flextable
 flextable copied to clipboard
flextable copied to clipboard
Word output: Citations via bookdown text-references do not work
Citations inside flextables do not work if using the usual pandoc syntax, e.g., [@citekey1].
They do work when using bookdown "text-references", i.e., defining
(ref:citekey1) [@citekey1]
and using (ref:citekey1) inside a flextable.
However, while this works as expected for the output formats pdf (via latex) and html, it does not for word/docx output.
I wonder whether flextable could be fixed to ensure correct citation formatting using bookdown "text-references" for word output as well.
(Since this most likely will come up: The existing ftExtra citation hack is not quite satisfactory. First, it requires creating an extra .bib file, which is inconvenient if all other biblio data are pulled via other methods, e.g., from Zotero; second, disambiguation fails if citing, say, one Eurostat item from 2021 in one flextable, and a different Eurostat item from 2021 in a second flextable; and third, as per the ftExtra docs, in numerical styles one has to "manually offset the number", which, again, is inconvenient and error-prone. It’d be much preferred to let pandoc itself do the formatting w.r.t. disambiguation and numbering throughout the document.)
MWE (all output shown below was knit from the RStudio [2022.02.1 Build 461] GUI):
---
output:
bookdown::pdf_document2:
latex_engine: xelatex
bookdown::html_document2: default
bookdown::word_document2: default
toc: FALSE
references:
- id: eurostat
author: Eurostat
issued: 2021
title: 'Database - Employment and unemployment (LFS)'
type: report
URL: 'https://ec.europa.eu/eurostat/web/lfs/data/database'
---
```{r setup, include=FALSE}
knitr::opts_chunk$set(echo=FALSE, message=FALSE, warning=FALSE)
library(tidyverse)
library(flextable)
```
Some text blah blah [@eurostat, 88-99].
(ref:eurostat) Data: @eurostat [88-99]
```{r test}
tribble(
~ Name, ~ Source,
"John Smith", "@eurostat",
"Jane Doe", "(ref:eurostat)",
) %>%
flextable() %>%
set_caption("A caption. (ref:eurostat)") %>%
add_footer_lines(values = "(ref:eurostat)") %>%
footnote(value = as_paragraph("(ref:eurostat)"), i = 1, j = 1) %>%
autofit()
```
# References {-}
html output:

pdf output (via latex):
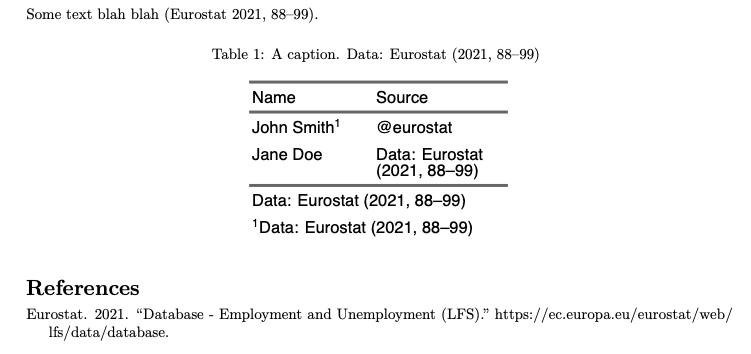
word output:

> sessionInfo()
R version 4.1.3 (2022-03-10)
Platform: x86_64-apple-darwin17.0 (64-bit)
Running under: macOS Big Sur 11.6.5
Matrix products: default
LAPACK: /Library/Frameworks/R.framework/Versions/4.1/Resources/lib/libRlapack.dylib
locale:
[1] en_IE.UTF-8/en_IE.UTF-8/en_IE.UTF-8/C/en_IE.UTF-8/en_IE.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
loaded via a namespace (and not attached):
[1] bookdown_0.25 Rcpp_1.0.8.3 digest_0.6.29 R6_2.5.1 evaluate_0.15 zip_2.2.0
[7] rlang_1.0.2 gdtools_0.2.4 cli_3.2.0 uuid_1.0-4 data.table_1.14.2 xml2_1.3.3
[13] flextable_0.7.0 rmarkdown_2.13 tools_4.1.3 officer_0.4.2 xfun_0.30 yaml_2.3.5
[19] fastmap_1.1.0 compiler_4.1.3 systemfonts_1.0.4 base64enc_0.1-3 htmltools_0.5.2 knitr_1.38
This is hard to do as it is a pandoc feature and flextable don't generate markdown. I don't know if it is possible for now. I will have a try but it will take time...
This is not possible. Citations can be resolved by pandoc but flextable does not produce markdown code but HTML raw code or latex or OOXML
I am closing the issue as it will probably never be possible in flextable
Maybe what @njbart wants is ftExtra?
https://ftextra.atusy.net/articles/format_columns#citations
@davidgohel - Many thanks for looking into this nonetheless.
@atusy - Thanks, but I'm afraid this is not quite what I was after. From my OP above:
(Since this most likely will come up: The existing ftExtra citation hack is not quite satisfactory. First, it requires creating an extra .bib file, which is inconvenient if all other biblio data are pulled via other methods, e.g., from Zotero; second, disambiguation fails if citing, say, one Eurostat item from 2021 in one flextable, and a different Eurostat item from 2021 in a second flextable; and third, as per the ftExtra docs, in numerical styles one has to "manually offset the number", which, again, is inconvenient and error-prone. It’d be much preferred to let pandoc itself do the formatting w.r.t. disambiguation and numbering throughout the document.)
oops, I missed that you've already mentioned ftExtra. Sorry... And yeah, it's hacky... quite hacky...