Run JAX on multi-host platforms (such as TPUs)
Hi,
I currently try to run my program (which initially works on a Cloud TPU v2-8/v3-8) on a Cloud TPU v2-32 which has 4 hosts by using JAX (jax==0.1.65, jaxlib==0.1.45). However, I encountered an issue which shows "Cannot replicate across 32 replicas because only 8 local devices are available. (local devices = TPU_0(host=0,(0,0,0,0)), TPU_1(host=0,(0,0,0,1)), TPU_2(host=0,(1,0,0,0)), TPU_3(host=0,(1,0,0,1)), TPU_8(host=0,(0,1,0,0)), TPU_9(host=0,(0,1,0,1)), TPU_10(host=0,(1,1,0,0)), TPU_11(host=0,(1,1,0,1)))" if I did not specify devices in a same host for pmap. In addition, if I successfully partition an array across multiple TPU cores which do not necessarily belong to a same host, can I still use lax.ppermute to perform a collective permutation and exchange sub-arrays across different cores?
Thank you for the reply in advance.
Unfortunately, there is not yet support for using cloud TPUs on multiple hosts in JAX.
I believe there is (very preliminary, untested, subject to change) multi-host Cloud TPU support, and what you describe is maybe one or two steps away from a recipe that should work! Try the following and let us know how it goes:
- Start a Cloud TPU slice using the
tpu_driver_nightlyversion - Get the full list of host IPs:
import cloud_tpu_client
tpu_name = <your-tpu-name>
ctc = cloud_tpu_client.client.Client(tpu_name)
endpoints = ctc.network_endpoints()
for endpoint in endpoints:
print(endpoint['ipAddress'])
- Run separate Python programs targeting each of these IPs:
python3 file.py --jax_xla_backend=tpu_driver --jax_backend_target=grpc://<tpu1-ip>:8470
- If you launch Python programs like that that collectively target all the IPs (whether from one client VM or several; it's up to you), and wait for all of them to start up,
jax.host_count()should return the total number of connected TPU hosts,jax.devices()should return all devices across the slice, andpmapshould use all of them by default.
