papernotes
 papernotes copied to clipboard
papernotes copied to clipboard
Unsupervised Machine Translation using Monolingual Corpora Only
Metadata
- Authors: Guillaume Lample, Ludovic Denoyer, Marc'Aurelio Ranzato
- Organization: Facebook AI Research
- Conference: ICLR 2018
- Link: https://openreview.net/forum?id=rkYTTf-AZ
Summary
This paper purposed an unsupervised approach to neural machine translation (NMT) using monolingual corpora only. The principle is first use unsupervised word-by-word translation model, iteratively improve this model based on denoising and adversarial training to align latent distribution of different languages.
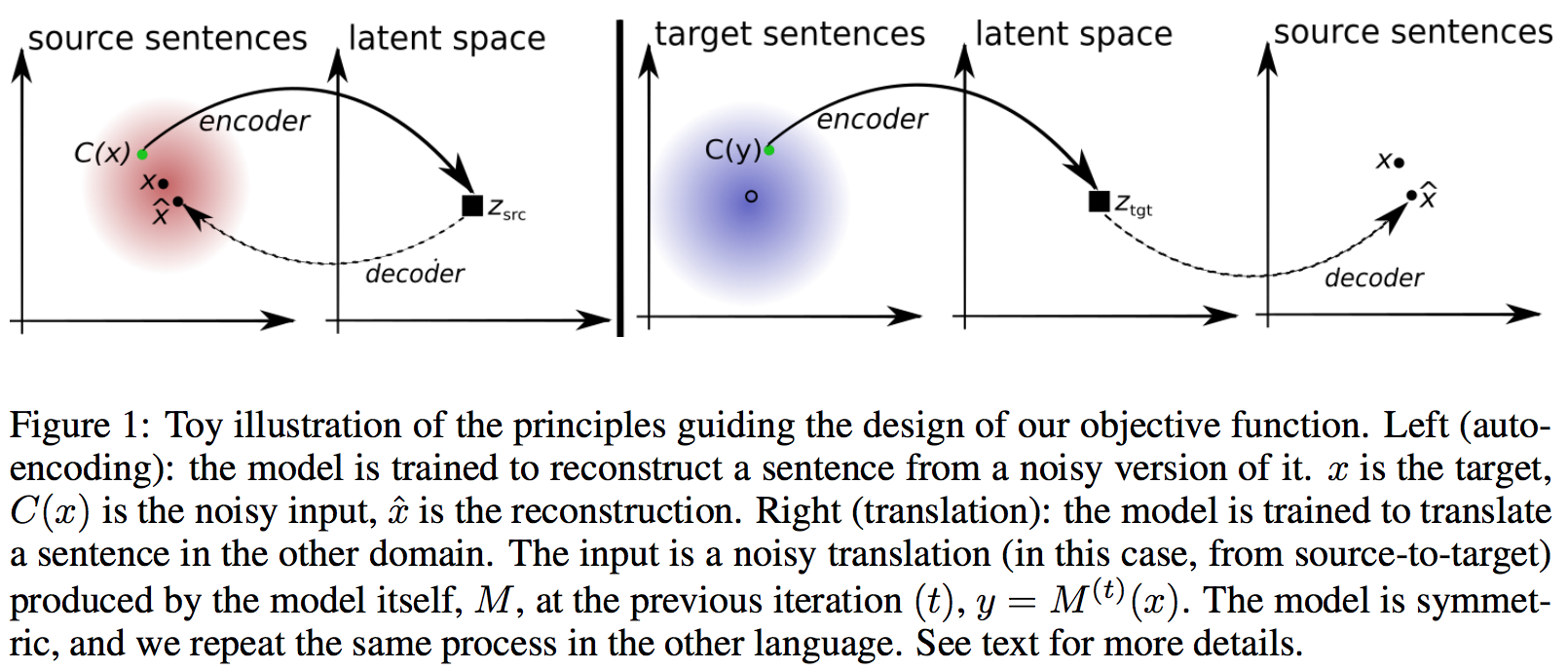
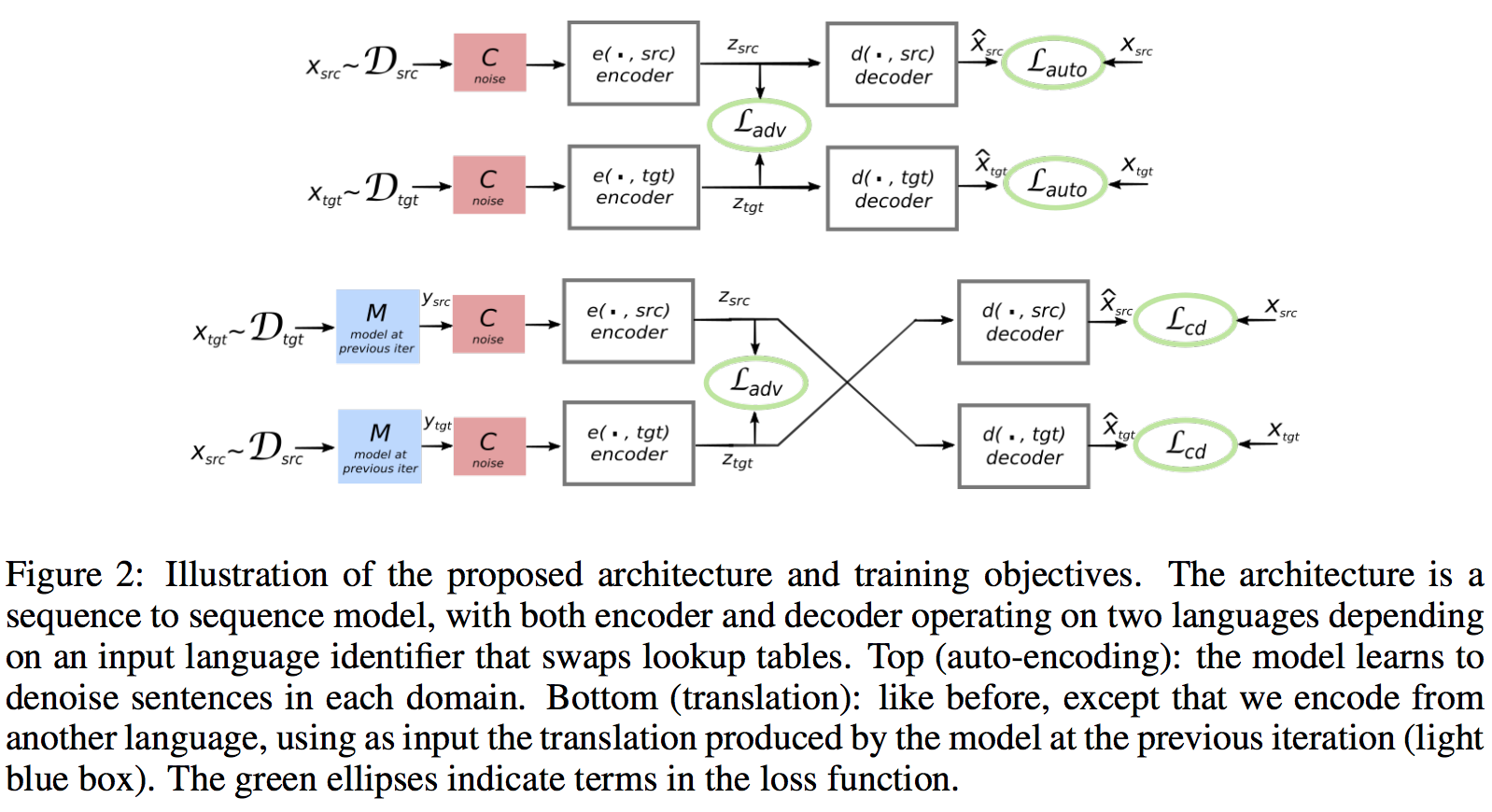
Motivation
- NMT requires large-scale parallel corpora in order to achieve good performance.
- Even translating low resource language pairs requires tens of thousands of data.
- Monolingual data is much easier to find.
Model
- Use a single encoder and a single decoder for both domains.
