blog
 blog copied to clipboard
blog copied to clipboard
大公司里怎样开发和部署前端代码?
本文搬运自我在知乎上 同名问题 中的答案。
这是一个非常有趣的 非主流前端领域,这个领域要探索的是如何用工程手段解决前端开发和部署优化的综合问题,入行到现在一直在学习和实践中。
在我的印象中,facebook是这个领域的鼻祖,有兴趣、有梯子的同学可以去看看facebook的页面源代码,体会一下什么叫工程化。
接下来,我想从原理展开讲述,多图,较长,希望能有耐心看完。
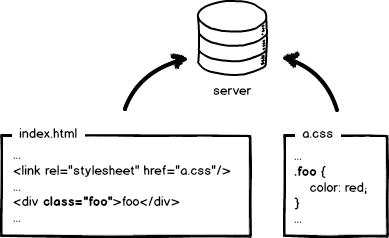
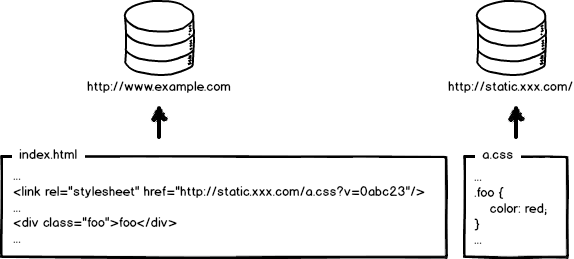
让我们返璞归真,从原始的前端开发讲起。上图是一个“可爱”的index.html页面和它的样式文件a.css,用文本编辑器写代码,无需编译,本地预览,确认OK,丢到服务器,等待用户访问。前端就是这么简单,好好玩啊,门槛好低啊,分分钟学会有木有!
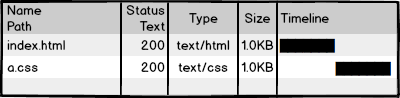
然后我们访问页面,看到效果,再查看一下网络请求,200!不错,太™完美了!那么,研发完成。。。。了么?
等等,这还没完呢!对于大公司来说,那些变态的访问量和性能指标,将会让前端一点也不“好玩”。
看看那个a.css的请求吧,如果每次用户访问页面都要加载,是不是很影响性能,很浪费带宽啊,我们希望最好这样:

利用304,让浏览器使用本地缓存。但,这样也就够了吗?不成!304叫协商缓存,这玩意还是要和服务器通信一次,我们的优化级别是变态级,所以必须彻底灭掉这个请求,变成这样:

强制浏览器使用本地缓存(cache-control/expires),不要和服务器通信。好了,请求方面的优化已经达到变态级别,那问题来了:你都不让浏览器发资源请求了,这缓存咋更新?
很好,相信有人想到了办法:通过更新页面中引用的资源路径,让浏览器主动放弃缓存,加载新资源。好像这样:

下次上线,把链接地址改成新的版本,就更新资源了不是。OK,问题解决了么?!当然没有!大公司的变态又来了,思考这种情况:
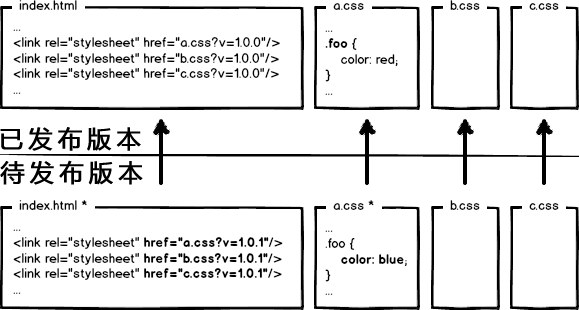
页面引用了3个css,而某次上线只改了其中的a.css,如果所有链接都更新版本,就会导致b.css,c.css的缓存也失效,那岂不是又有浪费了?!
