spaCy
 spaCy copied to clipboard
spaCy copied to clipboard
WIP: enable fuzzy text matching in Matcher
Description
work in progress:
- use Levenshtein distance (polyleven implementation) to allow fuzzy matching of specific tokens in Matcher.
- FUZZY1, FUZZY2, ... FUZZY5 operators specify max string edit distance to allow a match.
- operators can apply to single tokens or sets, e.g.
{"LOWER": {"FUZZY3: "string"}}or{"LOWER": {"FUZZY2": {"IN": ["string1", "string2"]}}}
Types of change
enhancement
Checklist
- [x] I confirm that I have the right to submit this contribution under the project's MIT license.
- [x] I ran the tests, and all new and existing tests passed.
- [ ] My changes don't require a change to the documentation, or if they do, I've added all required information.
any Cython advice on how to avoid with gil at https://github.com/explosion/spaCy/pull/11359/files#diff-63f1a25e13e4c412a4decf97e30bf2157f1a0d800efb1d0b25679e1991a8b804R697 ?
Just a few initial notes:
-
I think there are a lot of users who would like to have something like this, so this is a nice idea!
-
we're pretty conservative about adding new dependencies to
spacy, so we'll have to seriously consider whether we want to addrapidfuzz -
this feels like it ought to be an extra operator (similar to
REGEX) rather than being aMatchersetting that's applied to a hard-coded subset of attributespattern = [{"ORTH": {"FUZZY": "word"}}]Then you could apply it to any attributes that you want including custom extensions. What's trickier with the operator is a parameter for fuzziness.
Thanks @adrianeboyd. This plugin uses the notation you suggest https://spacy.io/universe/project/spaczz but in my evaluation it is much too slow to be practical, even with minimal use of the operator. Therefore I was trying for a more direct integration with the underlying rapidfuzz package.
Agreed that a user-specified list of attributes would be better than a hard-coded list, but I'd like to be able to specify this on Matcher init rather than on individual tokens. My use case is a large existing set of patterns which I'd like to optionally apply with fuzzy matching, without having to modify every pattern (but perhaps this could be done in a pattern pre-processing stage).
Have you tried implementing FUZZY within spacy's Matcher similar to REGEX? I think that spazz has some of its own python-only matcher implementation, so it's not just the extra operator that's causing the difference.
If you want to get a general idea of the speed difference just for the operator, you can try comparing {"ORTH": "the"} to {"ORTH": {"REGEX": "^the$"}}.
added a FUZZY attribute, as suggested (and as compatible with spaczz), but using a fixed fuzzy threshold value specified on init.
also added a parameter to specify a list of attributes on init, to be treated as fuzzy in all patterns, e.g. Matcher(en_vocab, fuzzy=85, fuzzy_attrs=["ORTH", "LOWER"]).
TODO: handle extension attributes TODO: handle values in sets
We think this is a good idea and we discussed a bit internally how we'd like to support it:
- we would prefer not to add
rapidfuzzas a dependency, but would instead prefer to directly include one edit distance / similarity implementation in spacy (possibly fromrapidfuzz, or reimplemented ourselves if that makes more sense) - we don't think that a top-level
fuzzysetting forMatcherorEntityRulermakes sense because the appropriate fuzziness often depends so much on the exact strings / pattern / task and different patterns in the sameMatcherwould need different levels of fuzziness - we're still not quite sure how to implement a fuzziness parameter for the operator; my initial clunky idea would be to support a small range of hard-coded operators like
FUZZY75,FUZZY80, etc. but we're still thinking about the options/details here (ideas welcome!) - it's possible there would be no way to support this in combination with set operators
we would prefer not to add rapidfuzz as a dependency, but would instead prefer to directly include one edit distance / similarity implementation in spacy (possibly from rapidfuzz, or reimplemented ourselves if that makes more sense)
You can directly build against the C++ library https://github.com/maxbachmann/rapidfuzz-cpp.