- Use sequence-to-sequence model with attention (Bahdanau et al. 2015).
Training Objectives
Initialization
The model starts with an unsupervised naive translation model obtained by making word-by-word translation of sentences using a parallel dictionary learned in an unsupervised way (Conneau et al. 2017). Then, at each iteration, the model are trained by minimizing an objective function that measures their ability to both reconstruct and translate from a noisy input sentence.
Denoising Auto-Encoding (Critical to performance)
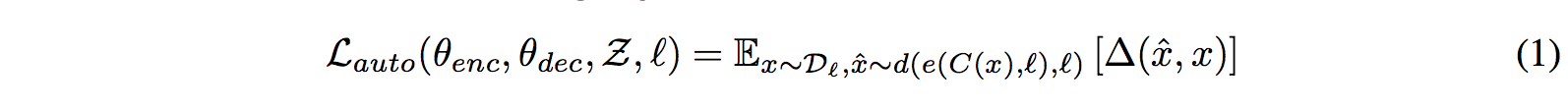 Δ is the sum of token-level cross-entropy loss between the sentence x and the reconstruction from the noisy sentence x_hat. The noisy model C is created by dropping and swapping tokens in the sentence.
Δ is the sum of token-level cross-entropy loss between the sentence x and the reconstruction from the noisy sentence x_hat. The noisy model C is created by dropping and swapping tokens in the sentence.
Cross Domain Training (Back-translation)
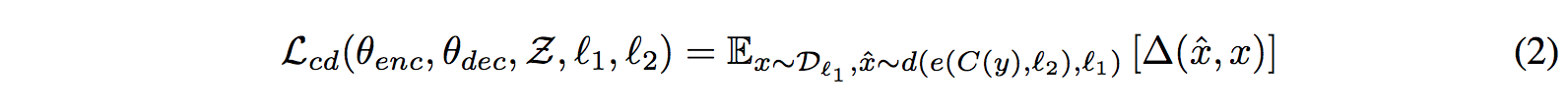 Learn to reconstruct the sentence x from C(y), where y = M(x) is the translation of x, M is the current translation model, and Δ is again the sum of token-level cross-entropy loss.
Learn to reconstruct the sentence x from C(y), where y = M(x) is the translation of x, M is the current translation model, and Δ is again the sum of token-level cross-entropy loss.
Adversarial Training
Jointly train a discriminator to classify the language given the encoding of source sentences and the encoding of target sentences (Ganin et al. 2016). In detail, the discriminator operates on a sequence of encoded hidden state vectors, and produces a binary prediction (0: source; 1: target). The discriminator is trained by minimizing the cross-entropy loss:
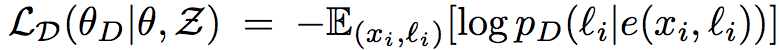
The encoder is trained instead to fool the discriminator:
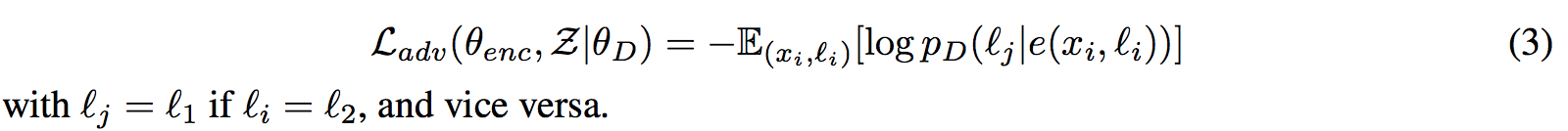
Final Objective
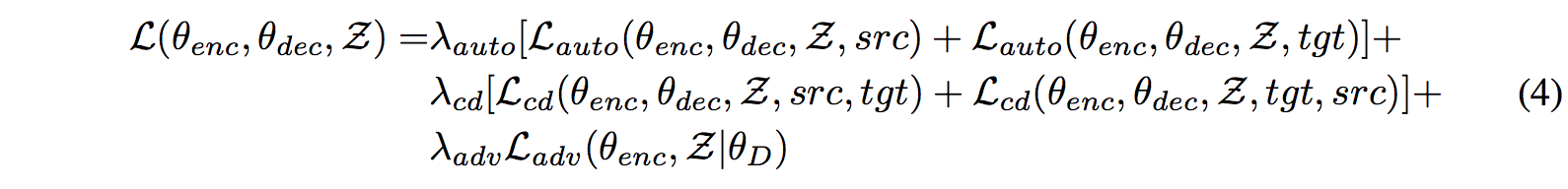 λauto, λcd, λadv are hyper-parameters.
