codeql
 codeql copied to clipboard
codeql copied to clipboard
Python dataflow: flow summaries restart
This demonstrates that flow summaries can be based on API graphs and all our existing tests can pass 🎉
I have trimmed down the changes needed to get to this state, and given detailed explanations of the tricky transformations needed to avoid non-monotonic recursion.
For a moment, the commit history was beautiful.
Then main moved on and more changes needed to be made, now it is a bit longer and more hairy.
Also, there is a branch where it is even more hairy, cutting up some of the inheritance hierarchies in order to achieve
SourceParameterNode extends LocalSourceNode, but I suggest we leave that for now. SourceParameterNode is no longer something non-internal development should be concerned about.
Names have become a bite nicer and the impact on user code and on .expected-files has been minimised.
We might still do more test, showing off the capabilities, especially the use from MaD which is not demonstrated at the moment. However, simply having it compile and the basic tests pass seems like a worthy milestone at this point.
I've only done a superficial glance at this, but I'd like to talk about the issue with getACall2. This is a fundamental issue when using API graphs and flow summaries together, and will likely affect all dynamic languages attempting to use flow summaries. I'd like to get a bit more clarity on what the problem is and what solution to use (ideally we'll all end up using the same solution).
The root of the problem is that the following cycle is created between call graph construction and API graphs:
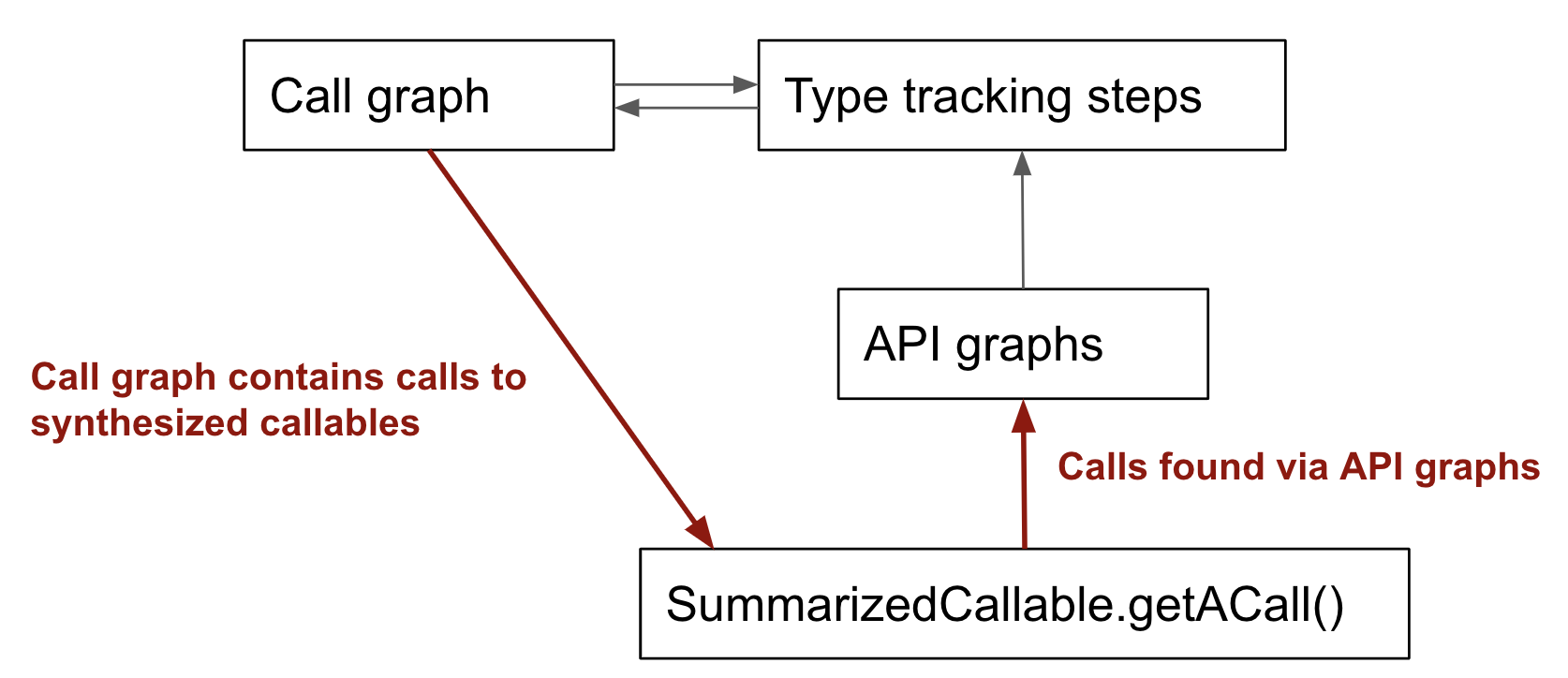
Unless we want API graphs to be mutually recursive with type-tracking steps and call construction, we'll need to break the cycle somehow. As far as I can tell, you've broken the cycle like this:
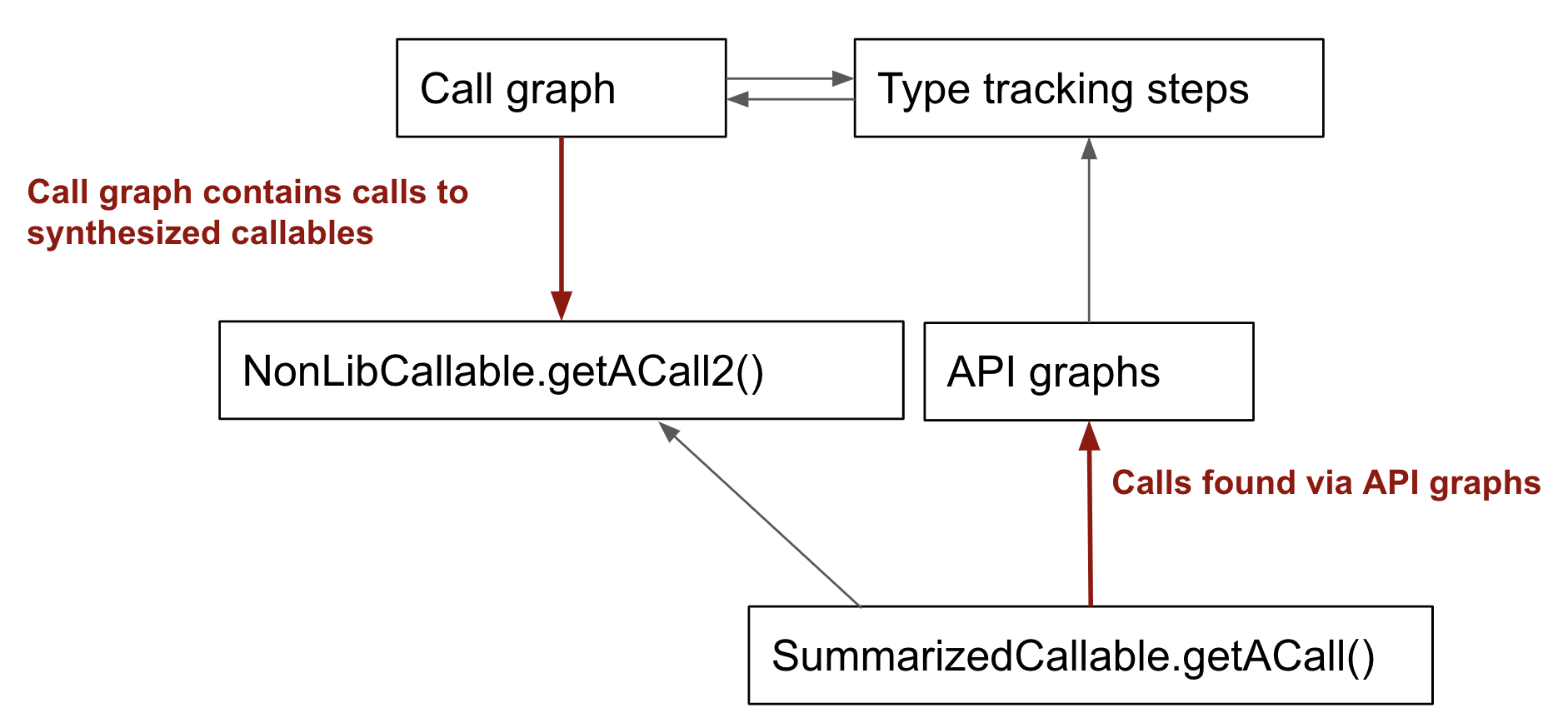
This means anything not depending on API graphs can contribute to getACall2, and things depending on API graphs can use getACall. Type tracking steps will only be discovered for getACall2, which makes it more suitable for things like standard library modelling.
I believe Ruby's solution so far is to make type-tracking steps explicitly depend on non-library callables only. The downside here is that none of their standard library models are visible to type-tracking. (@hvitved @aibaars do you agree here?)