重新开启变态模式,我们不难发现,要解决这种问题,必须让url的修改与文件内容关联,也就是说,只有文件内容变化,才会导致相应url的变更,从而实现文件级别的精确缓存控制。
什么东西与文件内容相关呢?我们会很自然的联想到利用 数据摘要算法 对文件求摘要信息,摘要信息与文件内容一一对应,就有了一种可以精确到单个文件粒度的缓存控制依据了。好了,我们把url改成带摘要信息的:
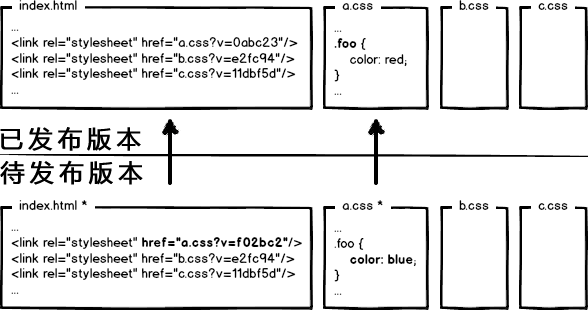
这回再有文件修改,就只更新那个文件对应的url了,想到这里貌似很完美了。你觉得这就够了么?大公司告诉你:图样图森破!
唉~~~~,让我喘口气
现代互联网企业,为了进一步提升网站性能,会把静态资源和动态网页分集群部署,静态资源会被部署到CDN节点上,网页中引用的资源也会变成对应的部署路径:
好了,当我要更新静态资源的时候,同时也会更新html中的引用吧,就好像这样:
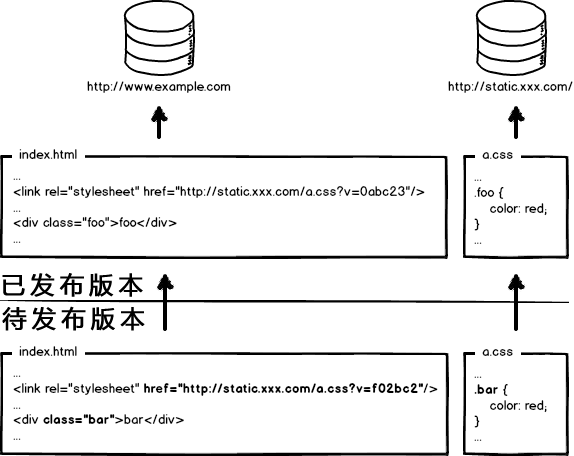
这次发布,同时改了页面结构和样式,也更新了静态资源对应的url地址,现在要发布代码上线,亲爱的前端研发同学,你来告诉我,咱们是先上线页面,还是先上线静态资源?
先部署页面,再部署资源:在二者部署的时间间隔内,如果有用户访问页面,就会在新的页面结构中加载旧的资源,并且把这个旧版本的资源当做新版本缓存起来,其结果就是:用户访问到了一个样式错乱的页面,除非手动刷新,否则在资源缓存过期之前,页面会一直执行错误。先部署资源,再部署页面:在部署时间间隔之内,有旧版本资源本地缓存的用户访问网站,由于请求的页面是旧版本的,资源引用没有改变,浏览器将直接使用本地缓存,这种情况下页面展现正常;但没有本地缓存或者缓存过期的用户访问网站,就会出现旧版本页面加载新版本资源的情况,导致页面执行错误,但当页面完成部署,这部分用户再次访问页面又会恢复正常了。 好的,上面一坨分析想说的就是:先部署谁都不成!都会导致部署过程中发生页面错乱的问题。所以,访问量不大的项目,可以让研发同学苦逼一把,等到半夜偷偷上线,先上静态资源,再部署页面,看起来问题少一些。
但是,大公司超变态,没有这样的“绝对低峰期”,只有“相对低峰期”。So,为了稳定的服务,还得继续追求极致啊!