λauto, λcd, λadv are hyper-parameters.
Training Algorithm

Model Selection
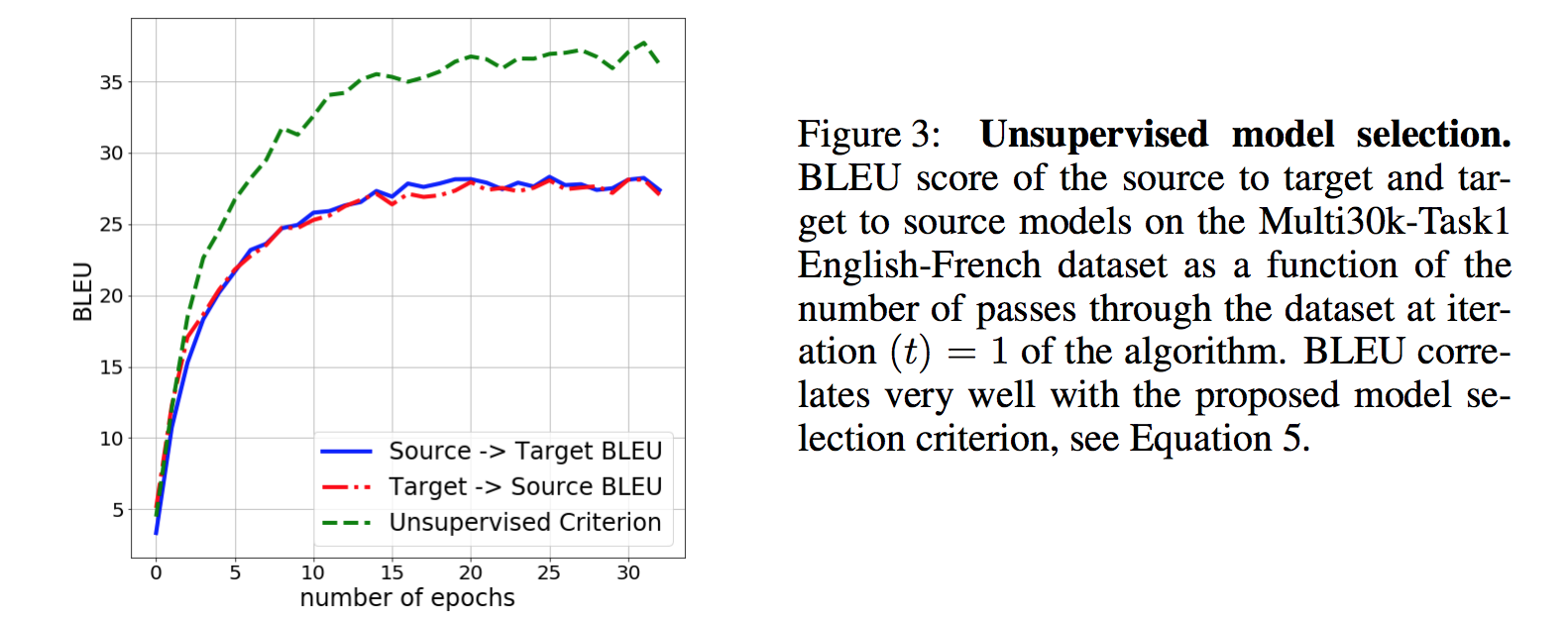
Since no parallel data for validation, they use the surrogate criterion:
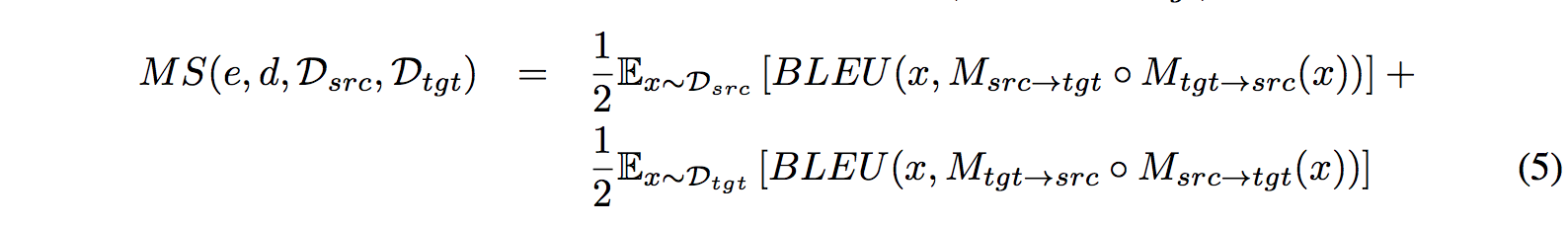
The figure bellow shows the correlation between this measure and the final translation model performance evaluated with parallel test set.
