papernotes
 papernotes copied to clipboard
papernotes copied to clipboard
On Distinguishability Criteria for Estimating Generative Models
Metadata
- Author: Ian J. Goodfellow
- Organization: Google
- Conference: ICLR 2015
- Paper: https://arxiv.org/pdf/1412.6515.pdf
Motivation to read this paper
After I read the paper "Adversarial Contrastive Estimation" (#23), which replaces the original fixed noise generator in noise contrastive estimation (NCE) with the dynamic noise generator using with GAN training, some questions like "How does NCE relate to GANs?", "NCE is closely related to MLE, and how about GANs?" naturally rises in my mind.
This paper compares MLE, NCE, GAN and gives several initial answers to:
- A modified version of NCE with a dynamic generator is equivalent to maximum likelihood estimation (MLE).
- The existing theoretical work on GANs does not guarantee convergence on practical applications.
- Because GANs do the model estimation in the generator network, they cannot recover maximum likelihood using its value function.
In conclusion, the analysis shows that GANs are not as closely related to NCE as previously believed.
Notes:
- You need to also read Notes on NCE (the last comment at #23) in order to understand this paper. This notes is a supplementary to #24.
- The gradient of NCE can be approximated to the gradient of MLE (as shown in the paper "A fast and simple algorithm for training neural probabilistic language models").
Comparison (from NIPS 2016 Tutorial: Generative Adversarial Networks or watch video from 1:00:17)

Sorry for the inconsistent notation.
Similarities
- NCE, MLE and GANs can be interpreted as strategies for playing a minimax game with the same value function V:
 (p_{c}: classifier(discriminator); p_{g}: generator; p_{d}: real data distribution)
(p_{c}: classifier(discriminator); p_{g}: generator; p_{d}: real data distribution) - p_{g} = p_{d} in MLE (can be seen as the model constantly learns its own shortcomings and distinguish its own samples from the data).
- MLE, NCE and GANs are all asymptotically consistent, which means that in the limit of infinitely many samples from real data distribution, their criteria each have a unique stationary point that corresponds to the learned distribution matching the real data distribution (i.e, p_{m} = p_{d})
Note: Asymptotically consistent estimator: See https://en.wikipedia.org/wiki/Consistent_estimator
Different p_{c}
- NCE has explicit posterior probability distribution for p_{c}, while in GANs, p_{c} is parameterized directly (e.g., a neural net):
 (p_{m}: model that NCE aims to learn (e.g., language model); p_{g}: fixed noise generator)
(p_{m}: model that NCE aims to learn (e.g., language model); p_{g}: fixed noise generator)
Note: See the derivation in Notes on NCE (#23).
Different goals
- The goal of NCE is to learn the generative model p_{m} within the discriminator p_{c}.
- The goal of GANs is to directly learn the generator p_{g}.
Different training objectives
- MLE & NCE: p_{c} is trained to maximize V (indirectly train p_{m} to maximize V).
- GANs: p_{c} is trained to maximize V and p_{g} is trained to minimize V.
Different stationary points when converges
- MLE & NCE: A global maximum of V.
- GANs: A saddle point that is a local maximum for p_{c} and a local minimum for p_{g}.
Different convergence properties
- MLE & NCE is guaranteed to converge for smooth functions that are bounded from above regardless of whether these objective functions are convex. It is possible for optimization to get stuck in a local maximum in parameter space, but the optimization process will at least arrive at some critical point.
- In the case of GANs, the generator is updated while holding the discriminator fixed, and vice versa. In function space this corresponds to performing subgradient descent on a convex problem, and is guaranteed to converge. In the non-convex case, the existing theory does not specify what will happen.
NCE can implement MLE: Self-Contrastive Estimation (SCE)
- The performance of NCE is highly dependent on the choice of noise distribution, since it is not difficult to discriminate data samples from totally unstructured noise. Thus, models trained with too simplistic of a noise distribution often underfit badly.
- As pointed out by Gutmann et al., "Intuitively, the noise distribution should be close to the data distribution, because otherwise, the classification problem might be too easy and would not require the system to learn much about the structure of the data. ......, one could choose a noise distribution by first estimating a preliminary model of the data, and then use this preliminary model as the noise distribution.".
- Consider the extreme case of the above approach, where noise distribution p_{g} copies model distribution p_{m} after every step of learning. (a.k.a. SCE).
- Result: SCE has the same expected gradient as MLE (see derivation in this paper):
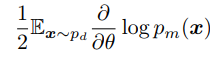 (1/2 can be folded into the learning rate)
(1/2 can be folded into the learning rate)
Note: There is a error in the derivation of SCE's expected gradent: The equation 1/2 E_{x~p_g} log (p_g(x)) should be 1/2 E_{x~p_g} ∂/∂θ log (p_g(x)).
GANs cannot implement MLE
See derivation in the paper.
Reference
- Noise-contrastive estimation: A new estimation principle for unnormalized statistical models [pdf] [slides] by M. Gutmann, and A. Hyvärinen. AISTATS 2010.