google-images-download
 google-images-download copied to clipboard
google-images-download copied to clipboard
Fixed issue with links not being found
Google recently changed the way they present the image data, and so the links were no longer being scraped. I figured out how to get the image urls with the new system and made the appropriate changes so it would work.
Unfortunately, google no longer provides file format data so I had to try and retrieve it from the url of the image, which does not work in some cases.
EDIT: Since this keeps being asked, here's the code to download the patch for windows:
git clone https://github.com/Joeclinton1/google-images-download.git
cd google-images-download && python setup.py install
Seems like this will only get the first 100 images, correct? The rest of the images get dynamically loaded through the batch execute call.
Sorry, I wasn't downloading more than 100, so I didn't think about this. I have not tested if this works with above 100, but my guess is it will not.
However, I know the below 100 does not work without these changes.
cool, well 100 is much better than 0 :)
On Wed, Feb 5, 2020 at 3:31 PM Joe Clinton [email protected] wrote:
Seems like this will only get the first 100 images, correct? The rest of the images get dynamically loaded through the batch execute call.
Sorry, I wasn't downloading more than 100, so I didn't think about this. I have not tested if this works with above 100, but my guess is it will not.
— You are receiving this because you commented. Reply to this email directly, view it on GitHub https://github.com/hardikvasa/google-images-download/pull/298?email_source=notifications&email_token=ANEQBTLQ4B477L5555465TTRBND4XA5CNFSM4KQTN5ZKYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEK5LZ6Y#issuecomment-582663419, or unsubscribe https://github.com/notifications/unsubscribe-auth/ANEQBTJTRZPLUTUBB3YYNGDRBND4XANCNFSM4KQTN5ZA .
I got everytime this error after circa 20 downloaded images. I tried from command line and with a python file
Traceback (most recent call last):
File "/home/user/.local/bin/googleimagesdownload", line 11, in
Hey, Much like MarlonHie, I have also received the same error. Could you please advise? It keeps saying NoneType object is not subscriptable. Thanks,
I made a quick fix for the NoneType error. I was working on a project using this so I needed it to work again rapidly. Still working only under 100 images though.
https://github.com/Joeclinton1/google-images-download/pull/1
Sorry, for not replying faster, the none-type thing is because every so often a item with a null value for the image data is given. Fortunately, all of these items are marked with 2 in the data[0] column, so I will just remove them. This should fix the problem. Rian-T's solution also works.
I am still getting these errors with the latest Joeclinton1 version:
File "google_images_download.py", line 1017, in
Doesn't seem to work with more than 100 photos, I attempted with 1000 and it gave me this.

edit: Oops, read a little bit closer and that's a known issue
I ran with 20 queries and some returns this exception:
Traceback (most recent call last):
File "/home/deploy/curador/venv/lib/python3.6/site-packages/celery/app/trace.py", line 385, in trace_task
R = retval = fun(*args, **kwargs)
File "/home/deploy/curador/venv/lib/python3.6/site-packages/celery/app/trace.py", line 648, in __protected_call__
return self.run(*args, **kwargs)
File "/home/deploy/curador/releases/20200201133617/apps/ean/tasks.py", line 14, in download_image
cmd.download()
File "/home/deploy/curador/releases/20200201133617/apps/ean/domain/googleimages.py", line 32, in download
response.download(config_dict)
File "/home/deploy/curador/venv/lib/python3.6/site-packages/google_images_download/google_images_download.py", line 838, in download
paths, errors = self.download_executor(arguments)
File "/home/deploy/curador/venv/lib/python3.6/site-packages/google_images_download/google_images_download.py", line 965, in download_executor
items,errorCount,abs_path = self._get_all_items(raw_html,main_directory,dir_name,limit,arguments) #get all image items and download images
File "/home/deploy/curador/venv/lib/python3.6/site-packages/google_images_download/google_images_download.py", line 768, in _get_all_items
image_objects = self._get_image_objects(page)
File "/home/deploy/curador/venv/lib/python3.6/site-packages/google_images_download/google_images_download.py", line 758, in _get_image_objects
image_objects = json.loads(object_decode)[31][0][12][2]
IndexError: list index out of range
Hi all,
For time being the probable fix is to add image downloader extension to your chrome browser (https://chrome.google.com/webstore/detail/image-downloader/cnpniohnfphhjihaiiggeabnkjhpaldj?hl=en-US). I am working to fix the issue, will give an update shortly.
