted Caption Template Generation
- At each time step t, the decoder decides whether to generate a word from textural vocabulary or from a "visual" word. For instance, for the image in Figure 1., the generated sequence may be “A
<region−17>is sitting at a<region−123>with a<region−3>.” These visual words<region−[.]>are then filled in during a second stage that classifies each of the indicated regions (e.g.,<region−17>→puppy,<region−123>→table,<region−3>→cake), resulting in a final description of “A puppy is sitting at a table with a cake.” - The regions r_I are detected by object detector first, and then compute the probability distribution over the visual words P_{r_I} using pointer network (compute attention scores over the detected region features with RNN decoder hidden state).
- Since textual words are not tied to specific regions in the image. they add a "visual sentinel" r~ as a latent variable to serve as "dummy region" grounding for the texture words [1].
- Compute the attention score for "visual sentinel" also with the same RNN decoder hidden state, concatenate it to the end of the other regions' attention scores, and then softmax them to get the probability distribution over grounding regions and visual sentinal P_{r}^{t} (see Figure 3).
- Get the visual sentinel probability p(r~) from the last element of P_{r}^{t}.
- Compute probability distribution over textual words P_{txt}^{t} from the decoder hidden state (see Figure 3).
- Finally, the probability distribution of the texture words is the product of P_{txt}^{t} and P_{r~}^{t}.
Caption Refinement: Filling In The Slots
- The output category name of the object detector are typically singular coarse labels (e.g., "dog") while captions often refer to these entities in a fine-grained fashion (e.g., "puppy" or in the plural form "dogs").
- Consider two factors for the refinement of category name: Plurality and fine-grained class with 2 MLPs respectively. The fine-grained words come from pretrained GloVe vocabulary.
Objective

- The objective can incorporate different kinds of supervisions:
- Strong supervision (Flickr30): Which words in the caption are grounded in which boxes in the image.
- Weak supervision (COCO): Objects are annotated in the image but are not aligned to words in the caption.
- y_{t}* is the ground-truth word at time step t.
- 1_(y{t}* = y^{txt}) is the indicator function which equals to 1 if y{t}* is textual word and 0 otherwise.
- b{t}* and s{t}* are the target ground truth plurality and fine-grained category name.
- {r_{t}^{i} | i=1~m} ∈ r_I are the target grounding regions of the visual word at time step t.
Visual Word Extraction
- During training, visual words in a caption are dynamically identified by matching the base form of each word using the lemmatization tool.
- The grounding regions {r_{t}^{i} | i=1~m} for a visual word y_{t} is identified by computing the IoU of all boxes detected by the object detector with the ground truth bounding box associated with the category corresponding to y_{t}. t. If the score exceeds a threshold of 0.5 and the grounding region label matches the visual word, the bounding boxes are selected as the grounding regions. E.g., given a target visual word “cat”, if there are no proposals that match the target bounding box, the model predicts the textual word “cat” instead.
Implementation Details
- Object detector: Faster R-CNN with ResNet-101 backbone.
- Region feature: Concatenation of pooling features of RoI align layer [2] given the proposal coordinates; embedded normalized bounding box location feature; GloVe embedding of the class label for region.
- Language model: An attention model with two LSTM layers [3].
- Refer more to the paper.
Reference
- [1] Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning by Jiasen Lu, +2 authors, Richard Socher. CVPR 2017.
- [2] Mask R-CNN by Kaiming He et al. ICCV 2017.
- [3] Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering by Peter Anderson et al. CVPR 2018.
Why resnet-101 is image encoder? What does it encode? I found no information of this in NBT and am also wondering exactly how Faster RCNN and resnet are used separately? I am thinking of FasterRCNN for proposal and resnet for detecting object from proposal. Is that right? Anw, your note doesn't reflect deep understanding ab this paper I think.