Experiments
Datasets and Preprocessing
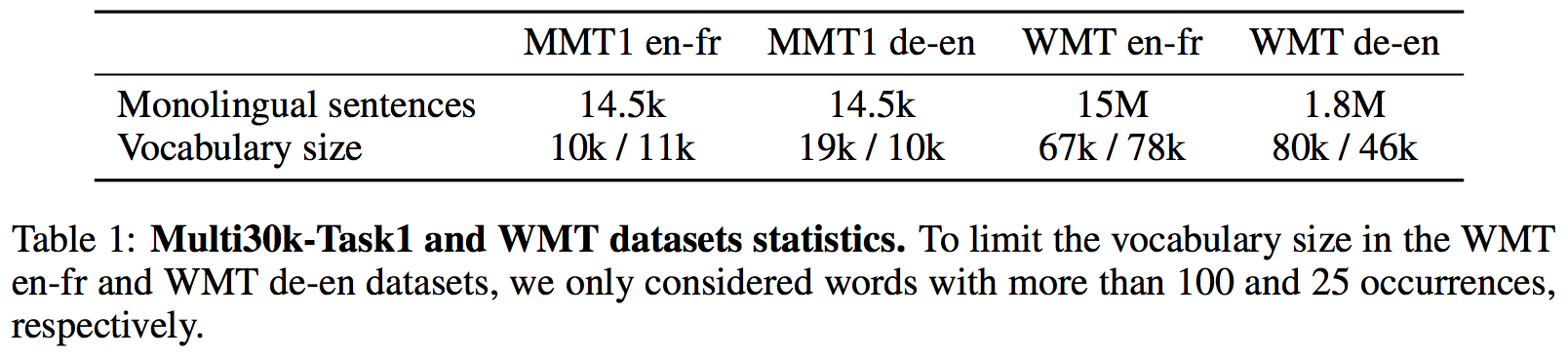
- WMT'14 English-French: Full training set, 36 million pairs. After preprocessing with all lowercase, remove sentences longer than 50 words, source/target length ratio above 1.5, resulting in a parallel corpus of about 30 million sentences. Build monolingual corpora by selecting the English sentences from 15 million random pairs (English monolingual corpus), and selecting the French sentences from the complementary set (French monolingual corpus). Validation set is comprised of 3000 English and French sentences extracted from the monolingual training corpora described above.
- WMT'16 English-German: Same procedure as above, resulting in two monolingual training corpora of 1.8 million sentences each. Test set uses newstest2016 dataset.
- Multi30k-Task1: A multi-lingual image descriptions containing 30000 images. They consider English-French and English-German pairs (discard images). Training, validation and test sets are composed of 29000, 1000 and 1000 pairs of sentences respectively. Similar to the WMT datasets above, they split the training and validation sets into monolingual corpora, resulting in 14500 monolingual source and target sentences in the training set, and 500 sentences in the validation set.