Note that ppermute is untested in multi-host pmap (and currently disabled pending adding such tests), but you can enable it by patching out the assertion.
Hi @jekbradbury ,
I got the IPs for the cloud TPU v2-32 on GCP as follows:
10.230.196.132
10.230.196.130
10.230.196.133
10.230.196.131
Then, I ran the command
python3 file.py --jax_xla_backend=tpu_driver --jax_backend_target=grpc://10.230.196.132:8470
It's just a small test in "file.py" with
out = pmap(lambda x: x ** 2)(np.arange(8))
print(out)
However, I got the error messages:
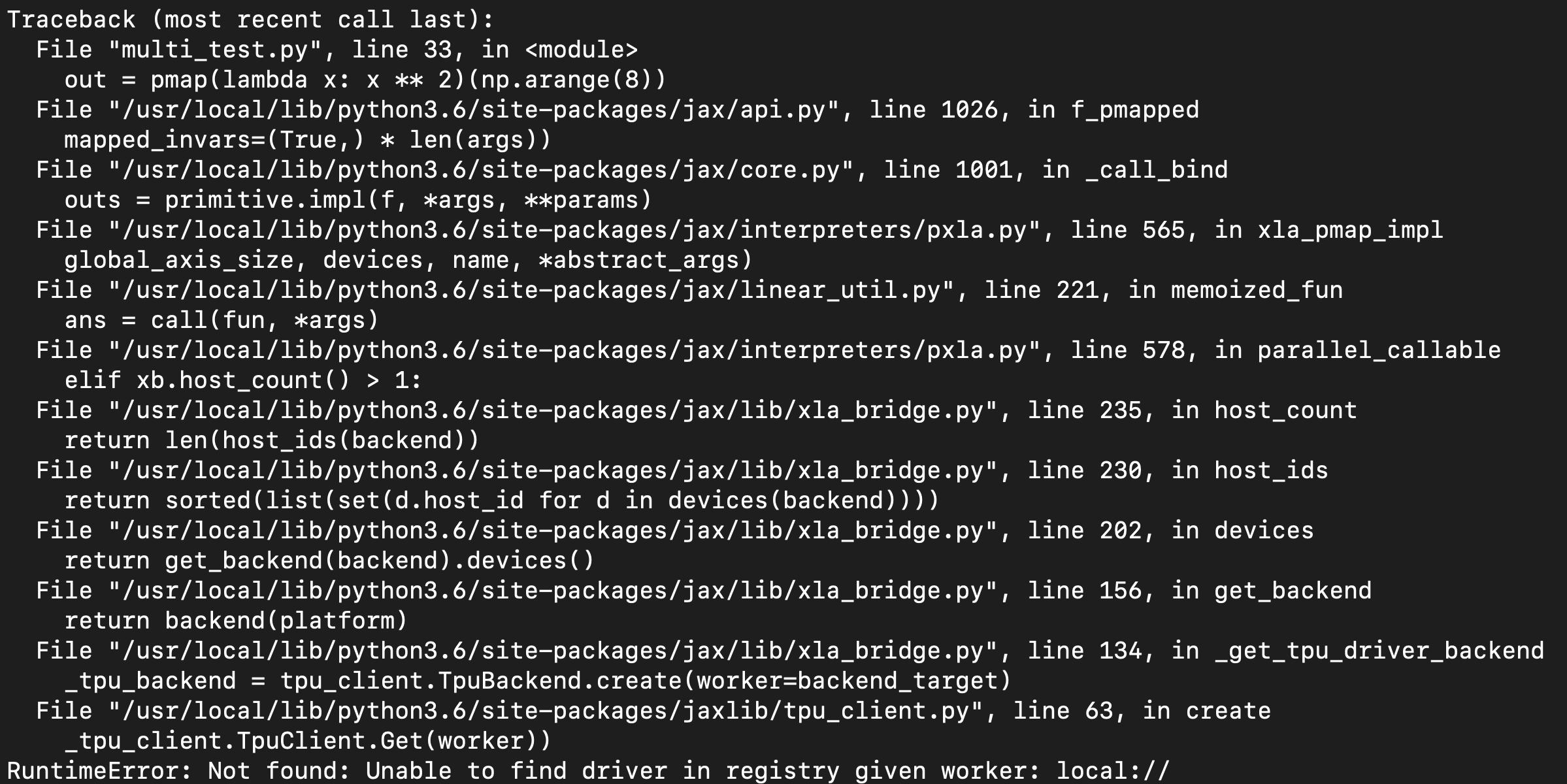
Then, I specified target IP in "file.py" by
config.FLAGS.jax_backend_target = "grpc://10.230.196.132:8470" # or using other ipAddress
However, the warning showed up and never finished the program.
2020-05-13 20:53:37.746194: W external/org_tensorflow/tensorflow/compiler/xla/python/tpu_driver/client/tpu_client.cc:601] TPU Execute is taking a long time. This might be due to a deadlock between multiple TPU cores or a very slow program.
Just to confirm, you're running four separate Python processes with the four different IP addresses right?
You should also set config.FLAGS.jax_xla_backend = "tpu_driver" if you're not already. (I'm not sure why specifying these on the commandline isn't working. There's probably still something wrong with how we're using absl flags, but let's worry about that later).
Can you try printing jax.devices() and/or jax.device_count() before running the pmap, but after setting config.FLAGS.jax_backend_target? You should see 32 TPU devices.
You you could also try bumping up the logging, although I don't know if we expect anything useful in there. I think the env var TF_CPP_MIN_LOG_LEVEL=0 should set it to INFO.
cc @henrytansetiawan
Thank you for the troubleshooting. Following the steps you mentioned I am able to use pmap collectively for all of the TPU hosts I have.