- it's possible there would be no way to support this in combination with set operators
@adrianeboyd I just spent some time adding support for set operators. see https://github.com/explosion/spaCy/pull/11359/files#diff-d7740e9e8c9929c0b0e8e962c46a22e09263ef4891faceaa15415b2be94a5837R221-R263 but there probably isn't any way to use different fuzziness parameters for different set members.
- we're still not quite sure how to implement a fuzziness parameter for the operator; my initial clunky idea would be to support a small range of hard-coded operators like
FUZZY75,FUZZY80, etc. but we're still thinking about the options/details here (ideas welcome!)
FUZZY1, FUZZY2, ... FUZZYN where N is the allowed Levenshtein string edit distance might be simpler than a 0-100 scale?
FUZZY1, FUZZY2, ... FUZZYNwhereNis the allowed Levenshtein string edit distance might be simpler than a 0-100 scale?
I like that idea! It is definitely concrete and easy for users to understand.
@adrianeboyd a small, fast, MIT-licensed implementation of Levenshtein distance here https://github.com/roy-ht/editdistance Would this be acceptable to either import or copy into spaCy?
a small, fast, MIT-licensed implementation of Levenshtein distance here https://github.com/roy-ht/editdistance Would this be acceptable to either import or copy into spaCy?
What are the expected text lengths for the compared strings? editdistance is a pretty small implementation, but not very fast for longer sequences.
For short strings it is slower, but only by about 4-5x:
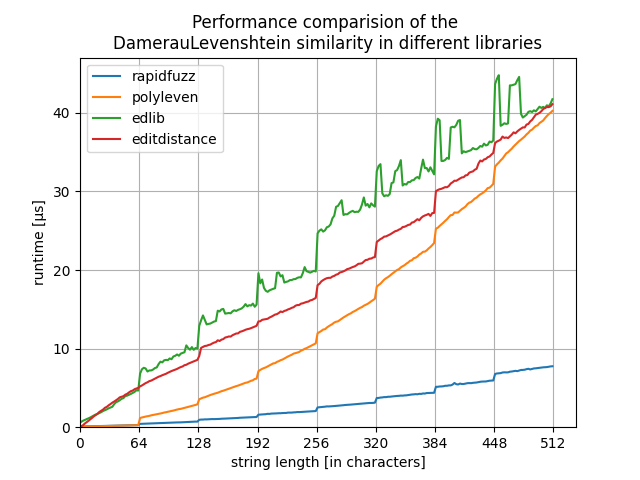
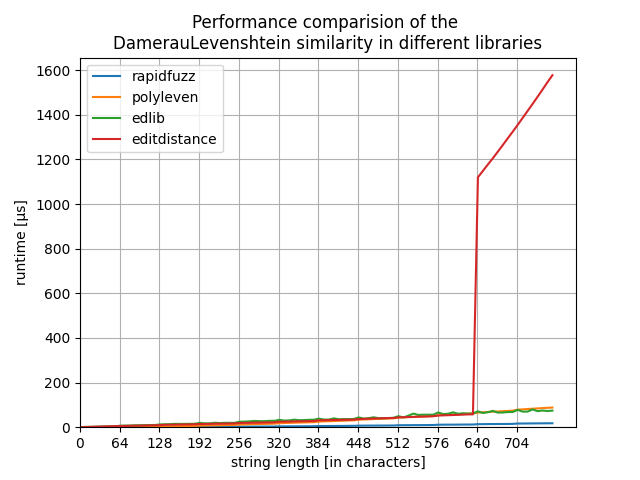
For sequence lengths > 640 characters editdistance becomes unusable:
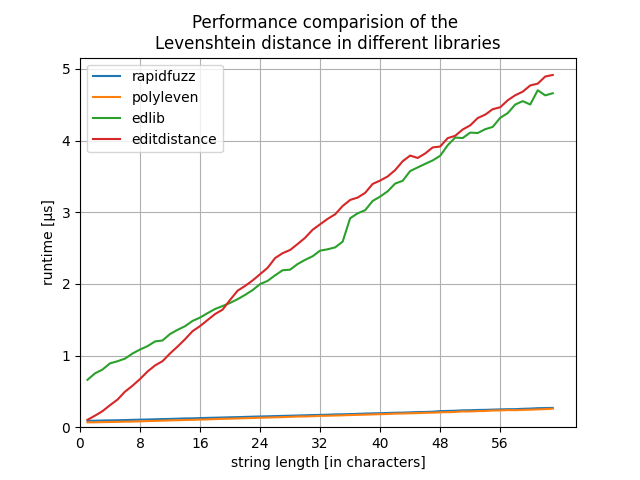
RapidFuzz provides a single include file as well https://github.com/maxbachmann/rapidfuzz-cpp/blob/main/extras/rapidfuzz_amalgamated.hpp. It is a lot faster, but a lot more code as well (since it has more specialised implementations and supports more string metrics)
Edit: the graphs have the wrong title. They do not show Damerau Levenshtein but normal Levenshtein distance.