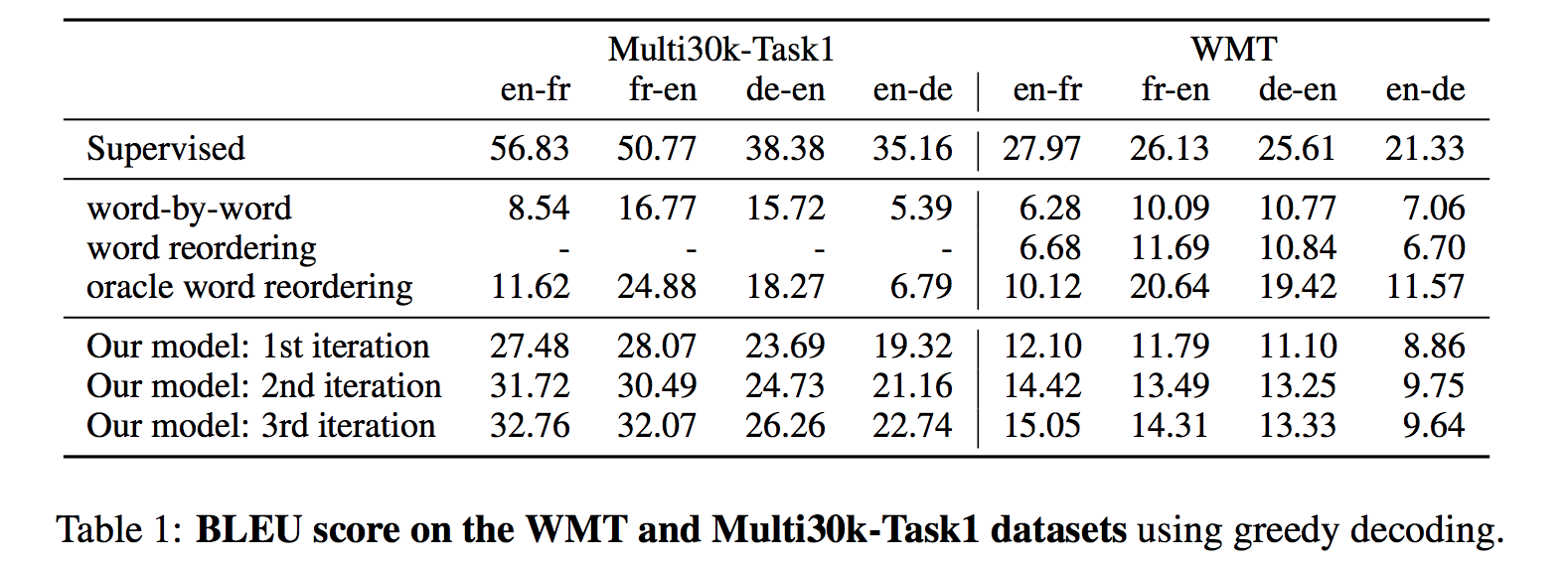
Baselines
- Word-by-word translation (WBW): Simply perform word substitution using inferred bilingual dictionary. Work surprisingly well on English-French where word order is similar, but performs rather poorly on more distant pairs like English-German.
- Word reordering (WR): After translating by WBW, they further reorder words using an LSTM-based language model trained on the target side by all pairwise swapping the neighboring words, since exhaustively score every word permutation is computationally expensive.
- Oracle word reordering (OWR): Using the reference, they produce the best possible generation using only the words given by WBW. Consider this baseline as an upper-bound of what any model could do without replacing words.
- Supervised learning: Exactly the same model as purposed in this paper, but trained with supervision on the original parallel sentences.
Unsupervised Dictionary Learning
- First train word embeddings on the source and target monolingual corpora (Wikipedia) using fastText (Bojanowski et al. 2017).
- Apply unsupervised word translation method (Conneau et al. 2017) to infer a bilingual dictionary.
Experimental Details
- Discriminator architecture: 3-layer feedforward network, with each hidden layers of size 1024, Leaky-RELU and sigmoid output unit. Following Goodfellow (2016), they use label smoothing with coefficient s = 0.1.