Glad to hear it! Please let us know if you run into anything else, or have questions or suggestions!
Actually, did you already get ppermute working too? Feel free to open a new issue for that, or reopen this one, if you need help with that.
I haven't got ppermute working yet but I am testing it for my simulation. I will share some results or reopen this issue later if I bump into some problems. Thank you very much.
I created a simple test for ppermute on multi-host pmap with Cloud TPU v2-32.
The layout of TPU cores is as follows:
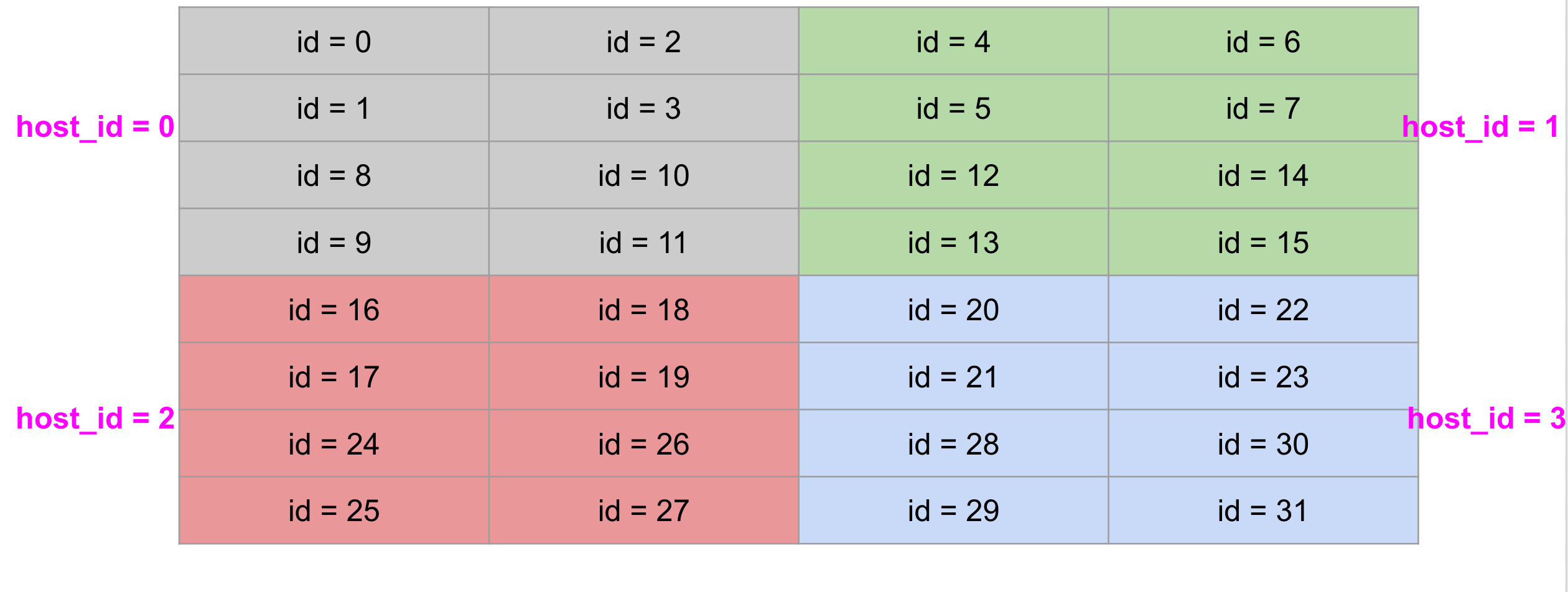 The permutation operation is to send data from a device to its neighbor device. It works well for a single host. For multi-host implementation, each host has a jax.numpy array which is split into 8 chunks and "pmapped" onto its eight local cores/devices to perform collective permutation across multiple hosts (with 32 devices).
If we have a virtual data in global view as follows:
The permutation operation is to send data from a device to its neighbor device. It works well for a single host. For multi-host implementation, each host has a jax.numpy array which is split into 8 chunks and "pmapped" onto its eight local cores/devices to perform collective permutation across multiple hosts (with 32 devices).
