easy-rl
 easy-rl copied to clipboard
easy-rl copied to clipboard
/chapter2/chapter2
Prediction and Control那边例子Gridworld给的背景是不是有问题,由给的条件一开始理解不了,搜了一下Gridworld,好像条件不大一样
Prediction and Control那边例子Gridworld给的背景是不是有问题,由给的条件一开始理解不了,搜了一下Gridworld,好像条件不大一样
感谢您的反馈,背景应该是没有问题的,Gridworld 有很多例子,笔记中列出的只是其中一个例子。
在 FrozenLake 演示中,Policy-Iteration 在第 5 步收敛,而 Value-iteration 在迭代 1373 收敛。为什么前者比后者快得多?(In the FrozenLake demo , Policy-Iteration converged at step 5 whereas Value-iteration converged at iteration 1373. Why former is much faster than the latter?)
在 FrozenLake 演示中,Policy-Iteration 在第 5 步收敛,而 Value-iteration 在迭代 1373 收敛。为什么前者比后者快得多?(In the FrozenLake demo , Policy-Iteration converged at step 5 whereas Value-iteration converged at iteration 1373. Why former is much faster than the latter?)
首先可以肯定的是,一般策略迭代(PI)比值迭代(VI)快得多。个人认为通俗的理解就是,PI每次是在上一次迭代后的策略基础上进行优化的,而VI是一次性的从一开始一直迭代到最优策略,比如在一个大地图上找东西,PI每次学到一点就会运用之前学到的东西也就是以非线性的方式扩大视野再进一步找,而VI则是不断的找最优点(即每次找max的点),每次都是固定的视野范围,需要的迭代次数也更多,也可以参考stackoverflow的回答
@JohnJim0816
在 FrozenLake 演示中,Policy-Iteration 在第 5 步收敛,而 Value-iteration 在迭代 1373 收敛。为什么前者比后者快得多?(In the FrozenLake demo , Policy-Iteration converged at step 5 whereas Value-iteration converged at iteration 1373. Why former is much faster than the latter?)
首先可以肯定的是,一般策略迭代(PI)比值迭代(VI)快得多。个人认为通俗的理解就是,PI每次是在上一次迭代后的策略基础上进行优化的,而VI是一次性的从一开始一直迭代到最优策略,比如在一个大地图上找东西,PI每次学到一点就会运用之前学到的东西也就是以非线性的方式扩大视野再进一步找,而VI则是不断的找最优点(即每次找max的点),每次都是固定的视野范围,需要的迭代次数也更多,也可以参考stackoverflow的回答
感谢精彩的回答!


@qiwang067 解答见下图:
我有一个小小的疑问~ RL问题都需要建模为MDP吗?他们俩是什么关系呀?s,a,r,p是属于MDP而非RL的对吗?
谢谢博主的回答~
Policy evaluation的例子1表述似乎有一点问题,"现在的奖励函数应该是关于动作以及状态两个变量的一个函数。但我们这里规定,不管你采取什么动作,只要到达状态$$s_1$$,就有 5 的奖励。只要你到达状态 $s_7$了,就有 10 的奖励,中间没有任何奖励。"
之前笔记中对reward的介绍是$R(s,a)$,只是当前状态s的函数而非$$R(s,s',a)$$即s和$s'$的函数。
而且,按照后面的计算结果和$R$向量的一维性来理解,更符合结果的表述是“只有当前处于状态$s_1$,就有5的奖励,只要当前处于$s_7$,就有10的奖励,与采取任何动作无关”。
不知道我理解的错了没有?
Policy evaluation的例子1表述似乎有一点问题,"现在的奖励函数应该是关于动作以及状态两个变量的一个函数。但我们这里规定,不管你采取什么动作,只要到达状态s1s_1,就有 5 的奖励。只要你到达状态 s7s_7了,就有 10 的奖励,中间没有任何奖励。"
之前笔记中对reward的介绍是R(s,a)R(s,a),只是当前状态s的函数而非R(s,s′,a)R(s,s',a)即s和s′s'的函数。
而且,按照后面的计算结果和RR向量的一维性来理解,更符合结果的表述是“只有当前处于状态s1s_1,就有5的奖励,只要当前处于s7s_7,就有10的奖励,与采取任何动作无关”。
不知道我理解的错了没有?
Hi,感谢您的反馈,回复见下图:

策略迭代
初始化一个 policy 和 value 用 policy evaluation 方式迭代至 value 收敛 用现在的 policy 和 收敛的 value 去倒推每个 q(s, a) 的值,每个 state 取最大 q 值最大的那个 action 作为 policy 不停重复1~3直到 policy 没有变化
价值迭代
不需要 policy 的参与,初始化 value 每次迭代的 value 就是用即时的奖励加上当前状态执行某一个 action 后的状态的最大 value 最后就看每一个 state 能取最大 value 的 action 作为最终的 policy
policy 生成过程区别
价值迭代过程中没有初始化一个 policy 参与,通过迭代后是最后才生成 策略迭代是一开始就不停迭代提升一个 policy 直到收敛
博主我有理解正确吗?
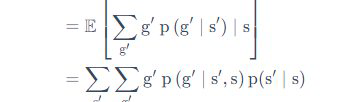 中的
中的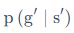 为什么多了个s不是很理解
为什么多了个s不是很理解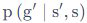 想知道是怎么变换的
想知道是怎么变换的
感谢博主的教程,我收获很多,只是我还有两个问题: policy iteration 每进行一次 sweep 就使用贪心算法更新一次 policy 就是 value iteration 吗,因为算出来的结果是一样的 一次 policy evaluation 是指更新到价值收敛还是一次 sweep 呀
sweep 词语是我在博主推荐可视化网站看到的就是 'Policy Evaluation (one sweep) '按钮 https://cs.stanford.edu/people/karpathy/reinforcejs/gridworld_dp.html
请问纸质书第62页的价值迭代算法的第(3)步公式是否有误,以我的理解应该在argmax后有一个方括号,且V的下标应该是H,在电子版同一个章节并没有看到对应的内容。如果我的理解有问题,恳请博主指点一下迷津,对这章的数学部分确实有点一知半解的感觉。
请问纸质书第62页的价值迭代算法的第(3)步公式是否有误,以我的理解应该在argmax后有一个方括号,且V的下标应该是H,在电子版同一个章节并没有看到对应的内容。如果我的理解有问题,恳请博主指点一下迷津,对这章的数学部分确实有点一知半解的感觉。
感谢您的反馈,arg max 后是应该有一个方括号,V 的下标应该是 H+1,具体细节见勘误: https://datawhalechina.github.io/easy-rl/#/errata
您好,Policy Evaluation(Prediction)中的QA里的迭代公式好像漏了\pi的累加?和前面给的公式不同,不知道是不是有问题?
您好,Policy Evaluation(Prediction)中的QA里的迭代公式好像漏了\pi的累加?和前面给的公式不同,不知道是不是有问题?
@Tricol-Viola 感谢您的反馈,您所提到的迭代公式是状态价值函数 v 的迭代公式,前面给的公式是 Q 函数的迭代公式,这两者不同 : )

感谢博主的教程,我收获很多,只是我还有两个问题: policy iteration 每进行一次 sweep 就使用贪心算法更新一次 policy 就是 value iteration 吗,因为算出来的结果是一样的 一次 policy evaluation 是指更新到价值收敛还是一次 sweep 呀
sweep 词语是我在博主推荐可视化网站看到的就是 'Policy Evaluation (one sweep) '按钮 https://cs.stanford.edu/people/karpathy/reinforcejs/gridworld_dp.html
价值迭代做的工作类似于价值的反向传播,每次迭代做一步传播,所以中间过程的策略和价值函数是没有意义的。而策略迭代的每一次迭代的结果都是有意义的,都是一个完整的策略。 一次策略迭代就是一次 sweep。

作者好,第二章中好多公式无法正常显示。
@guoruiqi01 感谢您的反馈,公式解析的链接出问题了,我们会尽快修复这个问题,建议您先看 pdf 版: https://github.com/datawhalechina/easy-rl/releases