dolt
 dolt copied to clipboard
dolt copied to clipboard
Sporadic slowness in GCS read replica
Customer observed very significant added latency when querying a read replica which used a GCS bucket as its remote. I was able to reproduce this problem, but only intermittently. When it happened, the added latency was very significant, on the order of 8+ seconds. Latency was present even when the replica was caught up. But after getting a profiler attached the problem vanished.
This needs additional investigation. Current hypothesis is that tail latency on GCS is much higher than anticipated, and might be triggered by recent writes to files like the manifest.
Experimental setup:
% dolt config --list --global | grep sqlserver
sqlserver.global.dolt_replicate_all_heads = 1
sqlserver.global.dolt_replication_remote_url_template = gs://zachmu-test/dolt-remotes/{database}
sqlserver.global.dolt_read_replica_remote = origin
Separately, I pushed a database to the remote indicated. Then I started a server with dolt sql-server and timed MySQL client reads against it:
mysql -h 127.0.0.1 -P3306 -uroot db10 -e "select * from t1" 0.00s user 0.02s system 0% cpu 10.377 total
mysql -h 127.0.0.1 -P3306 -uroot db10 -e "select * from t1" 0.00s user 0.02s system 0% cpu 8.021 total
Outside these latency spikes, latency added by replication was much smaller, <200 ms at most
mysql -h 127.0.0.1 -P3306 -uroot db10 -e "select * from t1" 0.00s user 0.02s system 6% cpu 0.230 total
To further debug this problem: instrument the code to measure RPC latency to GCS, the run a primary / replica pair, with the primary doing periodic pushes and the replica doing periodic reads. Use this to establish a latency distribution for replica reads.
Same customer reports consistent slowness on a read replica backed by GCS. Database in question has 1200 branches.
Configuration:
| Variable_name | Value |
+--------------------------------------+--------+
| dolt_allow_commit_conflicts | 0 |
| dolt_async_replication | 0 |
| dolt_force_transaction_commit | 0 |
| dolt_read_replica_force_pull | 0 |
| dolt_read_replica_remote | origin |
| dolt_replicate_all_heads | 1 |
| dolt_replicate_heads | |
| dolt_replicate_to_remote | |
| dolt_replication_remote_url_template | |
| dolt_skip_replication_errors | 0 |
| dolt_transaction_commit | 0 |
| dolt_transactions_disabled | 0 |
+--------------------------------------+--------+
I ran a quick remotesrv repro looping over:
- make
$stepbranches (same commit asmain) - run
time dolt sql -q "select * from dolt_branches where name = 'branch$((($i+1)*$step))'"
We average the latency of 10 queries for a remote with 100, 200, ...1000 branches:
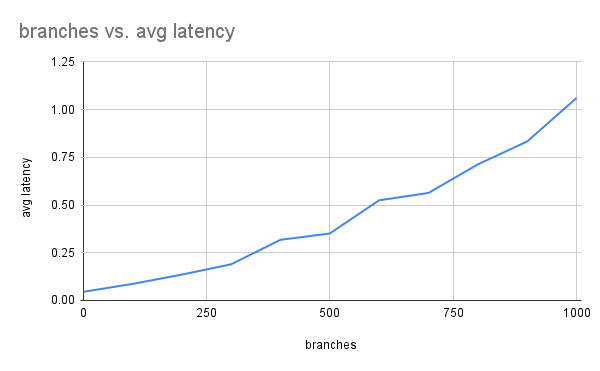
-- 100 branches
user 0m0.088s
user 0m0.085s
user 0m0.086s
user 0m0.095s
user 0m0.088s
user 0m0.084s
user 0m0.086s
user 0m0.084s
user 0m0.085s
user 0m0.084s
-- 200 branches
user 0m0.134s
user 0m0.142s
user 0m0.134s
user 0m0.133s
user 0m0.140s
user 0m0.138s
user 0m0.134s
user 0m0.134s
user 0m0.133s
user 0m0.131s
-- 300 branches
user 0m0.202s
user 0m0.188s
user 0m0.186s
user 0m0.187s
user 0m0.187s
user 0m0.189s
user 0m0.192s
user 0m0.186s
user 0m0.190s
user 0m0.187s
...
-- 900 branches
user 0m0.828s
user 0m0.830s
user 0m0.853s
user 0m0.824s
user 0m0.840s
user 0m0.831s
user 0m0.848s
user 0m0.841s
user 0m0.840s
user 0m0.796s
-- 1000 branches
user 0m1.385s
user 0m1.164s
user 0m0.970s
user 0m0.980s
user 0m0.961s
user 0m1.018s
user 0m0.967s
user 0m0.975s
user 0m1.113s
user 0m1.074s
I've collected evidence suggesting 1) we execute a number of remote fetches proportional to the number of branches, 2) for static replicas with 1000 branches on a local remote server, we reduce read latency by 8-10x by batching those fetches. Working on a PR now.
This PR should substantially address these latency problems, now consistently <100ms when the replica is already caught up.
https://github.com/dolthub/dolt/pull/5005