Thanks.
I believe the solution I have is too inflexible for deployment, as google does not seem to keep a stable enough structure to the databack send in the callback. A different solution, perhaps one which collects links which are not thumbnails inside the callback might work better.
I've been trying to get limit > 100 to work. It seems selenium's browser.page_source returns lots of new lines compared to the other raw_html you typically get. I've tried stripping newlines off, but no success. Eventually it will search for: "AF_initDataCallback({key: \'ds:2\'" but returns -1. If I search just "AF_initDataCallback" I can get a start index, but this will still just result in JSONDecodeError. So it seems the entire raw_html from download_extended_page is getting parsed incorrectly.
EDIT: Converting the string to a bytearray and back to a string allowed the image_objects to parse correctly. len(image_objects) was only 100 though so maybe selenium isn't scrolling far down enough? Will keep looking...
EDIT2: It seems my string from download_extended_page is larger, but object length staying at 100. Running with short length vs length > 100, the delta between the start and stop indexes is ~122400 for both raw_html after parsing. So no new images seem to be actually included with the expanded page_source despite it being a larger string.
I was using this fix last week, but it seems like things have changed again? Anyone else experiencing this?
python3 google_scraper.py -k "test"
Item no.: 1 --> Item name = test
Evaluating...
Starting Download...
Traceback (most recent call last):
File "google_scraper.py", line 1022, in <module>
main()
File "google_scraper.py", line 1011, in main
paths,errors = response.download(arguments) #wrapping response in a variable just for consistency
File "google_scraper.py", line 847, in download
paths, errors = self.download_executor(arguments)
File "google_scraper.py", line 965, in download_executor
items,errorCount,abs_path = self._get_all_items(raw_html,main_directory,dir_name,limit,arguments) #get all image items and download images
File "google_scraper.py", line 768, in _get_all_items
image_objects = self._get_image_objects(page)
File "google_scraper.py", line 758, in _get_image_objects
image_objects = json.loads(object_decode)[31][0][12][2]
File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/json/__init__.py", line 357, in loads
return _default_decoder.decode(s)
File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/json/decoder.py", line 337, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/json/decoder.py", line 355, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
I was using this fix last week, but it seems like things have changed again? Anyone else experiencing this?
python3 google_scraper.py -k "test"Item no.: 1 --> Item name = test Evaluating... Starting Download... Traceback (most recent call last): File "google_scraper.py", line 1022, in <module> main() File "google_scraper.py", line 1011, in main paths,errors = response.download(arguments) #wrapping response in a variable just for consistency File "google_scraper.py", line 847, in download paths, errors = self.download_executor(arguments) File "google_scraper.py", line 965, in download_executor items,errorCount,abs_path = self._get_all_items(raw_html,main_directory,dir_name,limit,arguments) #get all image items and download images File "google_scraper.py", line 768, in _get_all_items image_objects = self._get_image_objects(page) File "google_scraper.py", line 758, in _get_image_objects image_objects = json.loads(object_decode)[31][0][12][2] File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/json/__init__.py", line 357, in loads return _default_decoder.decode(s) File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/json/decoder.py", line 337, in decode obj, end = self.raw_decode(s, idx=_w(s, 0).end()) File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/json/decoder.py", line 355, in raw_decode raise JSONDecodeError("Expecting value", s, err.value) from None
Me too, have you solved it?
I was using this fix last week, but it seems like things have changed again? Anyone else experiencing this?
python3 google_scraper.py -k "test"Item no.: 1 --> Item name = test Evaluating... Starting Download... Traceback (most recent call last): File "google_scraper.py", line 1022, in <module> main() File "google_scraper.py", line 1011, in main paths,errors = response.download(arguments) #wrapping response in a variable just for consistency File "google_scraper.py", line 847, in download paths, errors = self.download_executor(arguments) File "google_scraper.py", line 965, in download_executor items,errorCount,abs_path = self._get_all_items(raw_html,main_directory,dir_name,limit,arguments) #get all image items and download images File "google_scraper.py", line 768, in _get_all_items image_objects = self._get_image_objects(page) File "google_scraper.py", line 758, in _get_image_objects image_objects = json.loads(object_decode)[31][0][12][2] File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/json/__init__.py", line 357, in loads return _default_decoder.decode(s) File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/json/decoder.py", line 337, in decode obj, end = self.raw_decode(s, idx=_w(s, 0).end()) File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/json/decoder.py", line 355, in raw_decode raise JSONDecodeError("Expecting value", s, err.value) from NoneMe too, have you solved it?