- Training details: The NMT is trained using Adam optimizer with learning rate 0.0003, β1 = 0.5, batch size 32; The discriminator is trained using RMSProp with a learning rate of 0.0005. Evenly update the parameters between NMT and discriminator. They set λauto = λcd = λadv = 1.
Experimental Results
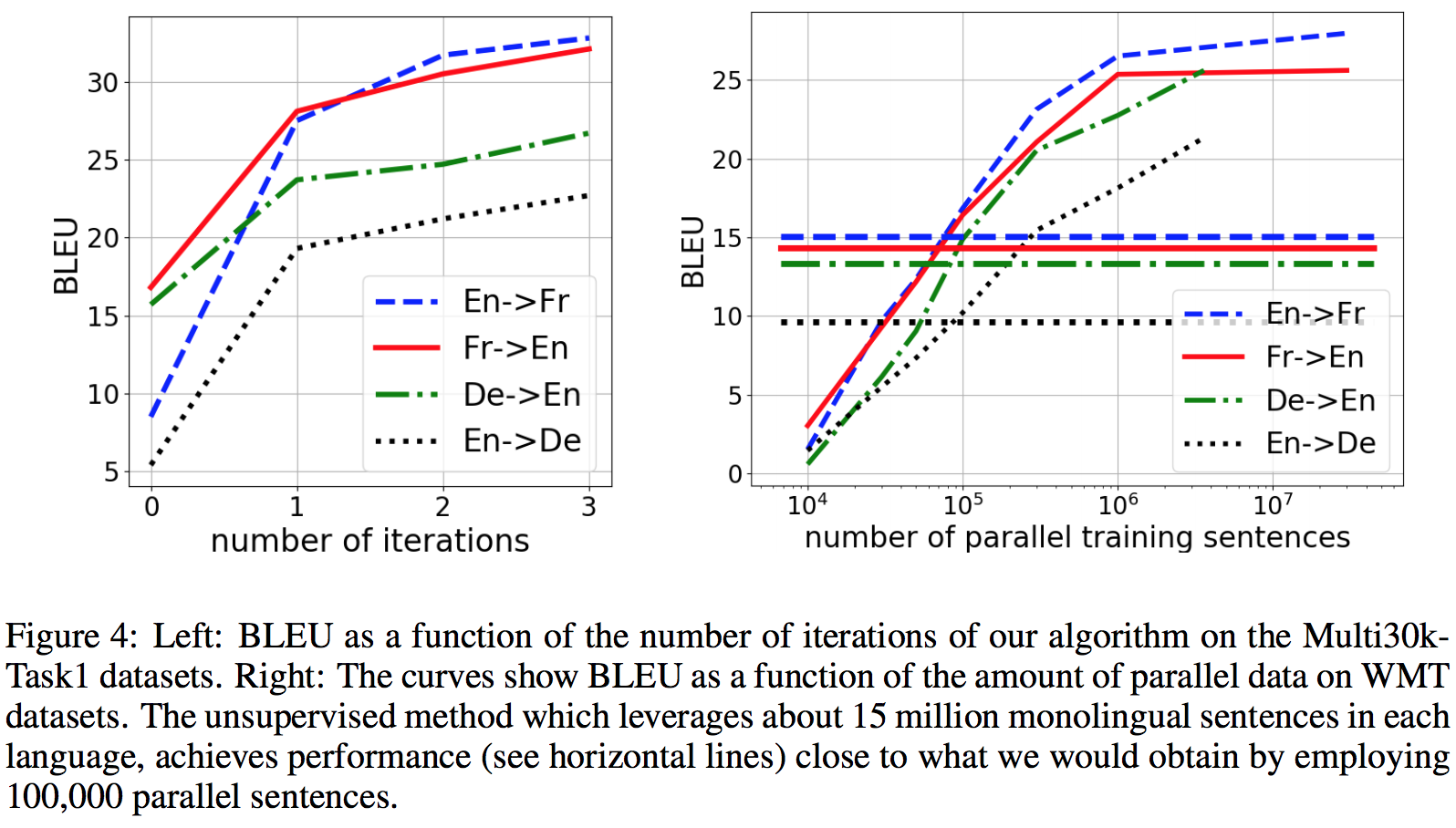
The following right figure shows their unsupervised approach obtains the same performance than a supervised NMT model trained on about 100000 parallel sentences.