这个奇葩问题,起源于资源的 覆盖式发布,用 待发布资源 覆盖 已发布资源,就有这种问题。解决它也好办,就是实现 非覆盖式发布。
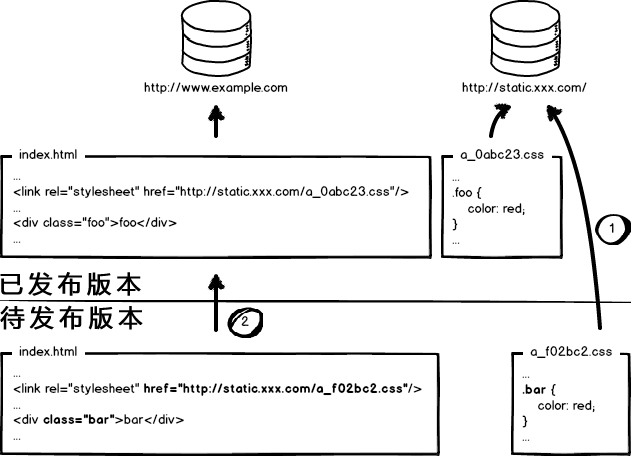
看上图,用文件的摘要信息来对资源文件进行重命名,把摘要信息放到资源文件发布路径中,这样,内容有修改的资源就变成了一个新的文件发布到线上,不会覆盖已有的资源文件。上线过程中,先全量部署静态资源,再灰度部署页面,整个问题就比较完美的解决了。
所以,大公司的静态资源优化方案,基本上要实现这么几个东西:
- 配置超长时间的本地缓存 —— 节省带宽,提高性能
- 采用内容摘要作为缓存更新依据 —— 精确的缓存控制
- 静态资源CDN部署 —— 优化网络请求
- 更资源发布路径实现非覆盖式发布 —— 平滑升级
全套做下来,就是相对比较完整的静态资源缓存控制方案了,而且,还要注意的是,静态资源的缓存控制要求在 前端所有静态资源加载的位置都要做这样的处理 。是的,所有!什么js、css自不必说,还要包括js、css文件中引用的资源路径,由于涉及到摘要信息,引用资源的摘要信息也会引起引用文件本身的内容改变,从而形成级联的摘要变化,大概示意图就是:
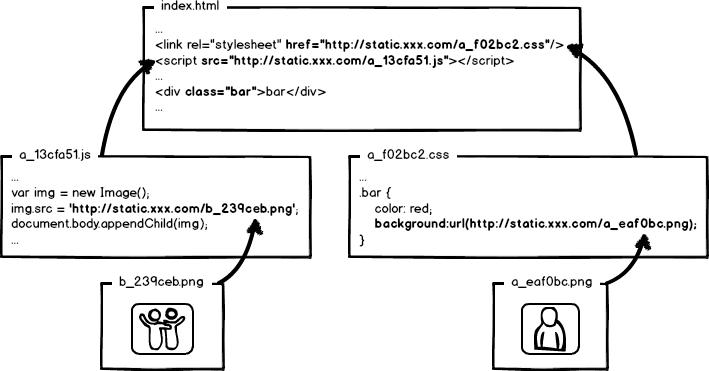
好了,目前我们快速的学习了一下前端工程中关于静态资源缓存要面临的优化和部署问题,新的问题又来了:这™让工程师怎么写码啊!!!
要解释优化与工程的结合处理思路,又会扯出一堆有关模块化开发、资源加载、请求合并、前端框架等等的工程问题,以上只是开了个头,解决方案才是精髓,但要说的太多太多,有空再慢慢展开吧。
总之,前端性能优化绝逼是一个工程问题!
以上不是我YY的,可以观察 百度 或者 facebook 的页面以及静态资源源代码,查看它们的资源引用路径处理,以及网络请中静态资源的缓存控制部分。再次赞叹facebook的前端工程建设水平,跪舔了。
建议前端工程师多多关注前端工程领域,也许有人会觉得自己的产品很小,不用这么变态,但很有可能说不定某天你就需要做出这样的改变了。而且,如果我们能把事情做得更极致,为什么不去做呢?
另外,也不要觉得这些是运维或者后端工程师要解决的问题。如果由其他角色来解决,大家总是把自己不关心的问题丢给别人,那么前端工程师的开发过程将受到极大的限制,这种情况甚至在某些大公司都不少见!