What are the expected text lengths for the compared strings?
comparisons in the current Matcher implementation are limited to single words. my use case is to apply sets of manually authored token patterns to inputs which may have spelling errors/variants, ideally with minimal performance impact.
spaCy also has a PhraseMatcher which is typically used for things like lists of names, which can be multiword but rarely more than 2 or 3 words, but I haven't looking into fuzzy matching for this.
My general recommendation is:
- for short sequences (< 64 chars) rapidfuzz / polyleven
- mid long sequences rapidfuzz
- very long strings (> 50k characters) rapidfuzz / edlib
I am not aware of any case in which editdistance performs well.
Since you have mainly short strings + want a simple implementation I would personally take the implementation from polyleven and just throw out all of the Cpython parts: https://github.com/fujimotos/polyleven/blob/master/polyleven.c which would be around 300 lines of code.
We just merged a vendored version of polyleven into master (#11418), so if you merge in the changes from master you can do this without modifying the dependencies.
I think the basic FUZZY options look fine. I am not sure we want to add the changes related to set operators (we also don't do this for REGEX, which is similar).
patterns using the positive set operator {'IN': [set]} can be split out into separate patterns for each set member to add FUZZY operators, but this can cause an explosion of patterns when expanding multiple sets. (automatically expanding sets to insert FUZZY operators in 1600 patterns results in over 165k patterns, which makes fuzzy matching unusable in this case.)
however, patterns using the negative set operator {'NOT_IN': [set]} cannot be written as separate patterns with FUZZY operators because the intending matching logic applies within the set, not across patterns.
the changes I made to set operators could be extended to also apply to REGEX if desired.
this would allow patterns like {'LOWER': {'REGEX': {'IN': [regex1, regex2, regex3]}}} which might be useful for pattern readability.
another option to consider is a single FUZZY operator with a distance restriction implemented as a Matcher function which can be customized by users.
a default distance based on token length (like min(5, len(token) - 2))has been working well for my purposes, and restrictions like is_oov could also be implemented there rather than being hardcoded.
@adrianeboyd the simple FUZZY operator with a default distance limit based on token length implemented at https://github.com/explosion/spaCy/pull/11359/files#diff-63f1a25e13e4c412a4decf97e30bf2157f1a0d800efb1d0b25679e1991a8b804R208-R218 has been working well for me. do you have any suggestions on the best way to allow users to customize this function?
using fuzzy matching inside sets is essential for my uses. I have extended this for the regex operator for consistency.
This is coming along nicely! Do you mind if I push directly to this branch?
Do you mind if I push directly to this branch?
of course not, please go ahead!
I think for speed reasons it would be better to keep one sensible general-purpose fuzzy_match method in matcher.pyx. I haven't done any careful benchmarking, but I think that a cpdef function will be faster to call from within the matcher? (And I'm not really sure we want monkey patching as the recommended way to modify something like this?)
I also noticed that fuzzy_match doesn't return the expected results for short strings like "a"/"a" or "a"/"ab" because it ends up with thresholds of 0 or below. I think that it might make sense to use a default value of -1 for distance and then also pass distance to levenshtein so it can optimize its calculations? I think that levenshtein already checks the string lengths so you don't need to modify distance if it's provided?