Ablation Study
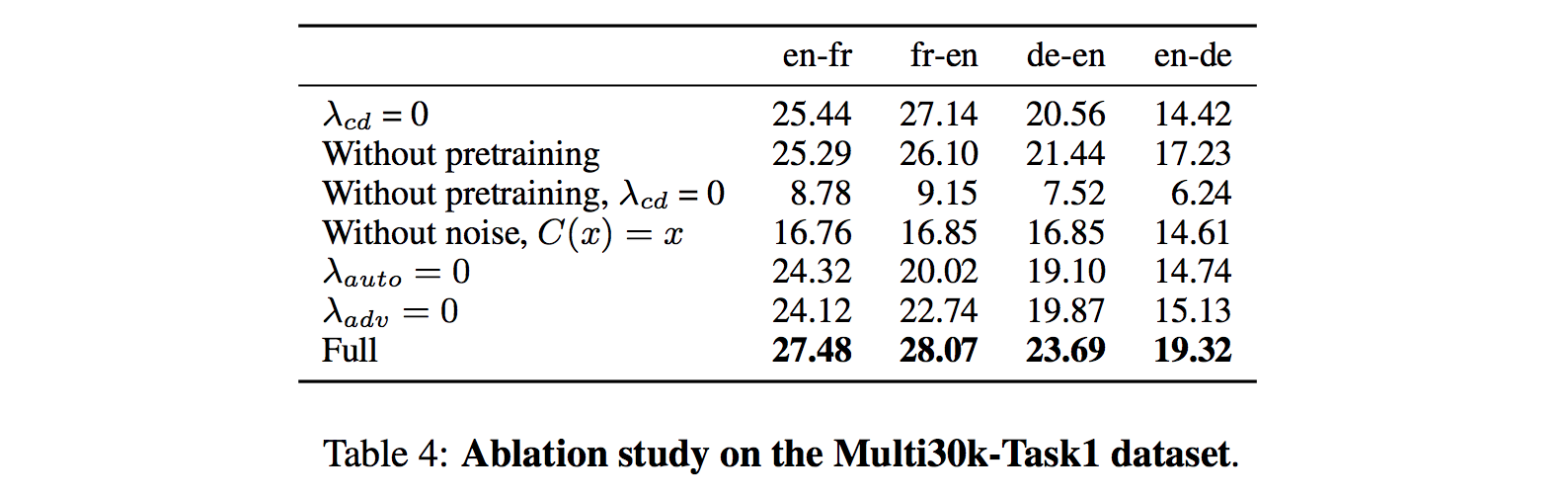
- The most critical part is the both unsupervised word translation and back-translation.
- The second critical part is the denoising auto-encoder, especially the noisy model.
- The last but not the less critical part is adversarial training, ensuring that to really benefit from back-translation, one has to ensure that the distribution of latent sentence representations is similar across the two languages.
Personal Thoughts
The purposed word-by-word translation and word reordering baselines are still competitive to the purposed unsupervised method in the context of WMT datasets, indicating that unsupervised NMT still needs a lot of efforts to improve.
References
- Word Translation without Parallel Data by Conneau et al., 2017.
- Domain-Adversarial Training of Neural Networks by Ganin et al., 2016.
- Improving Neural Machine Translation Models with Monolingual Data by Sennrich et al., 2015.
- Neural Machine Translation by Jointly Learning to Align and Translate by Bahdanau et al., 2015.
- Domain-Adversarial Training of Neural Networks by Ganin et al., 2016.
- Enriching Word Vectors with Subword Information by Bojanowski et al., 2017.
- NIPS 2016 Tutorial: Generative Adversarial Networks by Ian Goodfellow, 2016.
For comparison to the other similar paper: Unsupervised Neural Machine Translation by Artetex et al. 2017, please refer to the slides.
Hi! Sorry! In the published paper, it is mentioned that "We will release the code to the public once the revision process is over". I will be really THANKFUL if you share the link to source code. Thank you very much!