妈妈,我再也不玩前端了。。。。5555
业界实践
Assets Pipeline
Rails中的Assets Pipeline完成了以上所说的优化细节,对整个静态资源的管理上的设计思考也是如此,了解rails的人也可以把此答案当做是对rails中assets pipeline设计原理的分析。
rails通过把静态资源变成erb模板文件,然后加入<%= asset_path 'image.png' %>,上线前预编译完成处理,fis的实现思路跟这个几乎完全一样,但我们当初确实不知道有rails的这套方案存在。
相关资料:
- 英文版:http://guides.rubyonrails.org/asset_pipeline.html
- 中文版:http://guides.ruby-china.org/asset_pipeline.html
FIS的解决方案
用 F.I.S 包装了一个小工具,完整实现整个回答所说的最佳部署方案,并提供了源码对照,可以感受一下项目源码和部署代码的对照。
- 源码项目:https://github.com/fouber/static-resource-digest-project
- 部署项目:https://github.com/fouber/static-resource-digest-project-release
部署项目可以理解为线上发布后的结果,可以在部署项目里查看所有资源引用的md5化处理。
这个示例也可以用于和assets pipeline做比较。fis没有assets的目录规范约束,而且可以以独立工具的方式组合各种前端开发语言(coffee、less、sass/scss、stylus、markdown、jade、ejs、handlebars等等你能想到的),并与其他后端开发语言结合。
assets pipeline的设计思想值得独立成工具用于前端工程,fis就当做这样的一个选择吧。
@fouber 请教一个问题: 我们项目使用的是PHP开发但模板引擎不是 Smarty。 这种情况如何利用fis帮助我实现检测文件修改后自动更新对应资源路径。
File "src/photo/img.jpg" changed.
Create "src/photo/img_XmsD8daS.jpg" .
Replace :
<img src=\"src/photo/img_8sDuxSma.jpg\" > ==> <img src=\"src/photo/img_XmsD8daS.jpg\" >
background-image:url("src/photo/img_8sDuxSma.jpg") ==> background-image:url("src/photo/img_XmsD8daS.jpg")
Update: http//static.cdn.com/src/photo/img_8sDuxSma.jpg
如何不要求后端做任何修改的情况下完成自动检测修改-复制修改资源并加上md5后缀-更新资源。
@NimoJs
https://github.com/fouber/static-resource-management-system-demo 可以参考一下这个样例,有完整的运行起来的方案
@fouber 感谢指点。今天又尝试了一下 rsd。
我将FIS解决方案理解为“配置”好的FIS项目 当我对FIS的使用和了解足够深入的时候,可以利用FIS定制出最适合自己开发需求的解决方案的?
纯前端开发grunt可以完成绝大部分的工作。(前端组件,纯前端开源项目) 涉及到生成环境时候FIS可以完成很多grunt不能完成的工作。
@NimoJs
你的理解非常非常正确。
前端架构大部分工作要解决的是 如何用工具连接框架和规范的问题。这是一个工程问题。fis想解决的正是规范与框架的链接问题,而不是简单的前端源码构建。
所谓框架,主要指模块化框架,其职责包括对模块化资源的管理和加载,管理包括js/css的依赖管理,加载包括按需加载和请求合并,以及资源缓存与更新。
所谓规范,主要是指开发和部署规范,比如哪些是模块化资源,哪些是非模块化资源,模块化资源如何包装、优化和部署,非模块化资源如何部署等,什么文件发布到什么目录,是否有CDN等等。
框架、规范、工具三者需要紧密配合才能比较完美的解决模块化开发、性能优化等前端工程问题。
fis本身是一种特殊的 “工具”,通过一些比较 “奇怪” 的配置设计,实现了框架与规范的绑定过程。这些问题我觉得是grunt/gulp不曾思考过的。
fis的解决方案,包括你看到的rsd,还有 scrat,其实都是对fis的配置,每一套配置用于连接一种特定的规范和框架:
- fis-plus:以smarty为模板引擎,以 mod 为模块化框架,适用于php后端渲染及部署运维方式的解决方案。