@luulinh90s Hi, what I meant here is ResNet-101 serves as the backbone image encoder for Faster-RCNN. They are not used separately. Maybe I should write "Faster-RCNN with ResNet-101 backbone" would be more clear to the readers. Thanks for point that out :-)
I think the most important thing in this paper is this figure, so could you please share your understanding about this figure:
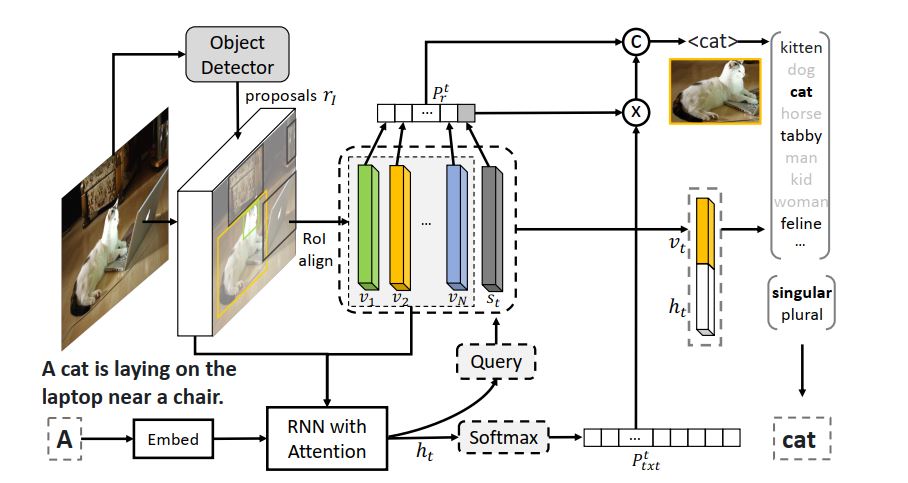 There are few questions should be clarified:
There are few questions should be clarified:
- How visual words are generated? AFAIK, from Faster RCNN, we just have proposals now, then we need an object detector to detect the objects in proposals, but I do not see.
- What is the meaning of Query? What is the meaning of st or block (C) before
. The explanation in this paper I believe that is unclear enough. If you have time to look, could you show me?
For block C, C operation (Compare) is to compare the prob.s to determine whether the next word should be visual or textual, right?
Found how we calculate the visual word here:
fg_out = self.fg_fc(pool_feats) # Fine-graned fully connected to output 1x1x410
# construct the mask for finegrain classification.
# fg_out
fg_score = torch.mm(fg_out.view(-1,300), self.fg_emb.t()).view(seq_batch_size, -1, self.fg_size+1) # 1x1x410
fg_mask = self.fg_mask[fg_idx]
fg_score.masked_fill_(fg_mask.view_as(fg_score), self.min_value)
fg_logprob = F.log_softmax(self.beta * fg_score, dim=2)
Here Faster RCNN produce almost the last conv features, then we just need to feed to one more FC layer to get the final scores over classes.
@luulinh90s :
How are visual words generated?
To my understanding (it might be wrong), I think first, we get the region proposals from Faster-RCNN. For example, we can index those regions like <region-i>. And let's say, 10 regions are detected from a given image, thus we have <region-1> to <region-10> (as illustrated in paper). Each region associates with its predicted "coarse" category. These categories provided by Faster-RCNN are "visual words". If a target visual word is not presented in region proposals during training, it would be produced by the textual vocabulary, which is decided by the learned visual sentinel (the prob. of visual sentinel will multiply the prob. of textual vocabulary to either increase or decrease the prob. of textual vocabulary as illustrated in the figure.)
What is the meaning of Query?
The term/concept "query" is actually from the paper "Attention is All You Need" along with the other terms "key" and "value". The query here is just a input for computing attention weights for pointer network.
What is the meaning of s_t?
It is the representation of “visual sentinel” (~r), and how it is computed is defined in Eq. (8) in the paper.
What is the meaning of block C in the figure?
The paper does not illustrate this but yes, my understanding is same as yours, which is comparing whether the word is outputted from the region's category or textural vocabulary. (But I think the right way should be a "gated mechanism" instead of a comparison operation, see pointer-generator network for similar idea.)
@luulinh90s I will stop the discussion here since I've been busy recently. Hope my answers help! :-)