If we have a virtual data in global view as follows:
Therefore, the permutation lists of pairs can be expressed by the following code
perms_host0 = [(0, 1), (1, 2), (2, 3), (3, 8), (8, 9), (9, 10), (10, 11), (11, 4)]
perms_host1 = [(4, 5), (5, 6), (6, 7), (7, 12), (12, 13), (13, 14), (14, 15), (15, 16)]
perms_host2 = [(16, 17), (17, 18), (18, 19), (19, 24), (24, 25), (25, 26), (26, 27), (27, 20)]
perms_host3 = [(20, 21), (21, 22), (22, 23), (23, 28), (28, 29), (29, 30), (30, 31)]
I tried to modify the source code for ppermute, but it's still not working.
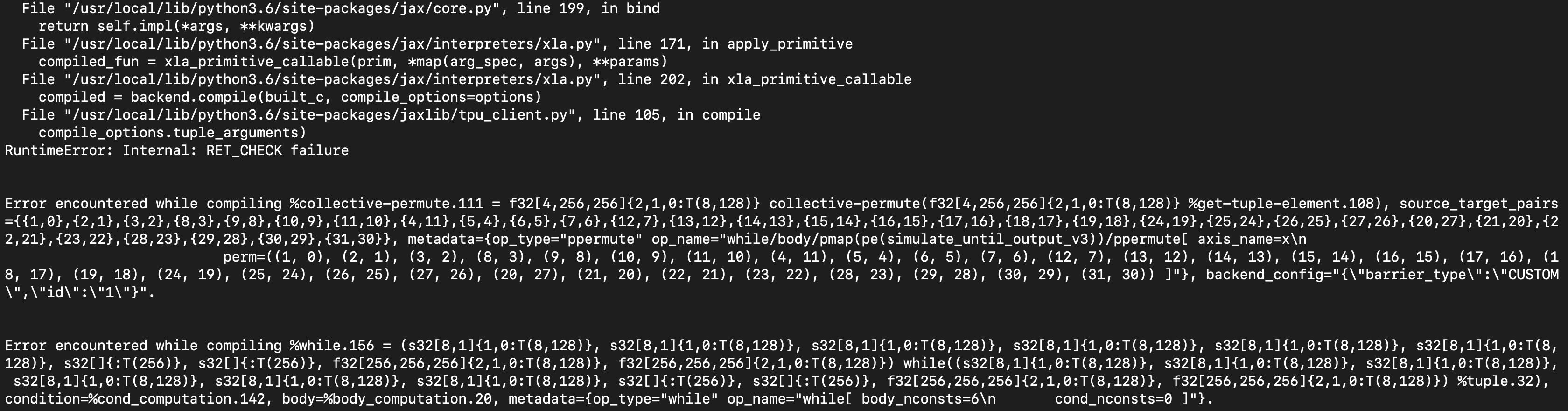 I am not sure if I misunderstood the multi-host pmap implementation. Thanks.
I am not sure if I misunderstood the multi-host pmap implementation. Thanks.
I think you're close! Everything you're saying sounds right. I think your issue is that on each host, you're only providing that host's list of permutations to ppermute. You should actually provide all 32 permutations to ppermute, i.e. each host runs exactly the same ppermute call.
One wrinkle is that I'm not 100% sure if the ppermute indices will line up the way you expect with the TPU device IDs. I've been meaning to try it out and fix it if they don't, but in the meantime, you could run a simple shift ppermute like you have above and observe where the different values end up. If they do end up in unexpected order, let me know and I can work on a fix.
BTW, you may find pshuffle more convenient. We must have forgotten to add this function to our documentation, it's just a simple wrapper over ppermute.
Separately, it looks like you're running pmap inside an op-by-op while_loop; that might not work very well right now, especially on multi-host. It's probably easiest to use multi-host pmap only at the top level of your JAX program right now—device code outside of it will need to collect arrays back to one core per host, if that makes sense.