- yogurt:以swig为模板引擎,以 mod 为模块化框架,适用于nodejs后端渲染架构及部署运维方式的解决方案
- jello:以velocity为模板引擎,以 mod 为模块化框架,适用于java后端渲染架构及部署运维方式的解决方案
- pure:无后端渲染,使用前端模板,以 mod 为模块化框架,适用于纯前端,前后端严格分类的项目
- gois:go语言解决方案。
- spmx:纯前端方案,以seajs为模块化框架,一个示例项目,不完整,不要用于生产
- rsd:纯粹是为了展示静态资源md5问题的项目,把fis所有的语言插件都装上,可以在一个项目里混合多种语言进行开发,用资源内嵌实现打包,可以认为是最简易的fis,不适合大规模生产。
- scrat:以 scrat.js 为模块化框架,内含webapp、seo、olpm三种模式,其中:
- webapp是纯前端解决方案,依赖combo服务实现资源合并,适用于中型移动端单页面应用。
- seo是多页面模式,以swig为模板引擎,进行后端渲染,支持quickling(或者pjax),以combo服务合并资源,面向需要seo的单页面应用。
- olpm是运营后台模板开发模式,我们内部有一个CMS,可以用这种模式进行开发,本地预览,然后把代码打包上传到cms系统,作为专题模板使用。
总之,由于前端的开发环境、开发模式、部署方式实在是太五花八门了,有传统多页面模式,有移动端SPA模式,有CMS组件化拼装模式,不同的模式还可能会结合不同的后端语言(不要以为前端可以完全从后端剥离出来,不理解其中的原理,我可以单独写一篇文章说明),所以不可能有一种固定模式能解决所有问题,fis的设计就是把所有这些模式中的公共部分抽取出来形成一个基础工具,面对不同开发部署规范、不同模块化框架再做配置即可。
所有不同的前端开发模式,有一些相同的内在联系,那就是:资源定位,资源内嵌和资源依赖这三种语言能力。这三种语言能力为什么会成为所有开发模式的共性,这和前端这种特殊的GUI软件的安装和运行方式有关,后面再另开文章讲解吧,这里就不再解释了。
@hax
在我理解,yo属于脚手架工具吧,而我说的连接主要是指:
“在开发目录中的什么文件,将来要部署到什么集群上,框架中要做哪些处理” 这样的事情,也就是连接开发规范、部署规范和模块化框架的工作。三者是需要工具进行转换的。
要实现一个完整的模块化开发体系,我觉得需要有一个工具做这些事情:
- 对模块化资源进行扫描,获取资源依赖关系,生成依赖表,注入到模块化框架中供依赖管理、按需加载、合并请求等优化使用(资源依赖,用于连接框架)
- 接收一种配置,标记每种类型的文件会发布到什么目录或集群中,然后扫描所有文件中的资源定位标记,将其替换成部署路径(资源定位,用于连接开发和部署规范)
- 允许一些资源并不是通过模块化方式加载,而是直接内嵌到其他资源中使用,比如把图片以base64形式嵌入到css、js中(资源内嵌,非必须,但很有用)
以上三件事并不是yo的工作。下面图解一下这几件事:
1.所谓工具连接框架

连接框架就是工具把静态分析的依赖关系以某种形式传递给框架,用于框架在运行时的资源管理、加载及优化
2.所谓工具连接规范(连接的是开发规范和部署规范)
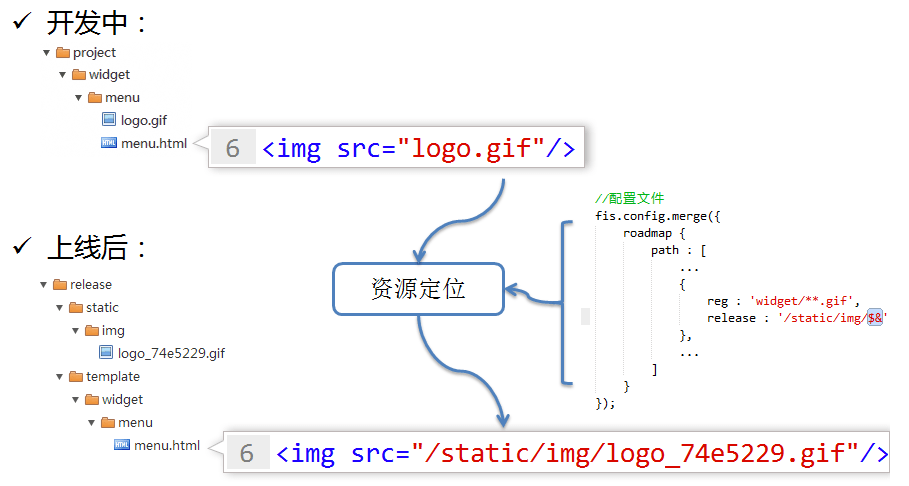
给一个配置文件,告诉工具,源码中的什么文件(用reg匹配)部署后会发布到哪里(release定义),这样,工具会把源码中所有关于这个资源的定位标记替换成部署路径。实现开发时使用工程路径,构建后使用部署路径的功能。这个功能可以保证资源的独立性,并且能对性能做优化(加md5戳)。独立性可以让资源无论是被合并、移位还是在其他地方加载都能正常运行。
@hax 很难, yo只是内置了一些grunt和脚手架, 它能做的也就是grunt能做的。
但fis实现的很多功能, 是很难用grunt这种task-base的工具去实现的, 譬如@fouber曾经举例过的资源URL替换。
@Rorchach
angularjs感觉对CRUD类产品比较合适,但百度的很多产品并非这种类型的,而且很多产品每天千万甚至几亿的访问量,如果放一个angularjs,不但每次研发部署后用户重新下载资源的性能大打折扣,而且很多业务的前端场景并不能很好的覆盖angular的功能,不能充分发挥它的价值,进一步浪费带宽。
所以,一般不太喜欢在页面上放一个几百K的,但只使用其中20%功能的前端框架,大家都恨不得量体裁衣。目前在业内能找到angular应用场景的项目,感觉大多集中在 ( pc端的 || 非核心功能的 || 后台管理系统类的 || 访问量小的 ) 页面上,我感觉百度也有团队在用,只是在一些我们没有很关注的某个页面的角落里而已。