Thanks @adrianeboyd. I moved the function back, clarified the logic, and added some unit tests.
I had been experimenting with function overrides to add is_oov tests or to call a spellchecker and only attempt fuzzy matching on unrecognized words. Any suggestions on how to allow customization of the function without monkey patching?
fuzzy_match as a kwarg is kind of clunky, but better than monkey-patching. The kwarg name and the internal API (especially for the predicates) is still not 100% decided.
I originally thought it made sense to have a symmetric fuzzy_match method and we've discussed a number of more complicated options internally, but for the provided default I'd mainly like something that's relatively easy to explain to users in the docs. My current idea is something like this, what do you think?
cpdef bint _default_fuzzy_match(input_text: str, pattern_text: str, fuzzy: int):
if fuzzy >= 0:
max_edits = fuzzy
else:
# allow at least one edit and up to 20% of the pattern string length
max_edits = ceil(0.2 * len(pattern_text))
return levenshtein(input_text, pattern_text, max_edits) <= max_edits
You could have the exception for no edits to single-char strings, but I feel like it's not worth having a special case.
The reason for not having it be symmetric is primarily long tokens the text (usually URLs) vs. shorter tokens in the patterns.
The following direct test cases would change (plus a few of the Matcher tests, which I haven't included here):
FAILED spacy/tests/matcher/test_levenshtein.py::test_default_fuzzy_match[a-ab-0-False] - AssertionError: assert True == False
FAILED spacy/tests/matcher/test_levenshtein.py::test_default_fuzzy_match[abc-cde-4-False] - AssertionError: assert True == False
FAILED spacy/tests/matcher/test_levenshtein.py::test_default_fuzzy_match[abcdef-cdefgh--1-True] - AssertionError: assert False == True
FAILED spacy/tests/matcher/test_levenshtein.py::test_default_fuzzy_match[abcdefgh-cdefghijk--1-True] - AssertionError: assert False == True
I'm not sure I like fuzzy_compare, but I think using "fuzzy" and "match" for too many different things gets confusing. In effect it's more like __eq__, but I can't think of any names with eq that don't seem more confusing to me.
Hi @adrianeboyd . Thanks for your updates. Sorry for not coordinating on the EntityRuler changes, but I needed to make changes to try out your proposed simpler algorithm in my application.
I have a few issues with the simpler algorithm, and I think it makes things less clear.
The explicit fuzzyN case still needs to be dynamically restricted by min token length, otherwise fuzzyN will allow completely different tokens if len(token) <= N, e.g. fuzzy_compare('and', 'the', 3) == True. Some token overlap should be required (possibly apart from single character tokens) and so max_edits always needs to consider token length.
And I think the default case (with implicit N) is now too restrictive. It doesn't allow transpositions if len(token) <= 5, so cases like htis-this, iwth-with, htem-them now all fail.
I strongly think FUZZY3 should be exactly 3 edits or it is way too confusing to explain to users.
The fact that the default case is too restrictive on short strings is a good point, that can definitely be adjusted.
I strongly think
FUZZY3should be exactly 3 edits or it is way too confusing to explain to users.
even when 3 >= len(input_text)? allowing fuzzy_compare to match anything seems hard to explain and not very useful.
with sets, I have cases like {'LOWER': {'FUZZY3': {'IN': ['wonderful', 'awesome', 'wow']} and having N dynamically restrict for inputs <=N avoids an explosion of rules.
I strongly think
FUZZY3should be exactly 3 edits or it is way too confusing to explain to users.even when 3 >= len(input_text)? allowing fuzzy_compare to match anything seems hard to explain and not very useful.
Yes, even when len(input_text) <= 3. I think "allows up to 3 edits" is much easier to explain than anything conditional on the lengths or requiring a minimum amount of overlap.
with sets, I have cases like
{'LOWER': {'FUZZY3': {'IN': ['wonderful', 'awesome', 'wow']}and having N dynamically restrict for inputs <=N avoids an explosion of rules.
What is the argument against using FUZZY instead of FUZZY3 for cases like this?