I just looked at your stacktrace more carefully, and it looks like you're already providing the full permutation list, but you have something like while_loop(pmap(ppermute)). I don't expect a while_loop containing a pmap to work correctly. Can you put the pmap around the while_loop instead, or even better, use a regular Python while-loop?
Another thought: be very careful running a ppermute inside a while_loop, because if different hosts end up with different trip counts, your outer pmap will hang or return incorrect results. All hosts are expected to run the same collectives in the same order. This will also apply if you switch to a regular Python while-loop containing the pmap, since each host may end up executing a different number of pmaps.
Ideally we'd signal an error in this situation instead of hanging or returning bad data, but either way, you should be very careful to ensure each host runs the loop the same number of times. You can potentially use pmap to communicate the trip count before starting the loop and ensure all hosts have the same count, if this isn't guaranteed some other way.
Note that "the same collectives" also includes the same shapes! I haven't worked with MPI much, but I think it's a pretty similar situation if that's something you're familiar with.
Thanks for the reply. I also tried to provide all 31 permutations to ppermute and rewrite _ppermute_translation_rule function in lax_parallel.py from
def _ppermute_translation_rule(c, x, replica_groups, perm, platform=None):
group_size = len(replica_groups[0])
srcs, dsts = unzip2((src % group_size, dst % group_size) for src, dst in perm)
if not (len(srcs) == len(set(srcs)) and len(dsts) == len(set(dsts))):
msg = "ppermute sources and destinations must be unique, got {}."
raise ValueError(msg.format(perm))
full_perm = []
for grp in replica_groups: # [0, 1, 2, 3, 4, 5, 6, 7] for every host
grp = list(sorted(grp))
full_perm.extend((grp[src], grp[dst]) for src, dst in perm)
return xops.CollectivePermute(x, full_perm)
to
def _ppermute_translation_rule(c, x, replica_groups, perm, platform=None):
# perm is a list of 32 permutation for all four hosts
group_size = len(replica_groups[0]) # = 8
return xops.CollectivePermute(x, perm)
However, I still got the same error messages.
Are you possibly missing a data dependence from the input of the pmap to the ppermute? If you're getting the same stack trace that includes apply_primitive, it may mean the ppermute isn't coming into contact with a pmap tracer. (@mattjj is working on lifting this data dependence requirement!)
Hello, Can JAX support multi-host GPUs? If so, and how to do the configuration?
I believe there is (very preliminary, untested, subject to change) multi-host Cloud TPU support, and what you describe is maybe one or two steps away from a recipe that should work! Try the following and let us know how it goes:
- Start a Cloud TPU slice using the
tpu_driver_nightlyversion- Get the full list of host IPs:
import cloud_tpu_client tpu_name = <your-tpu-name> ctc = cloud_tpu_client.client.Client(tpu_name) endpoints = ctc.network_endpoints() for endpoint in endpoints: print(endpoint['ipAddress'])
- Run separate Python programs targeting each of these IPs:
python3 file.py --jax_xla_backend=tpu_driver --jax_backend_target=grpc://<tpu1-ip>:8470
- If you launch Python programs like that that collectively target all the IPs (whether from one client VM or several; it's up to you), and wait for all of them to start up,
jax.host_count()should return the total number of connected TPU hosts,jax.devices()should return all devices across the slice, andpmapshould use all of them by default.Note that
ppermuteis untested in multi-hostpmap(and currently disabled pending adding such tests), but you can enable it by patching out the assertion.
Hello jekbradbury, I want to run jax in multi-host GPU clusters. I am wondering whether JAX support it currently, it seems that JAX only support multi-host TPU clusters now.
@yxd886 Multi-host for GPUs was added recently. Here's the documentation: https://jax.readthedocs.io/en/latest/multi_process.html#initializing-the-cluster. Feel free to start a new thread if you're still facing issues.