原来是这样,技术放在大场景里要考虑这么多,这么细~ angular虽然是google的,但是现在google也没有几个产品在用,但是打算用angular替代一些主要业务。观察它的发展吧~
@hehongwei44
类似fis的专注管理前端静态资源的“软件”目前貌似没有同类,因为静态资源管理是一个结合开发框架、开发规范和部署规范的过程,并不是一个独立的软件完成的。如果提供了资源管理,绝大多数情况下要提供前/后端框架,并且定义开发规范,这是必然结果。
虽然没有独立软件,但类似的解决方案倒是有的,就是Rails的assets pipeline,相关资料:
英文版:http://guides.rubyonrails.org/asset_pipeline.html 中文版:http://guides.ruby-china.org/asset_pipeline.html
这些我在这篇blog中有提到的
grunt貌似也提供了相关的插件:http://segmentfault.com/blog/jiyinyiyong/1190000000442070
@hehongwei44
我在这里 https://github.com/fouber/blog/issues/5 列出了md5计算的过程,并且说明了为什么grunt这种task-based的调度控制非常难完美实现md5的原因,包括md5的递归计算、coffee/less等文件的编译之后资源定位等问题,下面也有一些讨论。
目前一直在用grunt工具处理前端资源的打包和压缩,遇到的问题确实如楼主所言的那样,停留在URL中添加版本控制。现在也在考虑MD5文件戳的方式,也一直在查找之类的工具,前段时间看到了grunt-usemin, 它对HTML的静态资源的处理很优雅,整合了常用的grunt的插件,这是典型的YO风格。今天看到rsd和fis的处理方式,确实是目前所期望的,:smiley_cat:
@fouber 请教一个问题:
业务场景:
使用AJAX获取打折商品列表配合 handlebars 渲染。如果模板中需要定位CDN部署资源,如何实现?(模板也是通过AJAX获取的,不使用CSS background )
模板内容:
<!-- http://www.domain.com/tpl/goods.tpl -->
{{#list}}
<div class="box">
<img src="/src/img/sale.jpg" alt="特价" class="sale">
{{name}} ¥{{price}}
</div>
{{#list}}
@nimojs
把图片变成模板变量,在js中定位资源,渲染模板的时候传进去
<!-- http://www.domain.com/tpl/goods.tpl -->
{{#list}}
<div class="box">
<img src="{{image}}" alt="特价" class="sale">
{{name}} ¥{{price}}
</div>
{{#list}}
var tpl = __inline('tpl.handlebars');
var data = {...};
data.image = __uri('/src/img/sale.jpg');
var html = tpl(data);
console.log(html);
感谢。 最近工作中遇到一些前端后端联调的问题,准备通过在前端的角度**“多做事”**解决问题。但没有实践过望 fouber 指点。
问题:
- 前端交付 HTML 给后端后因为 HTML 逻辑复杂导致后端无法按预期格式输出。(后端渲染后的页面和前端页面代码不一致)
- 为了方便修改页面需要分公用头底。后端不了解页面中 HTML 的细节,哪些公用哪些不公用。导致HTML转换为后端模板后无法按预期格式输出。
例如:<?php include "common/header.php"; ?>的header.php包含了<link>和<script>,而<link>和<script>在不同页面中href和src都不一样。
解决方案:
前端在前端开发环境(node)中编写兼容后端模板语法的模板,并模拟数据源进行渲染。先上示例:
数据源
{
list:[
{
title: '标题1',
name: '张三'
},
{
title: '标题2',
name: '李四'
}
],
listid:[
1,2,3,4,5,6,7
],
userid: false
}
模板文件
<!-- /example/include.html -->
<?php include "common/header.php"; ?>
