higgsfield
 higgsfield copied to clipboard
higgsfield copied to clipboard
PPO implementation
Hi,
Is this version still up to date? I've run it with no changes but the agent scores oscillate at around -1000. I set max_frames = 100000 and still the agent doesn't improve beyond -800 reward and tends to have large performance drop offs in terms of score.
See improvements if you increase the num_steps and reset the environment after each iteration. I set num_steps to 40 from 20 and decreased the number of PPO updates to 1 per batch and the learning rate to 1e-4 and saw a significant improvement though generally it required a hefty number of iterations.
Having the same trouble. Unsure what's wrong with the implementation but it isn't working very well for me either
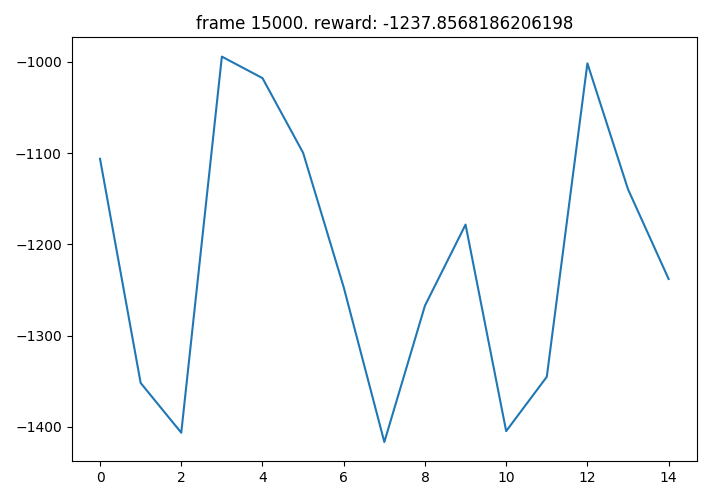
I've found increasing the num_steps to around 40 and increasing the mini_batch_size to 10-15 results in decent performance. Try decreasing the number of ppo_epochs as well and slowly increasing it based on results.
Hope that helps!
The real "game changer" for me was to run envs_reset() at each iteration
Anyone who got this to work? My results didn't improve from the methods suggested. Could it be something else? Maybe setup?
I was looking into this and I noticed that the results seem mostly dependent on the weight initialization. If you simply rerun the file multiple times, you can get results like seen above or good results like seen on the github repo. I am not sure the correct fix, but the things listed above seem to help a bit but not do anything super major.
Also, commenting out self.apply(init_weights) makes things run slightly better in general.
So, I tested a large number of hyper parameters and this seems to work a lot more consistently:
hidden_size = 32
lr = 1e-3
num_steps = 128
mini_batch_size = 256
ppo_epochs = 30
and make sure to remove/comment out self.apply(init_weights) in the neural network description.
It still isn't perfect but works better overall.
Lastly I advise updating ppo_iter to this:
def ppo_iter(mini_batch_size, states, actions, log_probs, returns, advantage):
batch_size = states.size(0)
ids = np.random.permutation(batch_size)
ids = np.split(ids[:batch_size // mini_batch_size * mini_batch_size], batch_size // mini_batch_size)
for i in range(len(ids)):
yield states[ids[i], :], actions[ids[i], :], log_probs[ids[i], :], returns[ids[i], :], advantage[ids[i], :]
So, I tested a large number of hyper parameters and this seems to work a lot more consistently:
hidden_size = 32 lr = 1e-3 num_steps = 128 mini_batch_size = 256 ppo_epochs = 30and make sure to remove/comment out
self.apply(init_weights)in the neural network description.It still isn't perfect but works better overall.
Lastly I advise updating ppo_iter to this:
def ppo_iter(mini_batch_size, states, actions, log_probs, returns, advantage): batch_size = states.size(0) ids = np.random.permutation(batch_size) ids = np.split(ids[:batch_size // mini_batch_size * mini_batch_size], batch_size // mini_batch_size) for i in range(len(ids)): yield states[ids[i], :], actions[ids[i], :], log_probs[ids[i], :], returns[ids[i], :], advantage[ids[i], :]
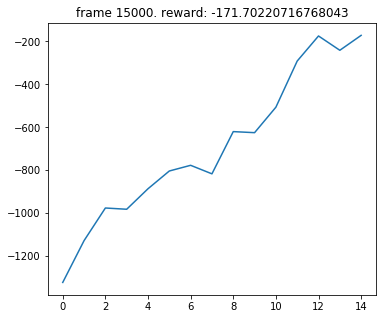
My result from what you suggested! It really improves the performance from -1000 to -171 !
In GAIL, I tested this hyper parameters and this seems to work a lot more consistently: a2c_hidden_size = 32 discrim_hidden_size = 128 lr = 1e-3 num_steps = 128 mini_batch_size = 256 ppo_epochs = 30 threshold_reward = -200
So, I tested a large number of hyper parameters and this seems to work a lot more consistently:
hidden_size = 32 lr = 1e-3 num_steps = 128 mini_batch_size = 256 ppo_epochs = 30and make sure to remove/comment out
self.apply(init_weights)in the neural network description.It still isn't perfect but works better overall.
Lastly I advise updating ppo_iter to this:
def ppo_iter(mini_batch_size, states, actions, log_probs, returns, advantage): batch_size = states.size(0) ids = np.random.permutation(batch_size) ids = np.split(ids[:batch_size // mini_batch_size * mini_batch_size], batch_size // mini_batch_size) for i in range(len(ids)): yield states[ids[i], :], actions[ids[i], :], log_probs[ids[i], :], returns[ids[i], :], advantage[ids[i], :]
Is it not better to use ids = np.array_split(ids,batch_size //mini_batch_size) instead of ids = np.split(ids[:batch_size // mini_batch_size * mini_batch_size], batch_size // mini_batch_size) to avoid wasting the remaining part of the batch, if the division batch_size //mini_batch_size has a remainder? The code would be more general I guess