@yoff Since I'm unfamiliar with the Python libraries I'm not 100% sure my interpretation above is an accurate description of what you've done here. Could you please check if this is the case? If so, I think it's a fine solution provided we can come up with names that aren't confusing.
Force pushed because I could see that my amended commit message to the last commit had not been pushed.
I believe Ruby's solution so far is to make type-tracking steps explicitly depend on non-library callables only. The downside here is that none of their standard library models are visible to type-tracking. (@hvitved @aibaars do you agree here?)
Correct (since flow summaries depend on API graphs, which depend on type tracking).
The diagram looks correct to me. Is the difference with Ruby just that we have not (yet?) written any standard library models using flow summaries? Or is there a more fundamental difference?
The failing language test belongs to https://github.com/github/semmle-code and cannot be fixed in this PR (I believe the fix is simply to update the test expectations).
A few drive-by comments. Is the logic actually hooked up yet? I fail to see references to e.g. any of the
FlowSummaryImpl::Private::Stepspredicates. See e.g.DataFlowPrivate.qllfor ruby for how this is done.
They are mostly in DataFlowPrivate.qll and then one in DataFlowUtil.qll. I followed the structure from Ruby closely. The interface does not let you search for these terms inside collapsed files, which is a bit misleading.
They are mostly in
DataFlowPrivate.qlland then one inDataFlowUtil.qll. I followed the structure from Ruby closely. The interface does not let you search for these terms inside collapsed files, which is a bit misleading.
Ah, good, sorry for the false alarm. I guess I must have looked at a diff limited to a subset of commits perhaps.
I think in terms of the implementation, this looks pretty solid. I've added a bunch of requests for clarification (and also some requests for renaming stuff). I'll be very happy to discuss this synchronously if that's easier. 🙂
Thank you for the review. I think both renaming and qldocs are warranted. Specifically, when classes are split (in order to only have one participate in a recursion that would otherwise be non-monotonic) the user-facing one should be retaining the old name so as to minimise breaking changes.
General comments:
Can we add ONE production flow-summary? For example for the builtin
reversed-- just to see where it would go, and how it looks 😊
I put it in frameworks\Builtins.qll. It could also go in the StdLib folder, I guess. Or perhaps you have a different place that you find natural, feel free to suggest :-)