content
<br><br>
{{#userid}}
您的用户ID是{{userid}}
{{/userid}}
{{^userid}}
<a href="/login/">请登录</a>
{{/userid}}
<br><br>
{{#list}}
<ul>
<li>{{title}}:{{name}}</li>
</ul>
{{/list}}
任务列表:
{{#listid}}
<input name="listid[]" type="checkbox" value="{{.}}" >{{.}}
{{/listid}}
<hr>
<!--{layout:example/sidebar.html}-->
<?php include "common/footer.php"; ?>
详细说明
前端开发环境是用 node 开发的服务器,拥有rewriteRule staticWriteReplace connect中间件 AJAX数据模拟等功能。这样前端可以模拟任何数据。而此时我只需使用 staticWriteReplace 这个功能。
// 静态资源替换 - Static write replace
staticWriteReplace: function (file, req, res) {
// file = {
// pathname: pathname ( example/index.html )
// dirname: dirname (example/)
// data: filedata ( <!DOCTYPE html> <html lang="en"> <head> ... </html> )
// }
// 实现 <?php include "common/header.php"; ?> 功能
file.data = file.data.replace(/<\?php (include|require) ["]([^"]+)"; \?>/g, function () {
var sPath = arguments[2],
fs = require('fs');
if (!/\.php$/.test(sPath)) {
sPath = sPath + '.php';
}
var sFileData = fs.readFileSync(__dirname + file.dirname + sPath, 'utf-8', function (err, data) {
return data;
})
return sFileData
})
// 实现<!--{layout:example/sidebar.html}-->
// 省略
// 实现 Mustache 语法的模板引擎
if (file.pathname === '/example/include.html'){
var Mustache = require('./_nodeajax/lib/mustache');
file.data = Mustache.render(file.data,{
list:[
{
title: '标题1',
name: '张三'
},
{
title: '标题2',
name: '李四'
}
],
listid:[
1,2,3,4,5,6,7
],
userid: false
})
}
}
此处使用的是 Mustache ,最终会使用 smarty 作为前端环境和后端框架的模板引擎。利用 https://www.npmjs.com/package/nsmarty 让node 只支持 smarty 。
此时 http://127.0.0.1:18081/example/include.html 显示效果如下:

前端开发工作完成后直接交付模板而不是交付 HTML ,后端同事只需按照数据源的说明文档提供数据
**总结:**前端开发工作包括页面模板引擎渲染的开发工作,并利用开发环境和约定使前端开发出来的模板可以直接被后端框架使用。(前端通过开发环境模拟数据源用 类似 nsmarty 的库来兼容 smarty)此时后端工程师只需要提供真实数据支持。
**分析:**以 MVC 来看,后端在 View 的工作只是按照前端HTML输出数据,直接让前端控制 View 的输出形式让后端在 C 层面提供真实数据源的输出。
**我的疑惑:**虽然我感觉前端控制 View 的渲染和 AJAX 结合handlebars 做渲染类似。从来没有试过前端控制 V 的数据模拟和渲染,担心交付代码时因为前端对后端的不了解导致变成多此一举。
小公司,没开发体系和前人建议,也没能力做彻底的node前后端分离。想结合公司环境想做一些增加工作效率的事。望 fouber 指点