try changing: start_line = s.find("AF_initDataCallback({key: 'ds:2'") - 10 to start_line = s.find("AF_initDataCallback({key: 'ds:1'") - 10
@xun-0612 It works for me! Thx a lot! Yesterday I looked for a resource all day. And I do recommend arthursdays's version for who need download more than 100 images at once. He forked another repo by WuLC and modified his download_with_selenium.py to make it work again. There is his pull request.
https://github.com/voins/google-images-download/commit/ef577fc0f7a8558073a9a8bc227fdaca0136b2ab
That fixes the problem with limit > 100, I don't care that much about creating a new pull request. Feel free to use and modify. I believe more elegant solution is quite possible. :)
this work for me.
change the start_line to start_line = s.find("AF_initDataCallback({key: 'ds:1'") - 10
thanks @Joeclinton1 @xun-0612
That fixes the problem with limit > 100, I don't care that much about creating a new pull request. Feel free to use and modify. I believe more elegant solution is quite possible. :)
Hello,I set the limit as 200, and it can run, but it stopped downloading after I have downloaded 100 imgs. So, is the problem with limit > 100 still exist?
voins@ef577fc That fixes the problem with limit > 100, I don't care that much about creating a new pull request. Feel free to use and modify. I believe more elegant solution is quite possible. :)
Hello,I set the limit as 200, and it can run, but it stopped downloading after I have downloaded 100 imgs. So, is the problem with limit > 100 still exist?
Sorry, my fix revealed the next problem and I have not tested it thoroughly. I'm trying to find out what could be done, but I don't have much time.
If anyone is working on that too: the problem is the page source doesn't have the whole set any more, it has only first 100 items and everything else gets there via ajax request. It is possible to intercept those, but I didn't have time to verify this technique yet.
Ok. New attempt. :) https://github.com/voins/google-images-download/commit/7db9a4608f584ae6925e3ebff001579dce284b39
It fetches up to 400 links from google by intercepting ajax requests. Anything more than 400 requires some more selenium magic to press the "Load More Images" button if needed.
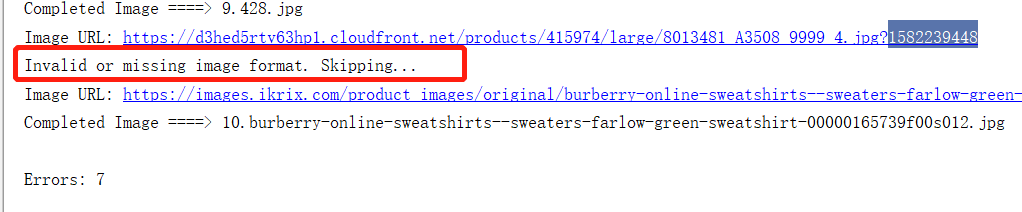
I'm investigating why there's so much "Invalid or missing image format." errors and what's possible to do about it. Feel free to join.
https://github.com/voins/google-images-download/commit/2cd68173c961324a2c41c61e8b6f40a49663ce60 And now we don't trust file extension from URL, but use Content-Type instead. It works good enough for me, so I probably won't change anything else. Feel free to grab, merge, whatever
voins@2cd6817 And now we don't trust file extension from URL, but use Content-Type instead. It works good enough for me, so I probably won't change anything else. Feel free to grab, merge, whatever
You are hardworking!I have changed my code to your version. It still works for limit >100, but just download <100 imgs not >100... Have you downloaded >100 imgs?
You are hardworking!I have changed my code to your version. It still works for limit >100, but just download <100 imgs not >100... Have you downloaded >100 imgs?
Yes, it works for me. Look for error messages. It's really hard to say anything without any information.
That's great! Today it's really OK for me to download more than 100 imgs. Yesterday it said, Unfortunately all 500 could not be downloaded because some images were not downloadable. 72/92 is all we got for this search filter! I just tried 2 times and got 72/92 imgs with the limit 500. Maybe it' was affected by the Internet, but I don't understand why it also downloaded 72/92 imgs not 0. But anyway, it do well now. THX!